Clear Sky Science · he
שיטות עבודה מומלצות וכלים ב‑R וב‑Python לעיבוד סטטיסטי ולהמחשה של נתוני ליפידומיקה ומטבולומיקה
מדוע חשוב להפוך נתוני מעבדה לתמונות ברורות
מכשירים מודרניים מסוגלים היום למדוד אלפי מולקולות זעירות — ליפידים ומטבוליטים אחרים — בטיפה בודדת של דם או רקמה. המדידות הללו מחזיקות רמזים על סיכוני מחלות, תגובות לטיפולים ואופן התגובה של גופנו לתזונה או להזדקנות. אך התוצר הגולמי אינו תשובה מוכנה: זהו טבלה עצומה של מספרים שיש לנקות, לנתח ולהפוך לתמונות ברורות ומובנות. מאמר זה מסביר כיצד חוקרים יכולים להשתמש בשתי שפות תכנות פופולריות, R ו‑Python, כדי לבצע זאת באופן אמין, שקוף ובגרפיקה באיכות פרסומית.
ממדידות כימיות לטבלאות נתונים מורכבות
בליפידומיקה ובמטבולומיקה, ספקטרומטריית מסה וכרומטוגרפיה מייצרות מערכי נתונים גדולים שבהם כל שורה היא דגימה וכל עמודה היא מולקולה. טבלאות אלה רחוקות מלהיות דוגמאות מסודרות מהספרים — הן מכילות ערכים חסרים, תצפיות קיצוניות והתפלגויות נטויות שבהן כמה מולקולות מראות רמות גבוהות מאוד. ריכוזים יכולים להשתרע על פני סדרי גודל רבים, ועלולים להיות מושפעים מגיל, מין, תזונה, תרופות, קצבי יום וטכניות כגון סטייה במכשיר או השפעות אצווה. קבוצות מומחים בינלאומיות פרסמו קווים מנחים לאחידות באיסוף, בעיבוד ובהדווח על דגימות, אך אפילו עם פרקטיקה מעבדתית טובה דרוש עיבוד סטטיסטי מוקפד כדי לחלץ אותות ביולוגיים אמיתיים מהרעש הזה.
ניקוי והכנת המספרים
לפני שכל השוואה בין קבוצות בריאות לחולות תהיה בעלת משמעות, יש להכין את הנתונים. הסקירה מתארת כיצד נוצרים ערכים חסרים — כתוצאה מתקלות אקראיות, מגבלות מכשיר או מהפרעות אות — ומסבירה מתי ניתן להתעלם מהם בבטחה, מתי יש למדוד מחדש וכיצד ניתן לאמדם באופן סביר (אימפוטציה) בשיטות כגון k‑nearest neighbors, יערות אקראיים או החלפה בערכים נמוכים פשוטים. לאחר מכן המחברים מסכמים אסטרטגיות נרמול שמפחיתות שונות בלתי רצויה, למשל תיקון השפעות אצווה באמצעות דגימות בקרת איכות או התאמה להבדלים בכמות הדגימה. הם דנים גם בהמרות כמו לוגריתמים — שמרגיעים זנבות ארוכים בצד הימני של ההתפלגות — ובשיטות סקלינג שמציבות את כל המולקולות על בסיס השוואתי כדי שמרכיבים בעלי שונות גבוהה לא ישלטו בניתוחים הבאים. 
מבחנים סטטיסטיים וסיפורים ויזואליים
לאחר שהנתונים הוכנו כראוי, מופעל טווח כלים סטטיסטיים. עבור מולקולות בודדות, חוקרים יכולים לחשב שינויים יחסים (fold change) ולהשתמש בבחינות קלאסיות כגון בדיקת t או מקבילותיה הבלתי־פרמטריות (כגון בדיקת Mann–Whitney) כדי לבדוק האם הרמות שונות בין קבוצות. להשוואות הכוללות מספר קבוצות מוצגות שיטות כגון ANOVA או בדיקת Kruskal–Wallis, בליווי נהלי post hoc לאיתור הקבוצות השונות זו מזו. כוחה של בדיקה סטטיסטית נפתח כאשר תוצאותיה מוצגות בצורה ברורה. המאמר מדגיש תרשימי תיבה (כולל גרסאות משופרות לנתונים נטויי תפוצה), תרשימי מי-ויולין ותרשימי הר געש (volcano) שמשלבים גודל השפעה וחשיבות סטטיסטית. בליפידים מתוארים חזויות מיוחדות יותר, כמו רשתות ליפידים שמראות שינויים מתואמים ברמה של מחלקות שלמות, ותרשימי שרשראות חומצות שומן החושפים דפוסים באורך שרשרת הפחמנים ובמיצוע הרוויה.
לזהות דפוסים בהרבה משתנים בו‑זמנית
מכיוון שבכל דגימה ניתן למדוד מאות או אלפי מולקולות, שיטות רב‑משתניות הן קריטיות. הסקירה מסבירה כיצד ניתוח רכיבים עיקריים (PCA) מדחס את המורכבות לכמה צירים חדשים שתופסים את כיווני השונות העיקריים, מה שמאפשר בדיקות מהירות להפרדה בין קבוצות, להשפעות אצווה או ליציבות אנליטית. שיטות בלתי‑לינאריות מתקדמות יותר, כולל t‑SNE ו‑UMAP, יכולות לחשוף אשכולות ומבנים עדינים במרחב גבוה המימד. למצבים שבהם המטרה היא לסווג דגימות — למשל להבחין בין חולים ובקרי— המחברים מתארים גישות מונחות כמו Partial Least Squares והרחבתה האורתוגונלית (PLS‑DA ו‑OPLS‑DA). שיטות אלה מקשרות פרופילים מולקולריים לתוויות דגימות, תומכות בבחירת מאפיינים, ולעתים מסכמות באמצעות גרפים של ציוני דגימות, גרפי loading וקימורים של מאפייני קבלה/דחייה (ROC).
חבילות מעשיות ב‑R וב‑Python
כדי לסייע למתחילים לעבור מתיאוריה לפרקטיקה, המאמר מסקר אקוסיסטם רחב של חבילות תוכנה. ב‑R אוספים כמו tidyverse ו‑tidymodels מפשטים עיבוד נתונים ומידול, בעוד ggplot2 וחבילות משלימות כגון ggpubr, ggstatsplot ו‑tidyplots מקלות על יצירת איורים באיכות פרסומית. ספריות מיוחדות מטפלות ב‑PCA, אשכולות ומודלים מבוססי PLS, וחבילות Bioconductor תומכות במפות חום מורכבות ובגרפיקות אינטראקטיביות. ב‑Python pandas מספקת טיפול בטבלאות, בעוד matplotlib, seaborn ו‑plotly מכסות ויזואליזציה, ו‑scikit‑learn מציעה סט רחב של שיטות רב‑משתניות. לאורך כל הדרך המחברים מדגישים דוגמאות שלב‑אחר‑שלב הזמינות ב‑GitBook נלווה, כך שקוראים יכולים לשכפל זרימות עבודה ולהתאים אותן לנתוניהם. 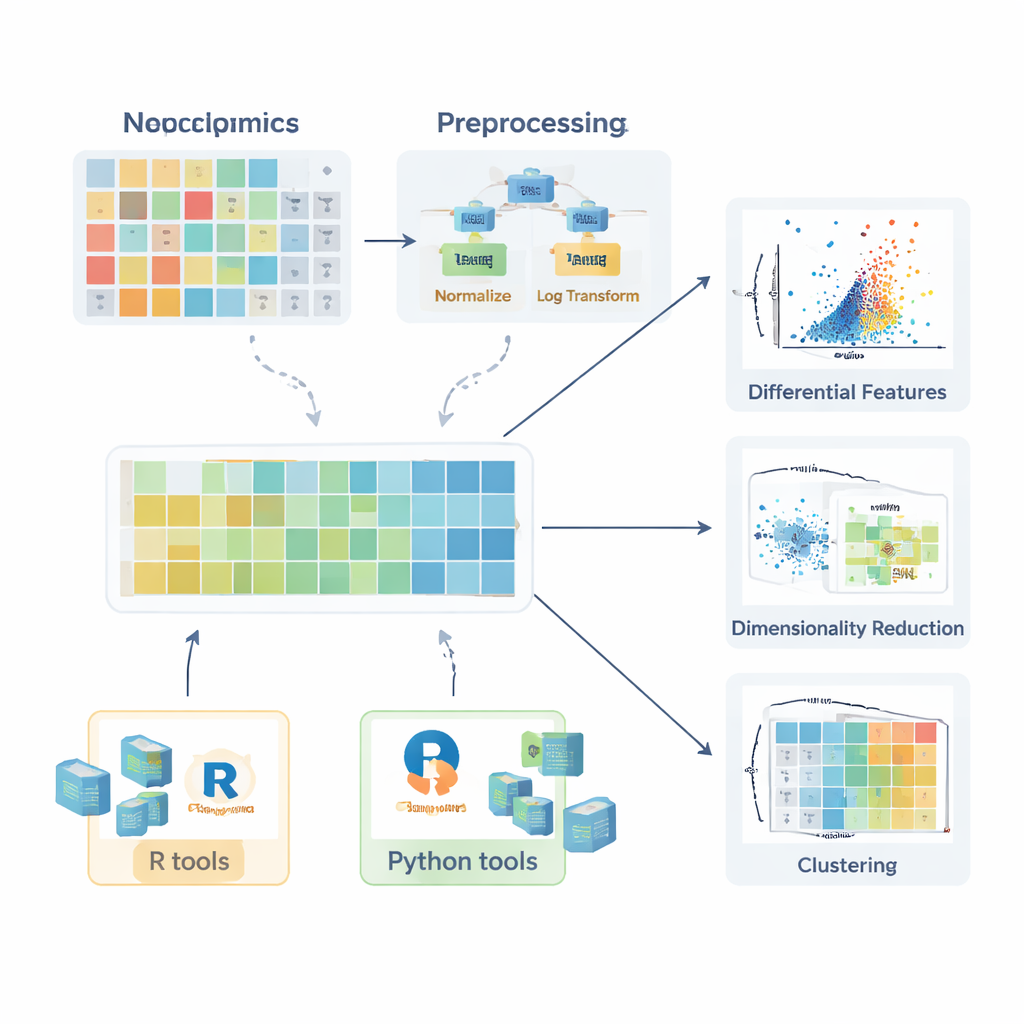
להפוך כימיה מורכבת לתובנה אמינה
המאמר מסכם שההבטחה האמיתית של ליפידומיקה ומטבולומיקה אינה רק במכשירים עוצמתיים, אלא באופן שבו מעבדים וממחישים את התוצר שלהם באופן מחשבה. על ידי הקפדה על פרקטיקה סטטיסטית טובה, שימוש בכלים פתוחים ומתועדים היטב ב‑R וב‑Python ובהסתמכות על דוגמאות קוד משותפות, חוקרים יכולים לבנות צינורות עבודה חסיני חזרות ואמינים. זה משפר את הסיכוי שהדפוסים הנמצאים במולקולות זעירות יתורגמו לסמנים מהימנים, להבנה טובה יותר של מנגנוני מחלה ולגישות מותאמות אישית יותר לרפואה שלבסוף ייטיבו עם המטופלים.
ציטוט: Idkowiak, J., Dehairs, J., Schwarzerová, J. et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nat Commun 16, 8714 (2025). https://doi.org/10.1038/s41467-025-63751-1
מילות מפתח: ליפידומיקה, מטבולומיקה, המחשת נתונים, תכנות ב‑R, Python