Clear Sky Science · he
Geo-TCAM: שיטה לתיאור תמונות תאנקה שמשלבת מִדּוּר נושאים עם תשומת לב מרחבית בהנחיית גיאומטריה
אמנות עתיקה פוגשת טכנולוגיה חכמה
ציירי התאנקה — המגילות הצבעוניות הנראות במקדשים טיבטיים רבים — מלאות בפרטים זעירים ושכבות של משמעות דתית. עבור מבקרי מוזיאון או צופים מקוונים חסרי הכשרה מקצועית, רוב הסמלים האלה קשים להבנה. המחקר הזה מציג את Geo‑TCAM, מערכת בינה מלאכותית שנועדה ליצור באופן אוטומטי תיאורים עשירים ומדויקים של תמונות תאנקה, ולסייע לאנשים ברחבי העולם להבין ולשמר את המורשת התרבותית הייחודית הזאת.
מדוע תמונות תאנקה קשות למחשבים
שלא כמו תמונות יום‑יומיות, יצירות תאנקה מתוכננות להיות צפופות וסמליות מבחינה מכוונת. ציור אחד עשוי להכיל אל מרכזי, עשרות דמויות קטנות יותר, גבולות מעוטרים ותנוחות ידיים, חפצים, צבעים ומחוות שכל אחד מהם נושא משמעות דתית. תוכנות סטנדרטיות ליצירת תיאורי תמונה מסתגלות היטב לסצנות פשוטות כגון "כלב על חוף", אך מתקשות כאן: הן עלולות לזהות את הבודהא המרכזי אך לפספס אם הוא מחזיק קערה או חרב, לפרש לא נכון את תנוחתו, או לבלבל אותו עם אל אחר הדומה לו. טעויות כאלה אינן טריביאליות — הן עלולות להפוך את הסיפור והדוקטרינה שהציור נועד לשדר, ולפגוע בערכו החינוכי והתרבותי.
מפת דרכים חדשה לתיאור תמונות קדושות
Geo‑TCAM מטפל בבעיות אלה על ידי שילוב של שלוש רעיונות: תכונות חזותיות בכמה רמות, ידע נושאי על אמנות תאנקה, ותשומת לב מונחית גיאומטריה לאזורים מרכזיים כמו פני הדמויות. ראשית, הוא משתמש ברשת עמוקה (ResNet50) כדי לבחון כל תמונה במספר רמות במקביל: שכבות בינוניות לוכדות קצוות, מרקמים וצורות פשוטות, בעוד ששכבות עמוקות יותר מסכמות את ההרכבה הכוללת. באמצעות מיזוג הרמות האלה, המודל יכול לשים לב גם לפרטים עדינים כמו קישוטים וגם לפריסת הרקע והדמויות, ולספק הבנה חזותית עשירה יותר מאשר מערכות קודמות שהתמקדו בשכבה בודדת. 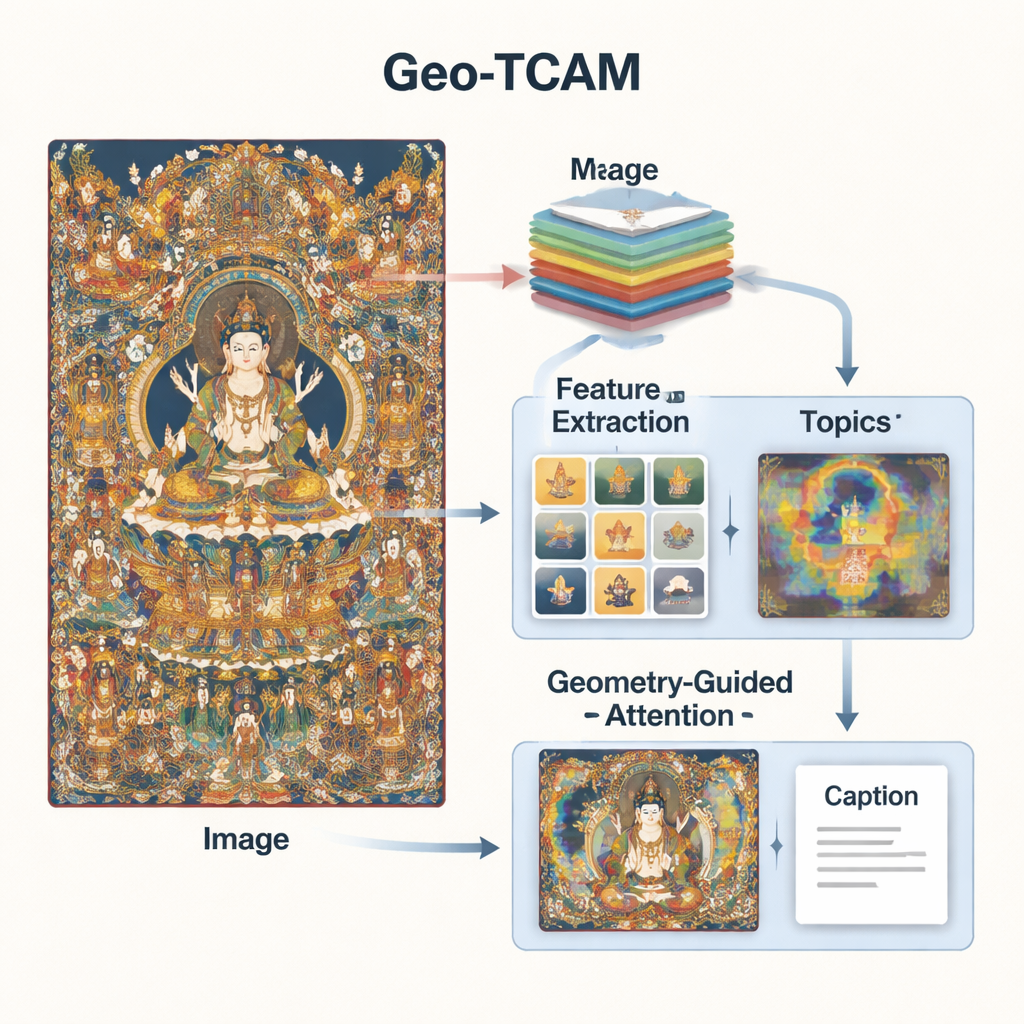
ללמד את המודל את "הנושאים" של תאנקה
חזון לבדו אינו מספיק; המערכת גם צריכה מושג על שפת התאנקה ונושאיה. כדי לספק זאת, החוקרים אימנו מודל נושאים על אלפי תיאורי תאנקה שכתבו מומחים. מודל זה מקבץ מילים למספר נושאים נפוצים — למשל אלה הקשורים לבודהות, לבודיסאטוות, לכתרי לוטוס, לכלים טקסיים או לישויות מגינות. עבור כל תמונה חדשה, Geo‑TCAM מעריך אילו נושאים רלוונטיים ומשלב את המידע הזה עם התכונות הוויזואליות. מנגנון תשומת לב מדגיש אז את אזורי התמונה המתאימים ביותר לנושאים הצפויים. למעשה, ידע מוקדם על אילו אובייקטים וסמלים נוטים להופיע יחד דוחף את ה‑AI לתיאורים בעלי משמעות ורגישויות תרבותיות.
לאפשר ל‑AI "להישקף" היכן שזה הכי חשוב
החידוש השלישי הוא מודול תשומת לב מרחבית לפנים בהנחיית גיאומטריה (GFSA). קומפוזיציות תאנקה בדרך כלל ממקמות את פני הדמות המרכזית באזור משוער בציור. Geo‑TCAM משתמש בכלי גילוי קצוות פשוטים כדי למקד באזור זה ובידיו ותנוחתו של הדמות, ואז מפעיל מנגנון תשומת לב ייעודי שמגביר את השפעת הפיקסלים האלה בעת יצירת הכיתוב. אסטרטגיית "למקם קודם, להנחות לאחר מכן" זו מונעת זיהוי שגוי מוקדם של האל המרכזי, אשר אחרת היה מוביל לשרשרות שגיאות טקסטואליות לגבי מחוות, תכונות ומעמד. מפות חום חזותיות מראות שבעזרת GFSA המודל מתרכז בצורה נקייה יותר בפני הדמות המרכזית ובאובייקטים המפתח תוך שמירה על מעקב אחרי מוטיבים חשובים ברקע. 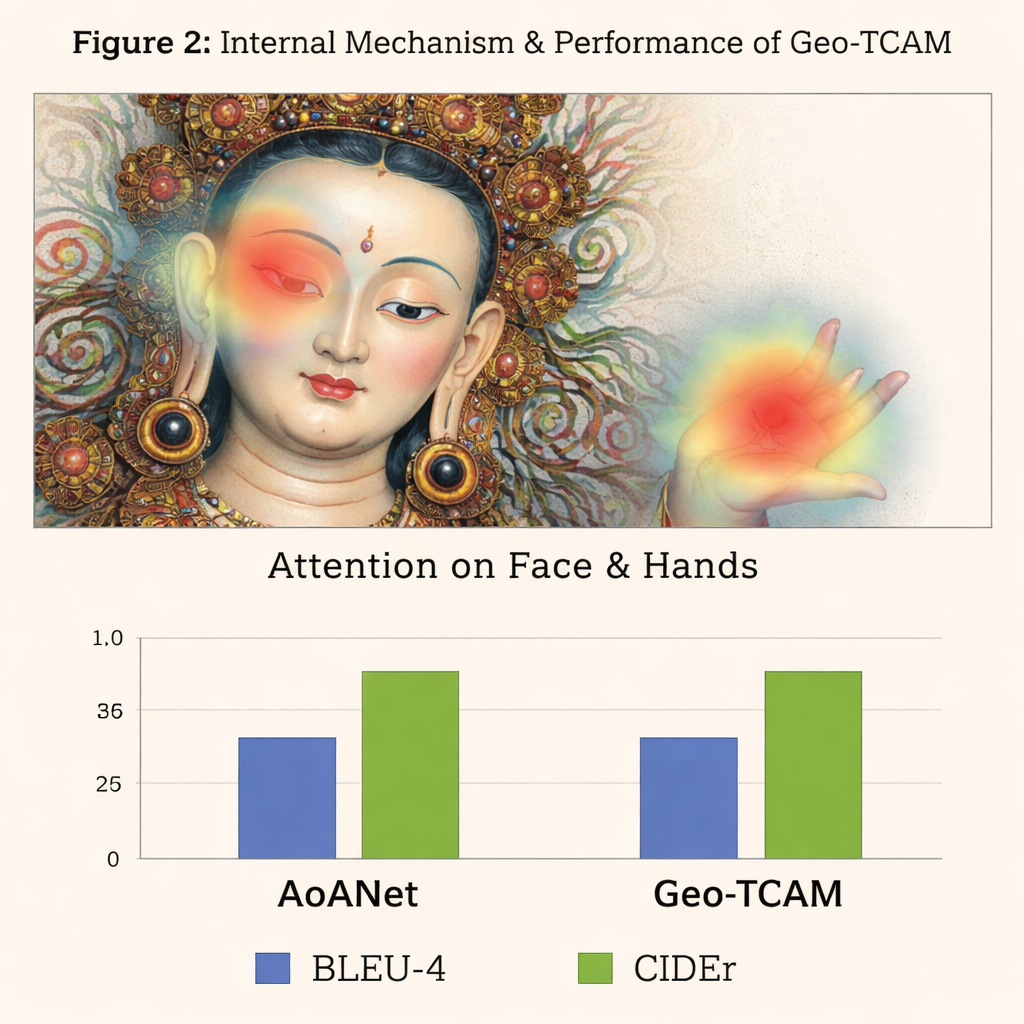
עד כמה Geo‑TCAM עובד טוב?
כדי לבדוק את הגישה שלהם, המחברים בנו מאגר נתונים ייעודי D‑Thangka של כמעט 4,000 תמונות מתועדות בקפידה, כל אחת עם תיאורים מפורטים של מומחים. על מאגר זה, Geo‑TCAM עלה בבירור על מספר מערכות תיאור חזקות, כולל AoANet הפופולרי ומודלים גדולים חזון‑שפה. בהתאם למטריקה, הניקוד שלו השתפר עד כ‑120% בהשוואה לבסיס, ומעריכים אנושיים העדיפו את הכיתובים שלו ברוב מוחלט מבחינת דיוק, שוטפות ועושר פרטים. חשובה מזה, כאשר אותו מודל הוערך על מאגר תמונות יום‑יומי סטנדרטי (COCO), הוא נשאר תחרותי מול השיטות המובילות, מה שמראה שהעיצוב שלו חזק ועדיין כללי‑שימוש.
מה משמעות הדבר עבור מורשת ומעבר לה
עבור לא‑מומחים, המסקנה המרכזית היא ש‑Geo‑TCAM יכול להפוך ציורי תאנקה חזותיתmente מורכבים לנרטיבים ברורים ומידעיים המדגישים מי מתואר, מה הם עושים ולמה הפרטים האלה חשובים. על‑ידי שילוב ניתוח חזותי רב‑שכבתי, נושאים נלמדים מתוך טקסטים מומחים ותשומת לב מיוחדת לפנים ולמחוות, המערכת מתאימה את הכיתובים שלה באופן קרוב יותר לאופן שבו מומחים אנושיים קוראים את היצירות האלה. לטווח הארוך, כלים כאלה יכולים לתמוך בארכיונים דיגיטליים, במדריכי מוזיאון ובפלטפורמות חינוכיות, ולהפוך אמנות דתית אזוטרית לנגישה יותר תוך סיוע לשימור ולתיעוד של אוצרות תרבות פגיעים.
ציטוט: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
מילות מפתח: תיאור תמונות תאנקה, בינה מלאכותית למורשת תרבותית, תשומת לב חזותית, מִדּוּר נושאים, שימור אמנות