Clear Sky Science · fr
Détecter le langage stigmatisant dans les notes cliniques avec de grands modèles de langage pour les soins en addictologie
Pourquoi les mots de votre dossier médical comptent
À mesure que davantage de patients accèdent en ligne à leur dossier médical, le langage employé par les cliniciens n’est plus caché dans les ordinateurs des hôpitaux : il est visible par les personnes mêmes qu’il décrit. Pour les personnes vivant avec une addiction, une seule expression comme « se drogue » ou « toxicomane » peut discrètement renforcer la honte, nuire à la confiance et même influencer les soins qu’elles reçoivent. Cette étude pose une question d’actualité : l’intelligence artificielle moderne peut-elle aider les hôpitaux à repérer et réduire le langage stigmatisant dans les notes cliniques avant qu’il ne fasse du tort aux patients ?

Des étiquettes néfastes cachées dans des notes quotidiennes
La stigmatisation dans les soins de santé ne se manifeste pas seulement dans le contact visuel ou le ton de la voix ; elle est aussi inscrite dans le dossier écrit. Les dossiers de santé électroniques contiennent des millions de notes qui accompagnent les patients à travers cliniques et hôpitaux. Des termes tels que « abus d’alcool » ou « comportement cherchant des drogues » peuvent façonner la façon dont des cliniciens ultérieurs perçoivent une personne, bien après une visite aux urgences ou une hospitalisation. Les chercheurs se sont concentrés sur les notes en unité de soins intensifs concernant des patients ayant des problèmes d’usage de substances, où les enjeux sont élevés et la documentation abondante. Ils sont partis de recommandations nationales qui encouragent un langage respectueux et centré sur la personne, comme « personne souffrant d’un trouble lié à l’usage de substances » plutôt que « accro », et ont utilisé ces principes pour créer un large jeu de données de notes étiquetées comme stigmatisantes ou non.
Apprendre à une IA à lire entre les lignes
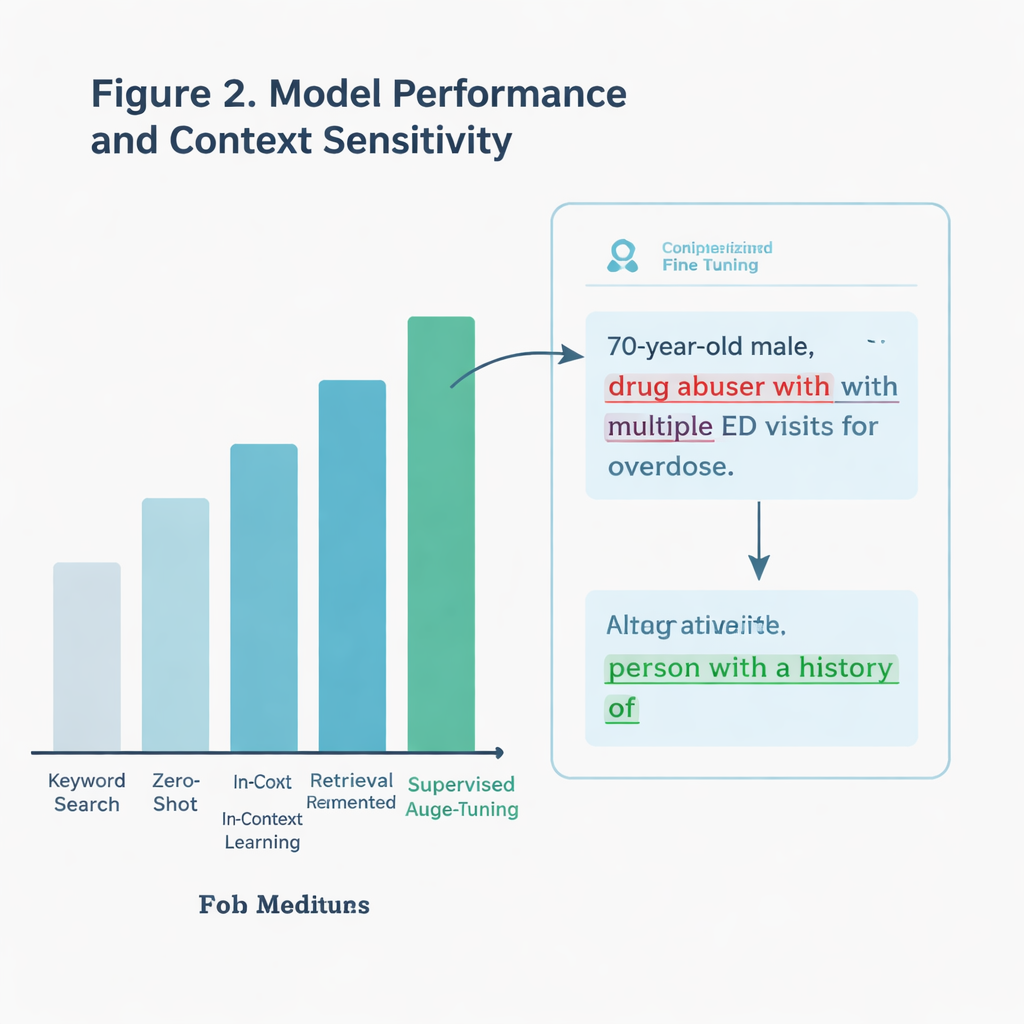
Plutôt que de se contenter de repérer des gros mots, l’équipe souhaitait un système d’IA capable de comprendre le contexte. Par exemple, une note peut citer un patient se décrivant comme « ivre », ce qui n’est pas équivalent au fait qu’un clinicien applique cette étiquette. Les auteurs ont comparé plusieurs approches, toutes basées sur un grand modèle de langage (un type d’IA qui traite et génère du texte). Une méthode basique ne cherchait que des mots-clés spécifiques tirés des recommandations. Des méthodes plus avancées demandaient à l’IA de juger chaque note directement, soit sans exemples supplémentaires, soit avec des consignes issues des bonnes pratiques en communication, soit après un entraînement spécialisé — ou « fine-tuning » — sur des milliers de notes d’unité de soins intensifs étiquetées.
Ce qui a le mieux fonctionné dans la pratique
Le modèle affiné a été le vainqueur clair. Sur un ensemble de test tenu à l’écart de plus de 11 000 notes, il a correctement identifié un langage stigmatisant dans environ 97 % des cas, bien mieux qu’une simple recherche par mots-clés. Il a également mieux résisté sur un sous-ensemble particulièrement délicat de notes contenant des termes potentiellement chargés mais pas toujours utilisés de manière préjudiciable. Le modèle savait distinguer les phrases véritablement jugementales des usages neutres ou cités, là où une recherche plus rustique échouerait. Lorsque l’équipe a testé le système sur des notes provenant d’un autre établissement de santé — près de 300 000 notes de soins intensifs rédigées dans un autre État — il a encore surpassé l’approche par mots-clés, même si le langage stigmatisant était rare dans cet échantillon du monde réel.
Détecter de nouvelles expressions problématiques que les cliniciens ont manquées
Les chercheurs sont allés plus loin et ont demandé à l’IA d’expliquer pourquoi elle avait signalé certaines notes. Un spécialiste des addictions a ensuite revu ces explications. Dans des dizaines de cas, les modèles ont mis en évidence des formulations véritablement stigmatisantes que les annotateurs humains avaient initialement négligées, y compris des expressions absentes des recommandations existantes. On trouve par exemple des descriptions comme « comportement de recherche de drogues » ou des mentions banales de « cirrhose alcoolique » qui blâment subtilement la personne plutôt que la maladie. Cela suggère que des outils d’IA bien conçus pourraient non seulement appliquer les meilleures pratiques actuelles, mais aussi aider à élargir notre compréhension de ce à quoi ressemble un langage nuisible à mesure que l’écriture clinique évolue.
De l’outil de recherche à l’aide au chevet
L’étude a également pris en compte des aspects pratiques. La recherche par mots-clés est ultrarapide mais superficielle. Le modèle d’IA le plus précis a nécessité plusieurs heures d’entraînement sur des processeurs graphiques puissants, mais une fois entraîné il pouvait analyser des notes en quelques secondes chacune — lent pour un moteur de recherche, mais acceptable pour un assistant de fond dans un système hospitalier. Une autre approche, moins personnalisée et reposant uniquement sur des invites soigneusement rédigées, a donné des résultats raisonnables sans entraînement supplémentaire, laissant entrevoir des options plus légères pour des cliniques disposant de moins de ressources techniques. Ensemble, ces résultats pointent vers des systèmes capables de signaler en temps réel des formulations risquées et de proposer des alternatives plus respectueuses pendant que les cliniciens saisissent leurs notes.
Un pas vers des soins plus respectueux
Pour un lecteur non spécialisé, la conclusion principale est simple : les mots de votre dossier ne sont pas que du jargon technique ; ils contribuent à façonner la manière dont vous êtes traité. Ce travail montre que les grands modèles de langage peuvent repérer de façon fiable de nombreuses formes de langage stigmatisant liées à l’addiction dans les notes de soins intensifs, même lorsque le problème est subtil. Aucun système n’est parfait, mais de tels outils pourraient servir d’éditeurs toujours actifs, incitant les cliniciens à employer un langage qui reconnaît les personnes comme étant plus que leurs diagnostics. À long terme, ce changement — du blâme au respect — pourrait être aussi important pour la guérison que n’importe quel médicament ou dispositif.
Citation: Sethi, R., Caskey, J., Gao, Y. et al. Detecting stigmatizing language in clinical notes with large language models for addiction care. npj Health Syst. 3, 15 (2026). https://doi.org/10.1038/s44401-026-00069-0
Mots-clés: stigmatisation de l'addiction, notes cliniques, grands modèles de langage, dossiers de santé électroniques, langage axé sur la personne