Clear Sky Science · fr
Évaluation systématique et recommandations pour le modèle Segment Anything dans l’analyse de vidéos chirurgicales
Pourquoi des outils vidéo intelligents comptent au bloc opératoire
La chirurgie moderne s’appuie de plus en plus sur la vidéo : de petites caméras explorent l’intérieur du corps pendant que les chirurgiens manipulent des instruments délicats à l’écran. Transformer ces vidéos riches mais désordonnées en cartes claires et annotées des instruments et des tissus pourrait rendre les opérations plus sûres, améliorer la formation et fiabiliser l’aide robotique future. Cette étude prend un nouveau système de vision polyvalent, initialement entraîné sur des vidéos du quotidien, et pose une question simple mais cruciale : peut‑il « voir » suffisamment bien à l’intérieur du corps humain pour être utile en chirurgie réelle — sans être réentraîné depuis zéro sur des données médicales coûteuses ? 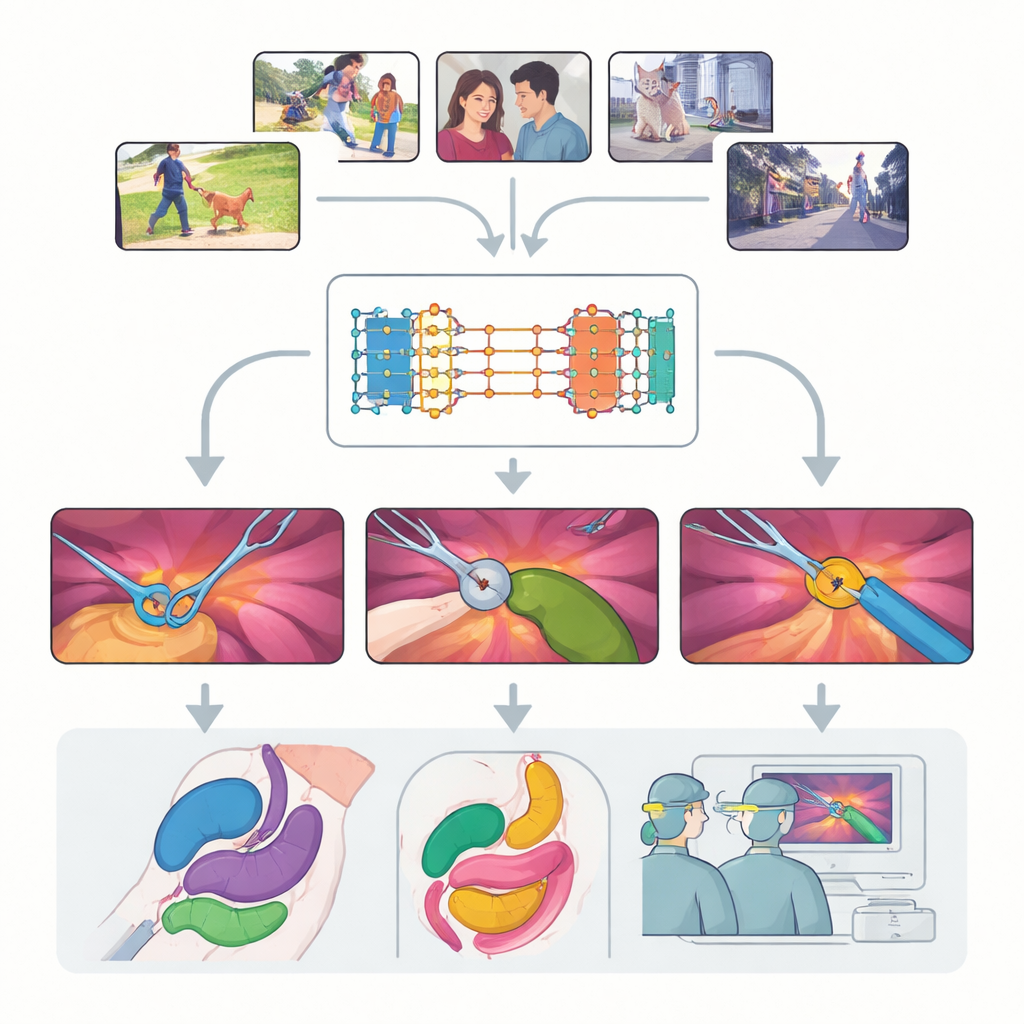
Un outil de vision flexible conçu pour n’importe quelle scène
Le travail se concentre sur le Segment Anything Model 2 (SAM2), un grand système d’IA conçu pour repérer des objets dans les vidéos dès qu’on lui donne un indice, ou « prompt », sur ce qu’il doit chercher. Contrairement aux modèles traditionnels qui apprennent des catégories fixes, SAM2 est agnostique aux classes : il ne distingue pas si un objet est un chien, une voiture ou une pince chirurgicale, pourvu que l’utilisateur le lui indique par un point, un cadre ou un masque d’exemple. Une avancée clé de SAM2 est sa banque de mémoire, qui conserve l’apparence d’un objet dans des images antérieures et utilise cette mémoire pour le suivre au fil du temps. Cela rend SAM2 particulièrement prometteur pour la vidéo chirurgicale, où les instruments entrent et sortent du champ et les tissus se déforment constamment.
Tester le modèle à travers de nombreuses interventions
Les auteurs réalisent une évaluation systématique à grande échelle de SAM2 sur neuf jeux de données divers couvrant dix‑sept types de procédures, de la cholécystectomie laparoscopique à la prostatectomie robotique en passant par l’endoscopie. Ils examinent trois défis majeurs : le suivi des instruments, la segmentation de plusieurs organes et la compréhension de scènes mêlant outils et tissus. Pour chacun, ils testent différentes manières de prompt‑er le modèle — points uniques, points multiples, boîtes englobantes et masques complets — et explorent à quelle fréquence les prompts doivent être rafraîchis au fil de la vidéo. Ils comparent également le modèle prêt à l’emploi avec plusieurs stratégies de léger réentraînement sur images chirurgicales pour mesurer jusqu’où la performance peut être améliorée sans nécessiter d’immenses jeux de données nouveaux.
Ce qui fonctionne le mieux à l’intérieur du corps
Dans l’ensemble, SAM2 s’avère étonnamment performant dans cet environnement peu familier. Sans réentraînement chirurgical, il segmente déjà de façon compétitive les instruments et de nombreux organes par rapport aux modèles médicaux spécialisés, surtout lorsqu’on lui fournit des prompts riches comme des boîtes ou des masques. Réinitialiser périodiquement les prompts toutes les 30 images — en rappelant essentiellement au système ce qui se trouve où — améliore nettement le suivi sur des clips longs et complexes. Lorsque les chercheurs ajustent uniquement certaines parties de SAM2, comme le module qui convertit les prompts en masques, la précision sur les scènes multi‑organes augmente fortement tout en gardant des besoins d’entraînement modestes. En revanche, tenter d’ajuster l’ensemble de l’encodeur d’image avec des données chirurgicales limitées peut en réalité nuire à la performance, ce qui suggère que la majorité des connaissances visuelles générales de SAM2 devrait rester intacte.
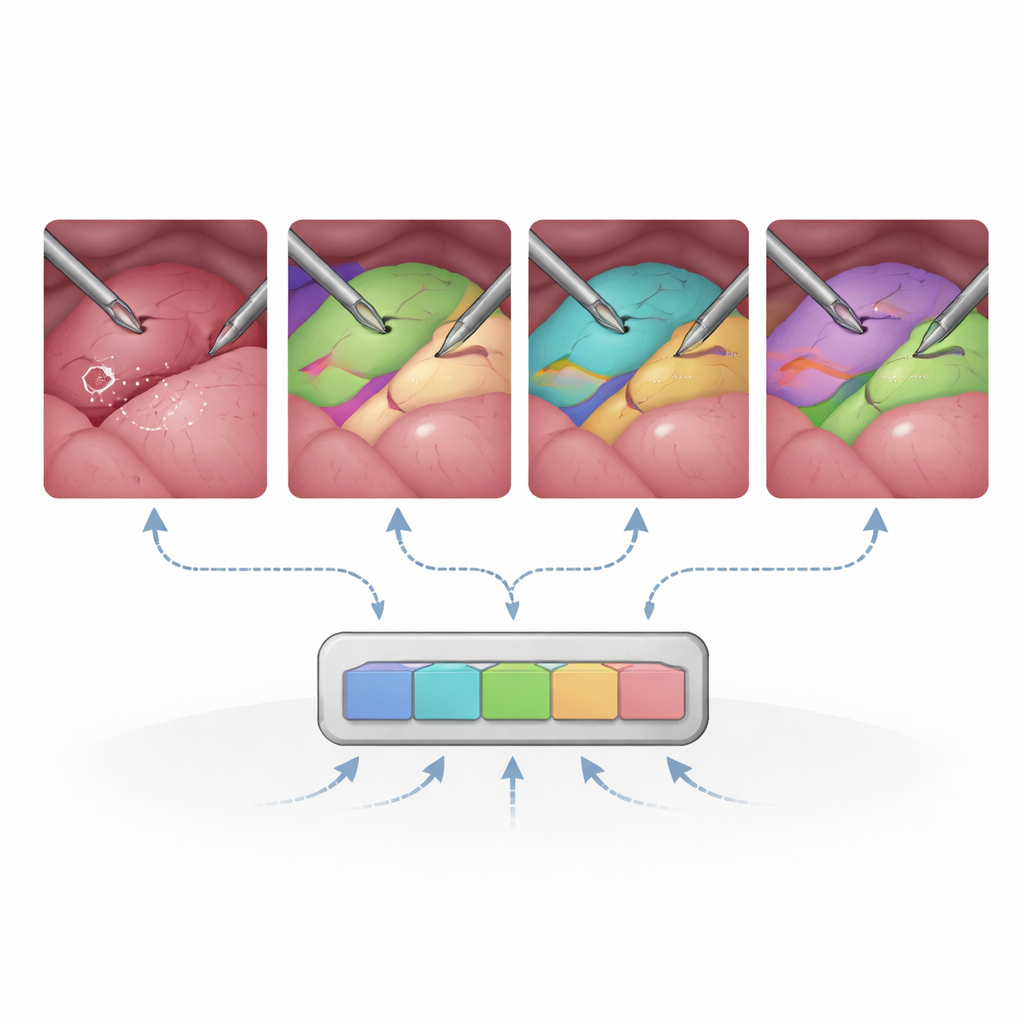
Limites dans des scènes chaotiques et très changeantes
L’étude met également en évidence des points faibles clairement identifiables. SAM2 peine lorsque le champ de vision est étroit, que l’image est bruitée ou mal éclairée, ou que les tissus manquent de contours nets, comme dans certaines procédures endoscopiques. Les structures ramifiées fines, comme les vaisseaux sanguins et les conduits, sont difficiles à dissocier lorsqu’elles se chevauchent ou partagent un contour général. L’utilisation de la mémoire vidéo n’aide pas toujours : dans des scènes très dynamiques avec des mouvements rapides de caméra, les indices temporels peuvent induire le modèle en erreur plutôt que de le stabiliser. Ces constats soulignent que, si un modèle fondamental généraliste peut aller loin, certaines réalités chirurgicales exigent encore un affinage spécifique au domaine et une meilleure gestion des variations d’apparence et de mouvement.
Recommandations pour les futurs systèmes chirurgicaux intelligents
À partir de ces tests étendus, les auteurs extraient des conseils pratiques pour les chercheurs et cliniciens souhaitant utiliser SAM2 dans des projets chirurgicaux. Ils recommandent de commencer par des prompts sous forme de masques ou de boîtes et par un simple affinage basé sur l’image ciblant le décodeur de masques, d’ajouter des rafraîchissements périodiques des prompts pour les longues vidéos, et de n’envisager des entraînements vidéo plus complexes que lorsque les scènes sont relativement stables. Ils montrent que même des clips annotés de façon parcellaire — seules quelques images annotées — peuvent suffire à adapter efficacement le modèle. En termes simples, la conclusion est encourageante : un modèle de vision unique et largement entraîné peut prendre en charge de nombreuses tâches de segmentation chirurgicale, réduisant fortement la nécessité de développer un outil spécifique pour chaque procédure. Avec des prompts soignés et une légère personnalisation, des systèmes comme SAM2 pourraient devenir des briques puissantes pour la prochaine génération de navigation, d’automatisation et d’outils de formation en chirurgie.
Citation: Yuan, C., Jiang, J., Yang, K. et al. Systematic evaluation and guidelines for segment anything model in surgical video analysis. npj Digit. Surg. 1, 2 (2026). https://doi.org/10.1038/s44484-025-00002-2
Mots-clés: analyse de vidéos chirurgicales, segmentation d’image, modèles fondamentaux, chirurgie assistée par ordinateur, IA médicale