Clear Sky Science · he
בניית קורפוס מתויג לפי חלקי דיבור של עשרים וארבע ההיסטוריות הקלאסיות-מודרניות
מדוע הכתבים העתיקים חשובים בעידן הבינה המלאכותית
במשך יותר משני אלפים שנה, היסטוריונים סינים תיעדו מלחמות, חצרות, רעב וחיי יום־יום בסדרה הענקית המוכרת כעשרים וארבע ההיסטוריות. היום, הקלאסיקות האלה נחקרות לא רק על־ידי חוקרים, אלא גם על־ידי מחשבים. מחקר זה מתאר כיצד חוקרים הפכו את הכתבים העתיקים ואת התרגומים המודרניים שלהם למסד נתונים לשוני מתויג בקפידה. משאב זה יכול לסייע לבינה מלאכותית לקרוא, לתרגם ולנתח טקסטים היסטוריים בדיוק גבוה יותר — ולהפוך את העבר הרחוק לנגיש הרבה יותר לציבור.
מכרכים מעופשים לטקסט דיגיטלי
הפרויקט מתחיל במשימה בסיסית אך מרתיעה: להפוך מאות אלפי תווים מודפסים לטקסט דיגיטלי נקי ומדויק. הצוות נשען על שני מקורות — מהדורה מודרנית תקנית של עשרים וארבע ההיסטוריות ואוסף מקוון גדול — כדי להאכיל מערכת זיהוי תווים אופטי. לאחר מכן הם הסירו בקפדנות קטעים מושחתים, תיקנו תווים שהוקראו שגוי והוציאו רעשים כגון כותרות עלי־דפים ותחתיות דפים. התוצאה הייתה סט מקביל של קבצים, אחד בסינית קלאסית ואחד בסינית מודרנית, שהתאימו בקפידה לספרים המקוריים אך היו מוכנים לניתוח חישובי. 
התאמת משפטים עתיקים לאלה המודרניים
מכיוון שמטרת המחקר הייתה להשוות כיצד השפה השתנתה במרוצת הזמן, היה חשוב ליישר את הגרסאות העתיקות והמודרניות משפט אחר משפט. החוקרים השתמשו בתוכנות יישור מתמחות כדי להתאים תחילה פסקאות, ואז לפצל אותן למשפטים מקבילים. כלים אוטומטיים עשו את העבודה הכבדה, אך מומחים אנושיים ביקשו ואישרו כל זוג מוצע, משום שתחביר הסינית הקלאסית יכול להיות שונה מאוד מזה של הסינית המודרנית. כשהתוכנה טעתה — חילקה מחשבה במקום הלא נכון או קראה תו בצורה שגויה — המתויגים בדקו את הדפים הסרוקים המקוריים ותיקנו את הטקסט הדיגיטלי כך שכל משפט קלאסי יתיישר בצורה מדויקת עם המקבילה המודרנית שלו.
ללמד מחשבים לזהות דקדוק
מעבר לשעתוק פשוט, ליבת הפרויקט היא תיוג דקדוקי. כל מילה בשני הטקסטים, העתיק והמודרני, סומנה בתווית חלק־דיבור, המציינת האם זוהי, למשל, שם עצם, פועל או מילה המציינת זמן. מאחר שאין תקן יחיד לסינית הקלאסית, הצוות עגן את המערכת שלו בהנחיות הלאומיות המודרניות ואז התאימם לשימוש הישן. הם גיבשו סכמת 22 תוויות הכוללת תו מיוחד לשימושים פועליים תנכ״יים/עתיקים ייחודיים כגון "להחיות" או "להיות נהרג למען המדינה". רשת עצבית מותאמת — שנבנתה על מודל שפה לטקסטים עתיקים ושכבות תיוג רצפים — ייצרה תוויות ראשוניות, שאחריהן בדקה ותיקנה צוות גדול של סטודנטים לתארים מתקדמים מאומנים היטב. מבחני הסכמה מחמירים בין המתויגים הראו עקביות גבוהה מאוד, ואישרו כי הקורפוס המתויג הסופי גדול ואמין.
מה העדשה החדשה מגלה
עם הקורפוס המתויג במקום, החוקרים בחנו חלק מהתבניות שהנתונים מעלים. בסינית הקלאסית, מילים חד־תוויות שולטות, משקפות סגנון כתיבה ידוע בקיצורו, בעוד שסינית מודרנית נוטה למילים דו־תוויות. הפריטים העתיקים הנפוצים ביותר הם חלקי דקדוק קטנים כגון "之" ו"以", בעוד שפעלים ושמות עצם שגרתיים יחד מהווים בערך מחצית מכל המילים בשני התקופות. הנתונים גם מראים אילו מילים נוטות להופיע יחד — לדוגמה, מבנים המתארים פקידים, צבאות או משלחות דיפלומטיות. על ידי השוואת תוויות בין הזוגות העתיקים־מודרניים, הצוות עקב אחר כיצד פונקציות השתנו לאורך הזמן: חלק מהמילות יחס והתרות הישנות מתאימות היום לפעלים מודרניים מלאים, וחלק מהפעלים התגבשו לתארים קבועים או מונחי־חוק. מקרה מבחן אחד חילץ את כל שמות המקומות ומיפה היכן הם מצטברים בשושלות שונות, וחשף כיצד מרכזים פוליטיים וכלכליים זזו מהצפון־מערב לאזור היאנגצה התחתון ומעבר לו. 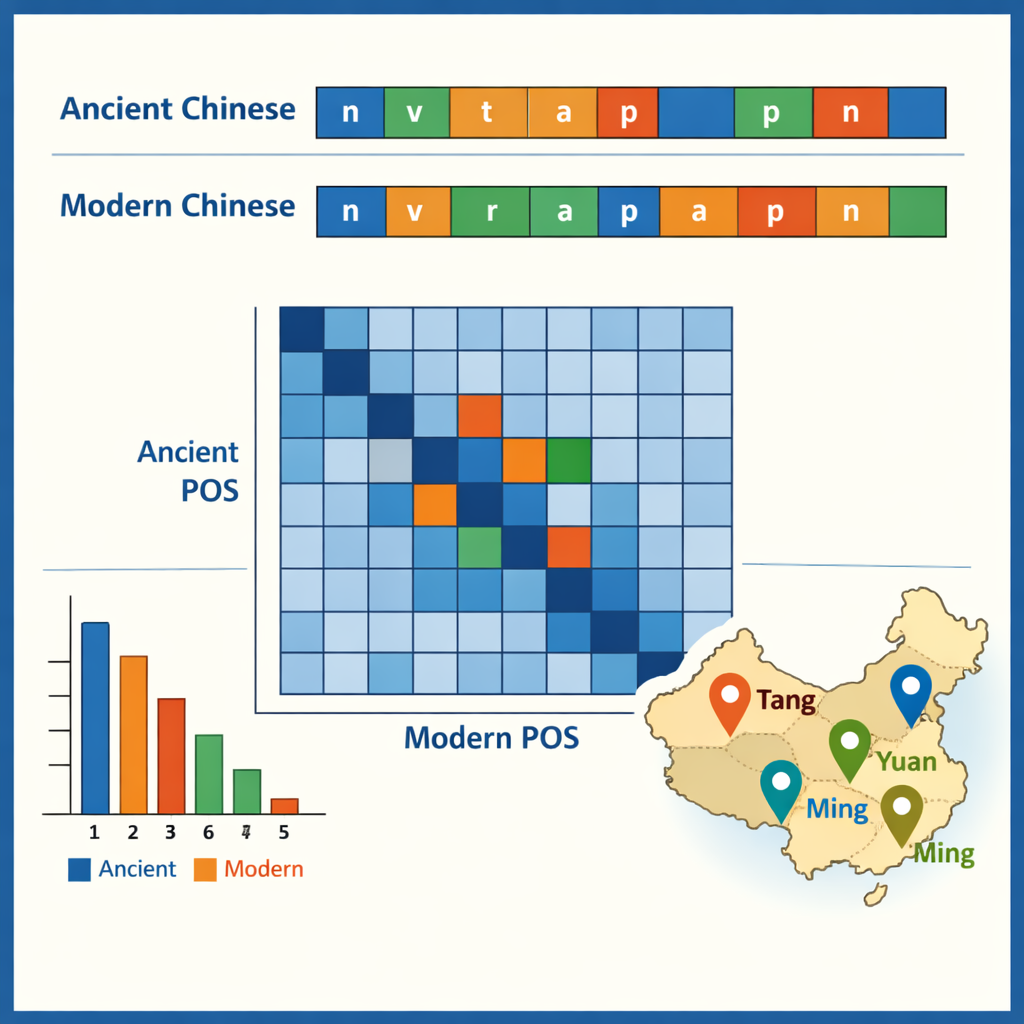
להביא את העבר אל העתיד הדיגיטלי
במילים פשוטות, פרויקט זה הופך חומה עצומה של פרוזה קלאסית לנתונים מבניים שגם בני אדם וגם מכונות יכולים לנווט בהם. בעבור היסטוריונים ולשונאים, הוא מספק כלי העוצמתי למעקב אחר אופן שבו מילים, דקדוק ואף גבולות מדינתיים התפתחו לאורך המאות. בעבור מפתחי בינה מלאכותית, הוא מציע חומר אימון איכותי לבניית מודלי שפה שיכולים באמת לטפל בסינית קלאסית במקום להתייחס אליה כאל ערבוביה של תווים. ובעבור סטודנטים וקוראים כלליים, ההתאמה משפט־אחר־משפט של הטקסט העתיק והמודרני מורידה את המחסום לקריאת הקלאסיקות. באמצעות תיוג ויישור קפדני של עשרים וארבע ההיסטוריות, המחברים יצרו גשר מהמגילות הכתובניות של העבר אל המערכות החכמות של ההווה והעתיד.
ציטוט: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
מילות מפתח: קורפוס סיני עתיק, תיוג חלקי דיבור, מדעי הרוח הדיגיטליים, טקסטים מקבילים, שינוי שפה היסטורי