Clear Sky Science · fr
Cadre explicable de raisonnement d'attribution multi-granularité pour la détection de fausses informations
Pourquoi repérer les fausses informations devient plus difficile
Chaque jour, des millions de publications mêlant texte et images circulent sur les réseaux sociaux. Certaines sont inoffensives, certaines sont vraies, et d'autres sont des faux soigneusement conçus pour attirer l'attention, susciter des émotions ou influencer l'opinion. À mesure que les outils de retouche d'images et les générateurs d'IA deviennent moins coûteux et plus faciles à utiliser, les fausses informations gagnent en raffinement et en dangerosité. Cet article présente une nouvelle façon d'examiner les systèmes de détection de fausses informations afin que l'on puisse non seulement savoir si une publication est probablement fausse, mais aussi comprendre pourquoi.
Comment les fausses informations trompent nos yeux et notre esprit
Les créateurs de faux exploitent la manière dont les gens parcourent rapidement titres et images. Ils peuvent falsifier ou retoucher des photos, mêler des éléments partiellement vrais à une histoire impossible, assembler des morceaux provenant d'événements différents, ou mélanger lieux et chronologies qui n'ont pas lieu d'être. Une publication unique sur un événement récent peut afficher une image dramatique issue d'un incident différent survenu des années auparavant, ou une photo convaincante peut être entièrement générée par l'IA. Les systèmes traditionnels de détection traitent en général toutes les publications frauduleuses de la même manière et fondent leur jugement sur une « soupe de caractéristiques » qui fusionne texte et image. Cette approche peut fonctionner raisonnablement bien, mais elle agit comme une boîte noire : il est difficile pour les journalistes, les plateformes ou les utilisateurs ordinaires de comprendre les indices précis qui ont déclenché l'alerte.
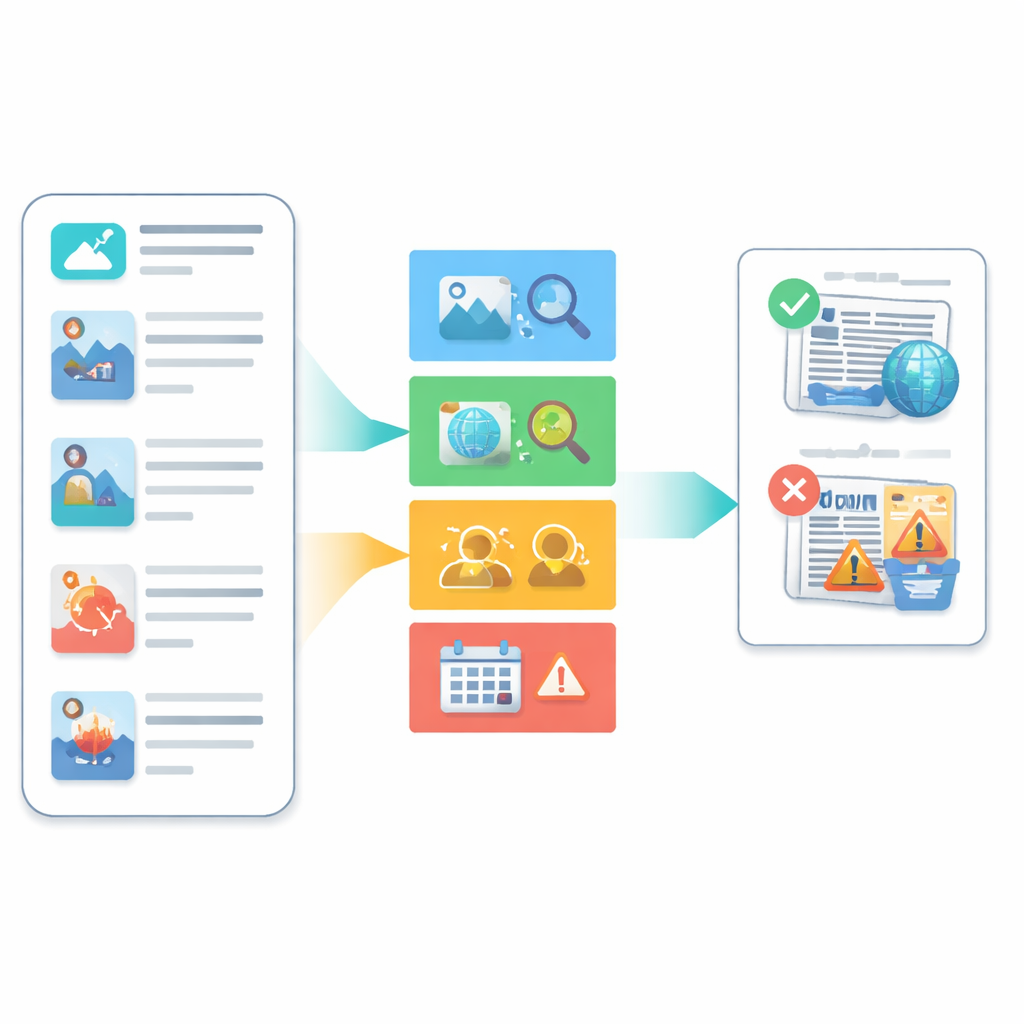
Une nouvelle manière de demander : « Pourquoi ceci est‑il faux ? »
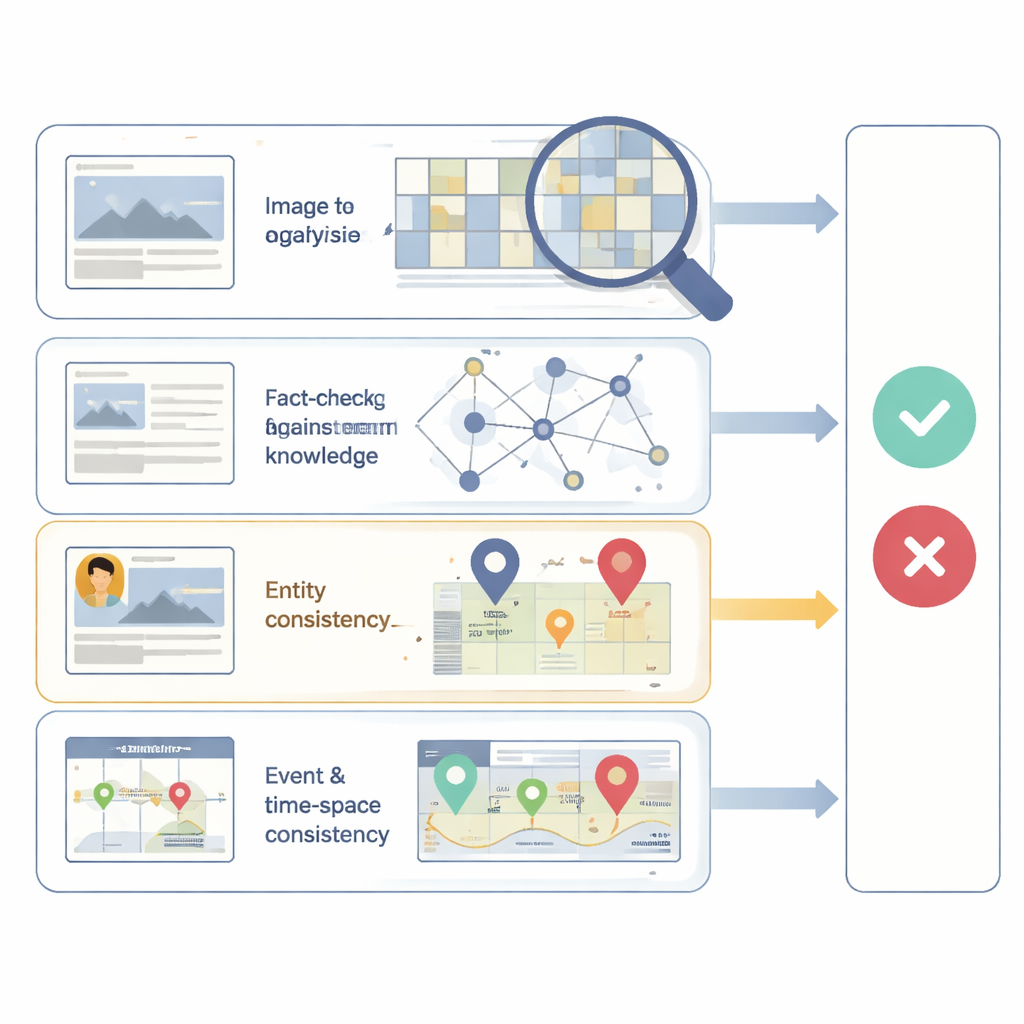
Les auteurs proposent un cadre explicable appelé EMAR‑FND qui examine les publications d'actualité sous quatre angles distincts, chacun lié à une façon courante de fabriquer des faux. Premièrement, il analyse si l'image elle‑même présente des signes de falsification ou de génération synthétique, en se concentrant sur de subtiles signatures de bruit au niveau de l'appareil qui changent lorsqu'une image est modifiée. Deuxièmement, il vérifie si les faits de l'histoire s'alignent avec des connaissances externes fiables, par exemple les relations connues entre personnes, lieux et événements. Troisièmement, il examine si les entités clés mentionnées dans le texte — comme une personnalité publique ou une ville — correspondent effectivement à ce qui apparaît sur l'image accompagnante. Quatrièmement, il évalue si l'événement décrit tient ensemble dans le temps et l'espace, par exemple en repérant une discordance entre un lieu revendiqué et des indices visuels sur la photo, ou entre une chronologie rapportée et d'autres preuves.
Assembler des indices depuis plusieurs angles
Chacun de ces quatre contrôles est géré par son propre module de raisonnement, qui porte un jugement partiel sur la fiabilité de cet aspect spécifique. Un module se concentre sur la falsification visuelle ; un autre raisonne à partir de graphes de connaissances externes ; un troisième construit un réseau riche reliant mots, objets de l'image et événements extraits ; et un quatrième compare la publication avec des preuves connexes dans le temps et l'espace. Plutôt que de cacher ces signaux dans une représentation fusionnée unique, EMAR‑FND conserve leurs contributions séparées puis les combine via une étape de décision finale capable de pondérer l'importance de chaque point de vue pour un cas donné. Le résultat n'est pas seulement un score final vrai‑ou‑faux, mais aussi une attribution montrant, par exemple, qu'une publication est signalée principalement parce que l'image semble falsifiée, ou parce que l'événement décrit ne correspond à aucun fait connu.
Tester le système en conditions réelles
Pour évaluer l'efficacité de cette approche, les chercheurs ont appliqué EMAR‑FND à deux corpus publics de publications réelles et fausses incluant à la fois texte et images. Sur ces jeux de données, leur méthode a surpassé plusieurs systèmes existants performants, obtenant une meilleure précision et un meilleur équilibre entre la détection des publications fausses et l'évitement des faux positifs. Lorsqu'ils ont examiné la façon dont les publications se regroupaient à l'intérieur du modèle, les informations réelles formaient des groupes serrés et cohérents, tandis que les fausses informations étaient plus dispersées — reflet des nombreuses ruses employées par les faussaires. Les sorties d'attribution se sont également révélées utiles dans des exemples difficiles du monde réel : des publications où texte et image semblaient cohérents au premier coup d'œil ont été exposées comme fausses soit parce que l'image montrait des traces de manipulation cachées, soit parce que des connaissances externes contredisaient les faits revendiqués.
Ce que cela signifie pour les lecteurs quotidiens
En termes simples, l'étude montre qu'il est possible de concevoir des détecteurs de fausses informations qui se comportent moins comme des oracles et davantage comme des enquêteurs attentifs. Plutôt que de fournir une réponse sèche oui‑ou‑non, EMAR‑FND met en évidence quelle partie d'une publication est suspecte : l'image, les faits, les personnes mentionnées ou l'événement lui‑même. Ce type d'explication peut aider les vérificateurs de faits, les plateformes et les lecteurs à faire confiance aux décisions du système et à apprendre à reconnaître les schémas courants de tromperie. À mesure que les fausses informations évoluent, des outils capables à la fois de détecter et d'expliquer la manipulation seront cruciaux pour préserver des écosystèmes d'information en ligne plus sains et plus transparents.
Citation: Ji, W., Lv, H., Zhao, H. et al. Explainable multi-granularity attribution reasoning framework for fake news detection. npj Artif. Intell. 2, 38 (2026). https://doi.org/10.1038/s44387-026-00093-3
Mots-clés: détection de fausses informations, désinformation multimodale, IA explicable, intégrité des réseaux sociaux, analyse de falsification d'images