Clear Sky Science · fr
Miroir magique 3D : reconstruction de vêtements à partir d’une seule image via une perspective causale
Essayer des vêtements sans cabine d’essayage
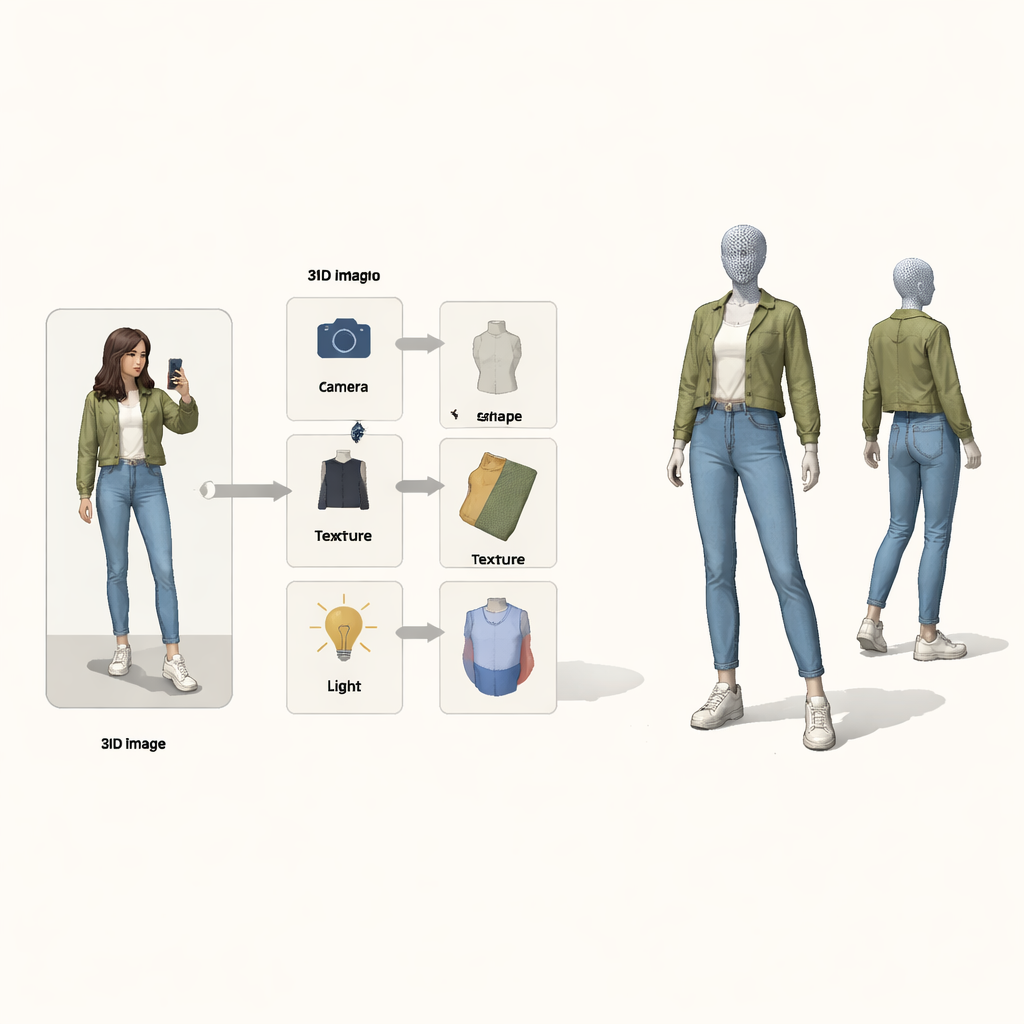
Imaginez prendre une seule photo en pied avec votre téléphone et vous voir instantanément en 3D, pouvoir faire tourner l’image, changer de point de vue ou même échanger des tenues avec un ami. Cet article traite du problème technique central derrière ce « miroir magique 3D » : transformer une photo 2D ordinaire d’une personne habillée en un modèle 3D détaillé de ses vêtements, sans dépendre de scans 3D coûteux ni de photos en studio contrôlées.
Pourquoi transformer des photos 2D en 3D est si difficile
Faire passer une image plate à un objet 3D est un casse-tête classique. Les systèmes existants partent souvent d’un gabarit corporel numérique fixe qu’ils déforment pour l’ajuster à la photo. Cela fonctionne assez bien pour des parties rigides du corps comme les bras et les jambes, mais échoue pour des robes fluides, des manteaux drapés, des cheveux ou des sacs à main, qui ne suivent pas une forme simple et standard. Un autre obstacle est les données : il existe des millions de photos de mode sur le web, mais presque aucune grande collection de vêtements 3D précisément mesurés pour l’apprentissage. Enfin, une seule photo dissimule des informations importantes. Un petit manteau proche de la caméra peut paraître identique à un manteau plus grand éloigné, et l’éclairage ou les motifs du tissu peuvent aussi tromper un algorithme d’apprentissage. Ces ambiguïtés rendent difficile pour un réseau de neurones de « deviner » la bonne structure 3D.
Apprendre à l’IA à séparer cause et effet
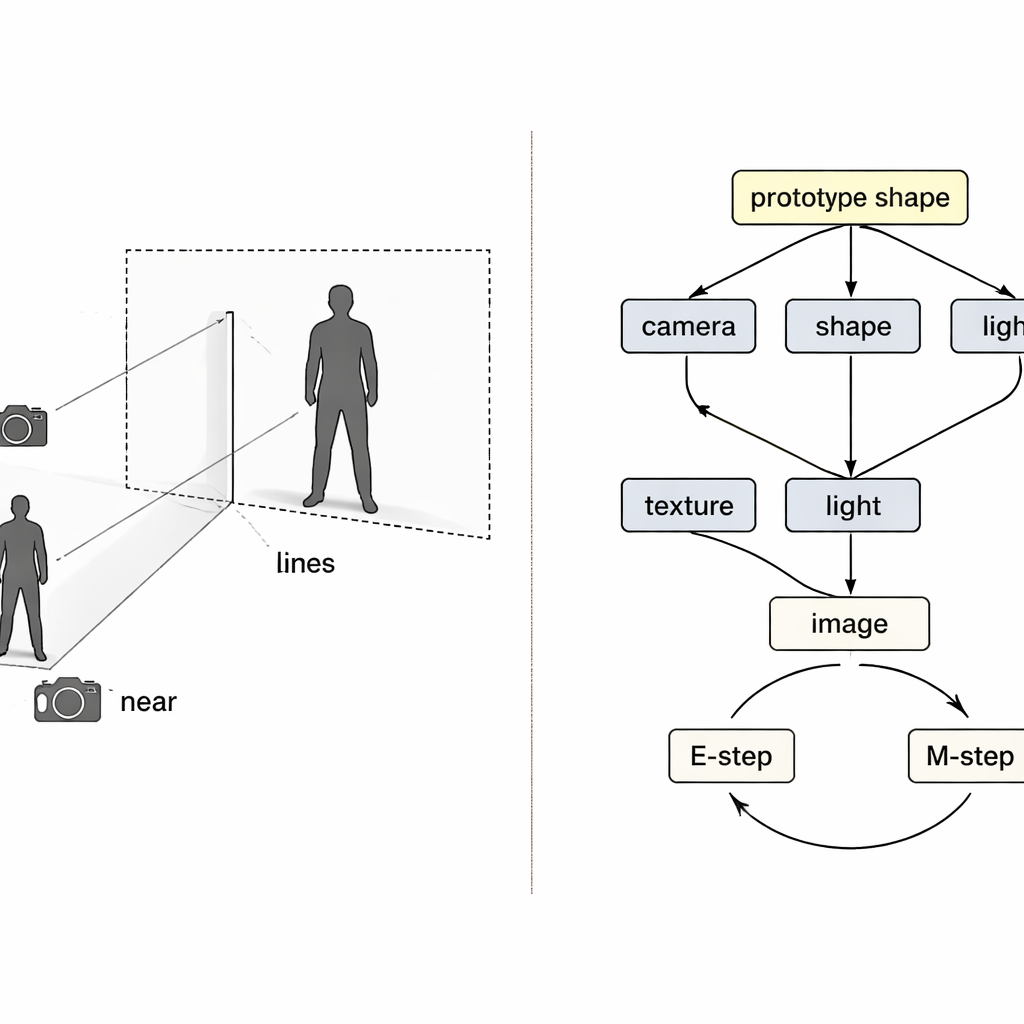
Plutôt que de traiter le problème comme une boîte noire transformant des pixels en 3D, les auteurs empruntent des idées au raisonnement causal — les mathématiques de la cause et de l’effet. Ils considèrent l’image finale comme le résultat de quatre causes cachées : la position de la caméra, la forme du vêtement, sa texture (couleurs et motifs) et l’éclairage. Une « carte causale structurelle » spéciale décrit comment ces facteurs se combinent pour produire l’image observée. Guidé par cette carte, le système utilise quatre encodeurs neuronaux séparés, chacun responsable d’un facteur. Avec un rendu 3D inspiré de la physique, ils forment une boucle : image et masque de premier plan entrent, un maillage 3D coloré en sort, puis il est projeté en arrière vers une image qui peut être comparée à l’original.
Une boucle d’apprentissage qui corrige un élément à la fois
Même avec des encodeurs séparés, l’entraînement peut mal tourner. Si la reconstruction est imparfaite, il est difficile de savoir quel encodeur est en faute, et l’apprentissage ordinaire a tendance à ajuster tous les composants en même temps. Les auteurs traitent cela comme un problème classique de « collider » en causalité, où différentes causes peuvent compenser à tort les unes pour les autres. Leur solution est d’entrelacer deux boucles d’espérance–maximisation dans l’entraînement. Dans la première boucle, trois encodeurs sont temporairement figés tandis que le quatrième est mis à jour seul, de sorte que les erreurs sont clairement attribuées et que ce composant apprend un rôle plus propre. Dans la seconde boucle, une forme 3D « prototype » partagée — commençant comme une simple sphère — est mise à jour lentement pour devenir la forme moyenne humaine ou d’oiseau dans les données. Les exemples individuels n’apprennent que de petites déviations par rapport à ce prototype, tandis que le module caméra prend la pleine responsabilité de la façon dont l’objet paraît grand ou proche, attaquant directement la confusion taille-vers-distance.
Des photos de mode aux oiseaux, et au-delà
Pour tester leur approche, les chercheurs s’entraînent sur deux grands jeux de données de mode contenant des photos de rue ordinaires et sur une collection standard d’images d’oiseaux. Fait important, ils n’utilisent que des masques de premier plan 2D, pas de maillages 3D de référence. Sur les vêtements humains, leur système dépasse les méthodes populaires basées sur des gabarits corporels pour correspondre au contour réel des vêtements et gère de manière plus fidèle les éléments non rigides comme les cheveux et les sacs. Sur les oiseaux, il atteint ou dépasse la qualité des meilleures méthodes de reconstruction 3D à partir d’une seule image tout en produisant des points de vue nouveaux plus réalistes. Les modèles 3D sont suffisamment flexibles pour soutenir des applications ludiques, comme l’échange de textures de vêtements entre personnes ou la génération de données synthétiques pour améliorer les systèmes de ré-identification de personnes utilisés dans la recherche en surveillance.
Ce que cela change pour les mondes numériques quotidiens
Pour les non-spécialistes, le message clé est que des avatars 3D convaincants et des outils d’essayage virtuel ne nécessitent plus des scanners 3D coûteux ni des gabarits rigides. En modélisant explicitement cause et effet — en séparant caméra, forme, texture et lumière, et en les ancrant à un prototype partagé — les auteurs montrent comment un système peut « expliquer » une seule photo comme une scène 3D. Bien que la méthode ait encore des difficultés avec des vues qu’elle n’a jamais vues, comme le dos d’une personne photographiée seulement de face, elle marque une avancée significative vers des miroirs magiques 3D pratiques qui fonctionnent sur les images « in-the-wild » et désordonnées que nous prenons réellement.
Citation: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Mots-clés: essayage virtuel, reconstruction 3D, apprentissage causal, vision par ordinateur, IA pour la mode