Clear Sky Science · he
זיהוי מידע חזותי ושאלות ותשובות על יורשי מורשת תרבותית בלתי מוחשית באמצעות מסגרת משופרת של Graph-Retrieval
להכניס מסורות נסתרים לעידן הדיגיטלי
בכל רחבי סין, אוטודידקטים של אופרה מסורתית, חיתוך נייר, בובות צל ואמנויות חיות אחרות שומרים על מיומנויות שעברו מדור לדור. עם זאת, רוב מה שאנו יודעים על יורשים אלה קיים רק בקבצים ובתמונות מפוזרות באינטרנט, מה שמקשה על הציבור — ואפילו על חוקרים — למצוא מידע אמין. מאמר זה מציע מסגרת מחשוב חדשה שקוראת באופן אוטומטי את ה"כרטיסי ביקור החזותיים" של יורשי מורשת תרבותית בלתי מוחשית ואז משתמשת במודלים לשוניים מתקדמים כדי לענות על שאלות וליצור דוחות קריאים לגביהם.
מכרטיסי תמונה לידע מובנה
מוסדות תרבות רבים מפרסמים כיום כרטיסים דיגיטליים שמשלבים טקסט, פריסה וגרפיקה פשוטה להצגת כל יורש: שם, מקצוע, מקום, ביוגרפיה ועוד. בני אדם יכולים לעיין בהם במבט חטוף, אך מחשבים מתקשים מאחר שהכרטיסים מגיעים מאזורים שונים, משתמשים בעיצובים מגוונים ולעיתים כוללים טקסט חסר או פגום. המחברים בונים מאגר נתונים גדול של 5,237 כרטיסי ביקור כאלו של יורשי מורשת בלתי מוחשית סיניים, כשכל כרטיס מתויג בקפידה בעשר קטגוריות מידע מרכזיות, כגון מספר הפרויקט, שם הפרויקט, אזור, מין, יחידת עבודה ותיאור קצר. הם משתמשים תחילה בזיהוי תווים אופטי (OCR) לקריאת הטקסט ולתיעוד המיקום של כל מקטע על הכרטיס, ואז מפעילים מודלים לשוניים גדולים כדי לסייע בסטנדרטיזציה של התוויות לפני שבעלי מקצוע אנושיים מאמתים אותן.
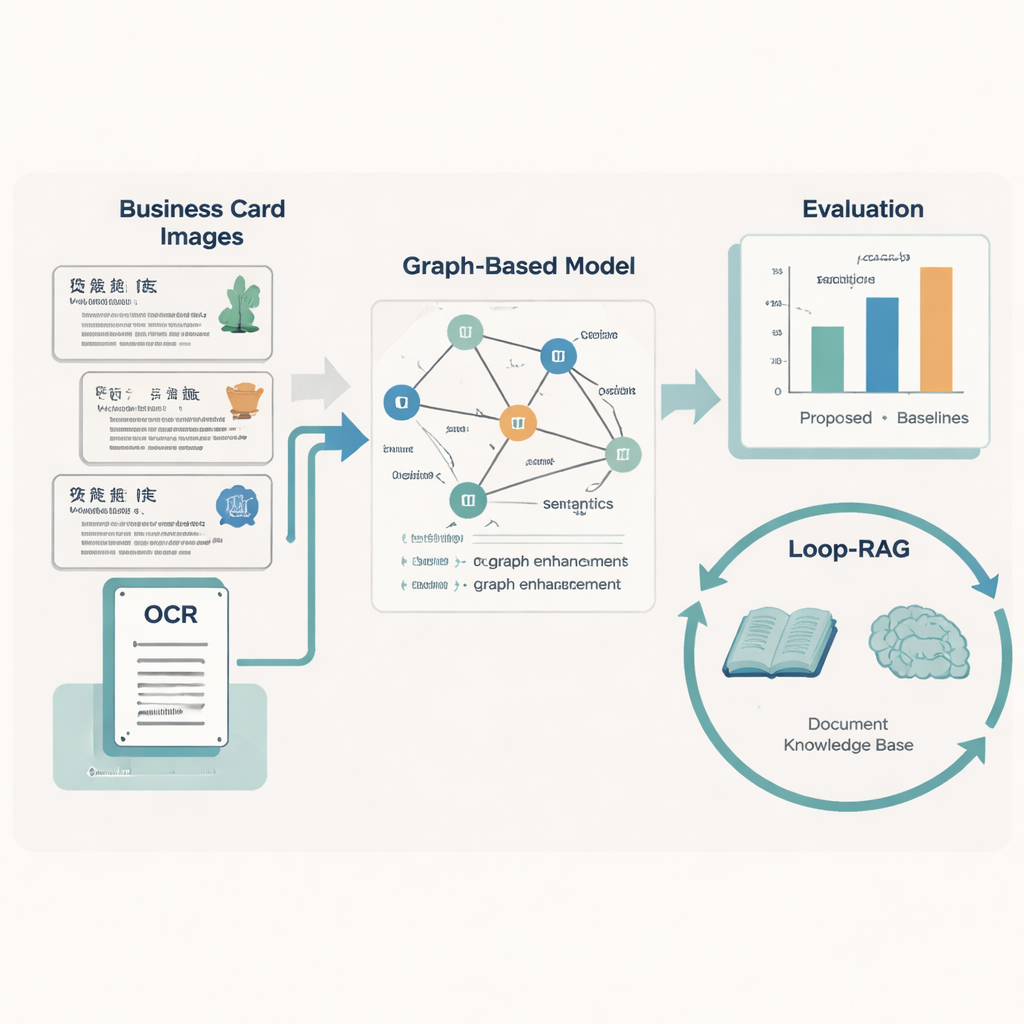
להדריך מכונות לקרוא פריסה ומשמעות
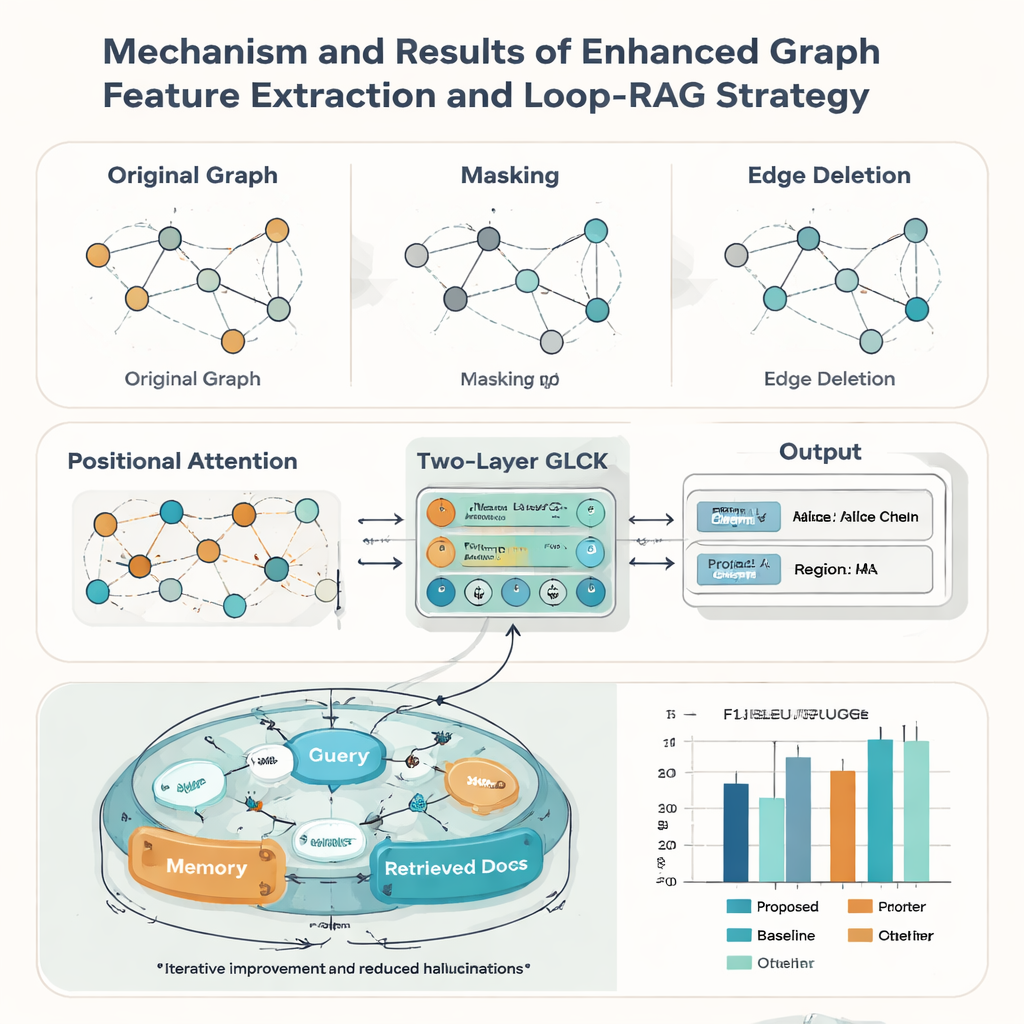
כדי להפוך כל כרטיס לנתונים נקיים ומובנים, הצוות מפתח מודל "Graph-Retrieval" המדמה את אופן השימוש האנושי גם במילים וגם בפריסה. כל מקטע טקסט על הכרטיס הופך לצומת בגרף, והיחסים המרחביים בין המקטעים — שמאל, ימין, מעל, מתחת — יוצרים את הקשתות. רכיב לשוני המבוסס על RoBERTa ו-LSTM דו־כיווני לומד את משמעות הטקסט, בתמיכה במילון מותאם אישית של כמעט 5,000 ביטויים ספציפיים ל־ICH כך ששמות מלאכות או ביטויים מקומיים לא רגילים מטופלים נכון. מעל לכך, רשת עצבית גרפית מפיצה מידע בין צמתים שכנים ומשפרת את התחזיות לגבי מה כל מקטע טקסט מייצג (למשל, להחליט האם שם מקום הוא אזור או יחידת עבודה).
להפוך את המערכת לעמידה בפני חוסר סדר מעשי
רשומות ירושה אמיתיות נדירות מושלמות: כרטיסים עלולים להיות בלויים, חמקי פריים או סרוקים בקושי. כדי להתמודד עם זה, המחברים מחזקים את מודל הגרף בשלוש רעיונות שאומצו מהאוגמנטציית נתונים. הם מסמנים באקראי חלק מהצמתים כך שהמערכת לומדת להסיק מידע חסר מההקשר; הם מוחקים באקראי חלק מהקשתות כדי שתוכל לסבול שינויים בפריסה; והם מוסיפים מנגנון תשומת לב מיקומי שמלכד את "סדר הקריאה" הכולל של האלמנטים על הכרטיס. יחד, הטריקים הללו עוזרים למודל להכליל לסגנונות ואיכויות מסמכים רבים. במבחנים מול תשע שיטות מתחרות ידועות, הגישה החדשה משיגה את ציון ה־F1 המקרו הגבוה ביותר (0.928) על מאגר כרטיסי ה־ICH וגם מובילה בחמישה תקני מסמכים ציבוריים, מה שמעיד על שימושיות רחבה מעבר ליישומי מורשת.
שאלות ותשובות חכמות יותר עם Looping Retrieval
הכרת הטקסט היא רק חצי מהסיפור; התרומה השנייה של המאמר היא אסטרטגיית Loop-RAG (Loop Retrieval-Augmented Generation) שעובדת עם מודלים לשוניים גדולים כגון GPT-4, Llama ו־ChatGLM. מערכות מסורתיות המתגברות על ידי אחזור מביאות מסמכי רקע פעם אחת ואז מייצרות תשובה, מה שעשוי להיות עדיין חסר או שגוי. בניגוד לכך, Loop-RAG מוסיפה לולאה פנימית שבודקת שוב ושוב האם למודל הלשוני יש מספיק מידע עבור התשובה הנוכחית ואם לא — מפעילה חיפוש ממוקד נוסף בבסיס ידע וקטורי של ICH. לולאה חיצונית לומדת לאחר מכן ממספר רב של אינטראקציות קודמות אילו מסלולי אחזור וסגנונות פרומפט עובדים הכי טוב, ומצמצמת בהדרגה חיפושים מבוזבזים ושגיאות עובדתיות.
מרשומות גולמיות לסיפורים תרבותיים אמינים
באמצעות מסגרת משולבת זו, המערכת יכולה ליצור באופן אוטומטי דוחות קצרים על יורש — מסכמת את מלאכתו, האזור, עבודות ייצוגיות ומעמדו — ולענות על אלפי שאלות עובדתיות על אנשים ונוהגים. מדדים סטנדרטיים לאיכות לשונית כגון BLEU, METEOR ו־ROUGE מראים כי Loop-RAG עם GPT-4 משתפר על פני מודלים לשוניים פשוטים ועל פני סידורי אחזור פשוטים יותר, ובמקביל משיג את הדיוק הטוב ביותר (F1 עד 0.941) בשאלות ותשובות, אפילו כאשר ניתנים רק מספר דוגמאות מועט. לקורא כללי, משמעות הדבר היא שעתידים לשרור פלטפורמות מורשת תרבותית אינטראקטיביות ומהימנות שיציעו הסברים זמינים וניתנים לאימות של אמנויות מסורתיות, והופכים רשומות דיגיטליות מפוזרות לסיפורים עשירים וניתנים לניווט שעוזרים לשמור על מסורות חיות גלויים ומוערכים.
ציטוט: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
מילות מפתח: מורשת תרבותית בלתי מוחשית, חילוץ מידע, רשתות עצביות גרפיות, retrieval-augmented generation, מדעי הרוח הדיגיטליים