Clear Sky Science · fr
Analyse thématique avec IA générative et apprentissage automatique open source : une nouvelle méthode de développement inductif de codebooks qualitatifs
Pourquoi cela compte pour les questions du quotidien
Chaque fois que des personnes remplissent des questionnaires ou répondent à des entretiens, elles laissent derrière elles des récits riches sur le travail, l’école, la santé ou la vie communautaire. Lire quelques dizaines de ces réponses est facile ; tirer du sens de milliers ne l’est pas. Cet article décrit une nouvelle manière pour les chercheur·e·s d’utiliser une intelligence artificielle open source pour aider à trier d’énormes piles de commentaires écrits et en extraire les idées principales, tout en gardant les humains aux commandes de l’interprétation. L’objectif est de rendre possible une recherche qualitative soigneuse et nuancée à des échelles habituellement réservées aux statistiques de big data.
Une façon plus intelligente de lire des milliers de commentaires
Les auteur·rice·s se concentrent sur une approche populaire en sciences sociales appelée analyse thématique, où les chercheur·e·s lisent des textes et recherchent des motifs récurrents ou des « thèmes » qui répondent à leurs questions de recherche. Traditionnellement, cela implique de coder lentement chaque commentaire à la main et de construire un codebook — une liste structurée de thèmes et de sous-thèmes. Ce processus peut bien fonctionner pour quelques dizaines d’entretiens, mais il devient écrasant lorsque des dizaines de milliers de réponses ouvertes sont en jeu. L’article se demande : des modèles textuels génératifs librement disponibles et d’autres outils open source peuvent-ils aider aux étapes initiales et répétitives de ce travail sans remplacer le jugement humain ?
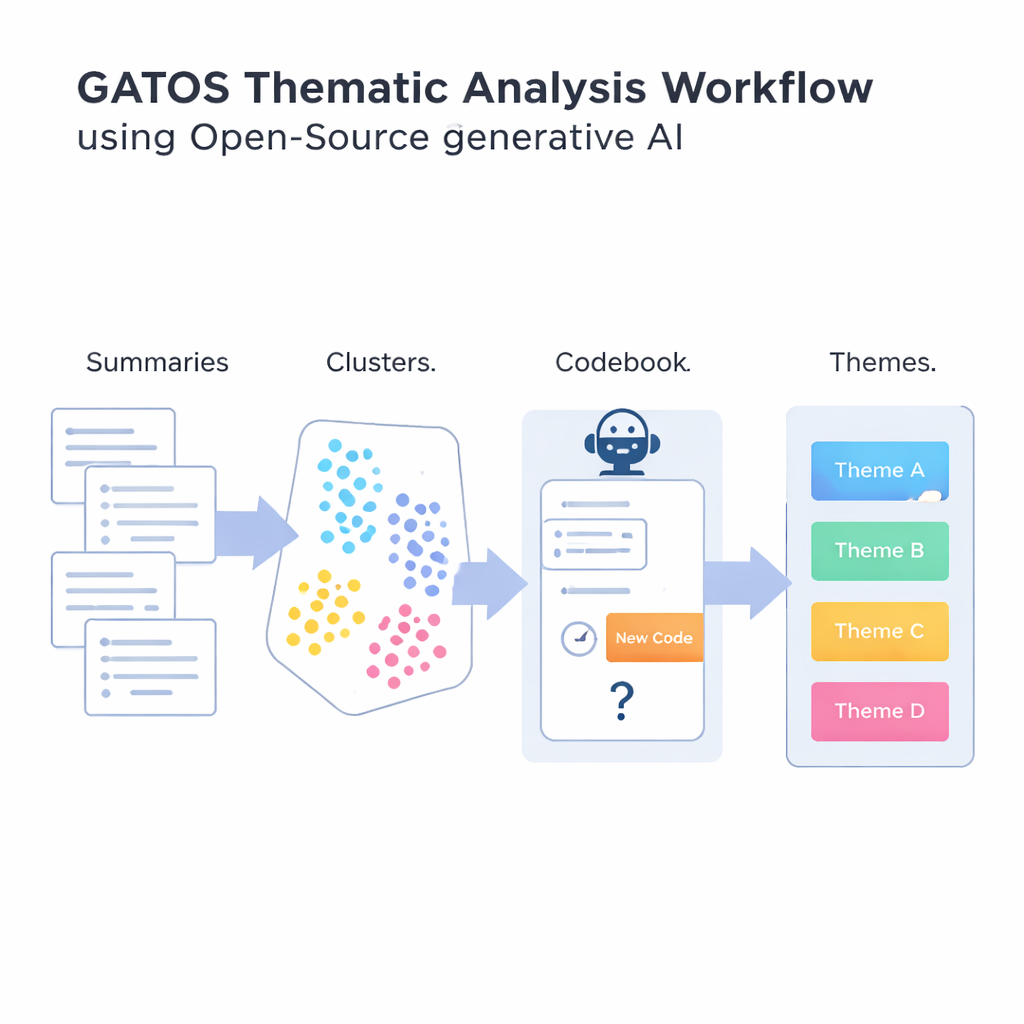
Présentation du workflow GATOS
Pour répondre à cette question, les auteur·rice·s introduisent le workflow Generative AI-enabled Theme Organization and Structuring, ou GATOS. Ce flux de travail enchaîne plusieurs étapes. D’abord, un modèle de langage open source lit les réponses individuelles et rédige de courts points de synthèse ciblés sur ce que chaque personne exprime. Ensuite, un autre outil transforme ces synthèses en représentations numériques afin qu’un ordinateur puisse comparer et regrouper des idées similaires. Ces synthèses sont alors regroupées en clusters susceptibles de refléter des thèmes partagés, comme des préoccupations liées à l’équilibre travail–vie personnelle ou des frustrations face à une communication peu claire.
Laisser l’IA suggérer, mais pas inonder, de nouvelles idées
L’étape la plus originale intervient lorsque le système commence à élaborer un codebook provisoire. Pour chaque groupe de synthèses connexes, un autre modèle génératif examine les idées du cluster et les codes déjà présents dans le codebook. Il raisonne alors pour déterminer si un nouveau code est réellement nécessaire ou si les codes existants suffisent. Si un nouvel angle émerge — par exemple « outils de visioconférence fiables » comme préoccupation spécifique — il propose une courte étiquette et une définition, qui sont ajoutées. Sinon, il choisit de réutiliser ce qui existe déjà. Une étape finale regroupe les codes apparentés en thèmes plus larges, créant une cartographie structurée allant des commentaires bruts à des insights organisés. Tout au long du processus, l’accent est mis sur l’évitement d’un flot de codes presque dupliqués tout en capturant les nuances des expériences des personnes.
Tester la méthode avec des données factices réalistes
Parce que les études du monde réel n’ont que rarement une « clé de réponse » connue, l’équipe a testé GATOS en utilisant des données synthétiques (générées par ordinateur) où les thèmes cachés étaient connus à l’avance. Ils ont créé trois grands jeux de données réalistes : des retours entre pairs sur le travail d’équipe, des avis sur la culture éthique en entreprise, et des opinions sur le retour au bureau après la pandémie de COVID-19. Pour chaque jeu de données, ils ont d’abord défini huit thèmes et plusieurs sous-thèmes, puis utilisé un modèle de langage pour rédiger des centaines de réponses réalistes provenant de différents personas, tels que des syndiqués, des gestionnaires ou des étudiant·e·s. Après avoir exécuté GATOS sur ces jeux, des réviseurs humains ont comparé les thèmes générés par l’IA aux sous-thèmes cachés d’origine pour évaluer leur convergence.
Quel a été le résultat et quels sont les compromis ?
Dans les trois cas de test, le workflow a retrouvé la plupart des sous-thèmes originaux de manière assez fidèle : la grande majorité disposait d’au moins une correspondance forte, et seule une petite poignée n’avait pas de bon équivalent. Fait important, à mesure que le système examinait davantage de données, il proposait moins de nouveaux codes, ce qui suggère qu’il apprenait à réutiliser des idées existantes plutôt qu’à inventer des variations sans fin. Les auteur·rice·s soutiennent qu’une telle configuration open source exécutable localement peut réduire les inquiétudes liées à la vie privée et faciliter la reproductibilité entre équipes de recherche. Ils soulignent en même temps que les données synthétiques sont plus simples que bien des situations réelles, que le workflow peut encore générer des codes qui se chevauchent, et que des chercheur·e·s humains restent nécessaires pour affiner, interpréter et juger le codebook final.
Ce que cela signifie pour les non-experts
Pour les lecteurs et lectrices hors du milieu académique, la conclusion est que l’IA open source peut aider les scientifiques sociaux et d’autres chercheur·e·s à écouter bien plus de personnes sans réduire leurs propos à de vulgaires nombres. Plutôt que de remplacer les analystes humains, le workflow GATOS agit comme un assistant très rapide et très organisé qui suggère des motifs et des étiquettes provisoires, laissant aux humains le soin de décider de la signification réelle de ces motifs. Si d’autres études confirment ces résultats sur des données du monde réel, des outils comme GATOS pourraient faciliter l’élaboration de politiques en entreprise, de programmes éducatifs et de décisions publiques fondées sur la richesse complète de ce que disent réellement les gens, et non seulement sur des cases à cocher de sondage.
Citation: Katz, A., Fleming, G.C. & Main, J.B. Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanit Soc Sci Commun 13, 209 (2026). https://doi.org/10.1057/s41599-026-06508-5
Mots-clés: analyse de données qualitatives, analyse thématique, IA générative, modèles de langage open source, méthodes de recherche en sciences sociales