Clear Sky Science · fr
Attention visuelle humaine et algorithmique dans les tâches de conduite
Pourquoi cela compte pour la conduite de tous les jours
Alors que les voitures deviennent de plus en plus automatisées, une question clé demeure : les systèmes de conduite autonomes « voient-ils » vraiment la route comme les humains ? Cette étude examine comment les conducteurs humains et l’intelligence artificielle dirigent leur attention visuelle dans la circulation, et montre qu’ajouter soigneusement une portion d’attention de type humain peut rendre les algorithmes de conduite à la fois plus intelligents et plus sûrs — sans nécessiter de modèles d’IA gigantesques et énergivores.
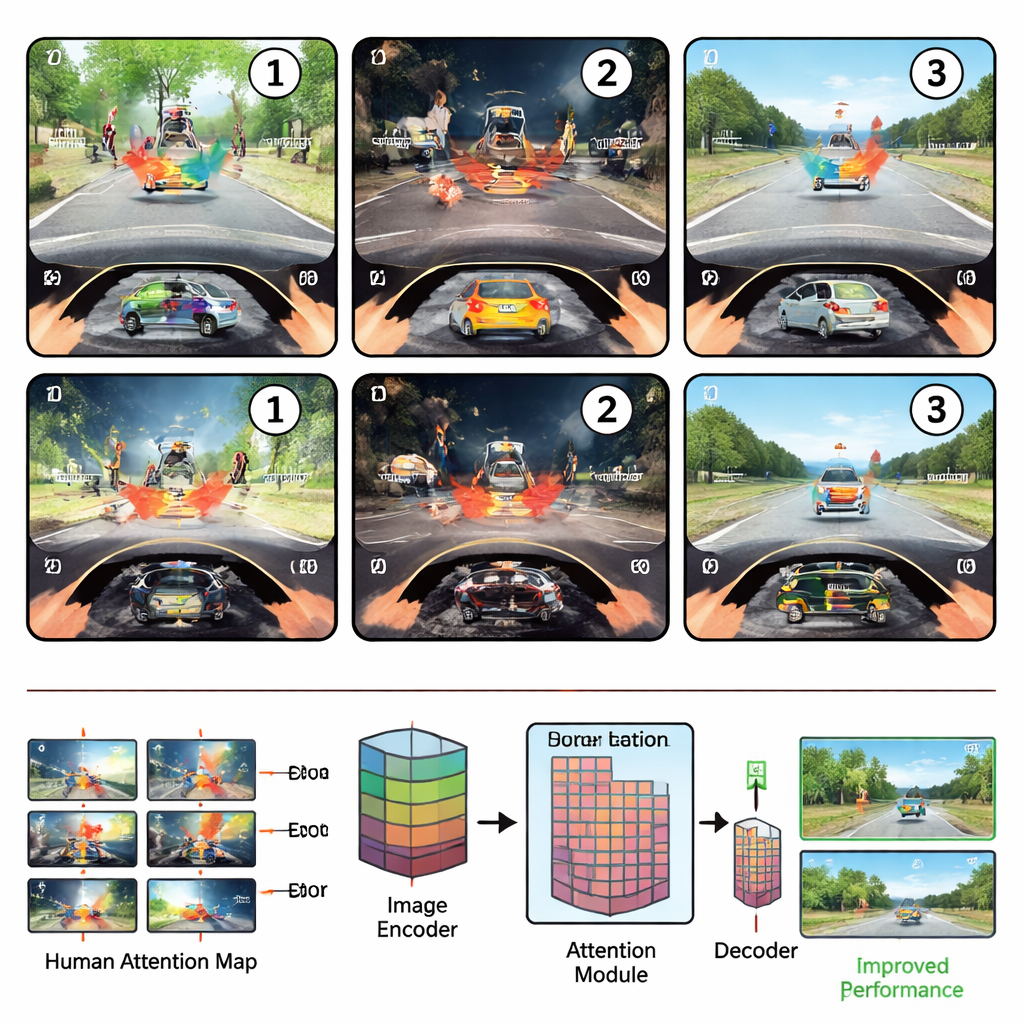
Comment les yeux humains se déplacent sur la route
Les chercheurs ont d’abord placé des conducteurs débutants et expérimentés dans un environnement de conduite simulé et ont suivi leurs mouvements oculaires pendant qu’ils accomplissaient trois tâches de sécurité courantes : repérer des dangers, juger s’il était sûr de tourner ou de changer de voie, et détecter des objets étranges ou hors de propos. Ils ont constaté que l’attention des conducteurs suivait un rythme fiable en trois étapes. Dans la phase de balayage, juste après l’apparition d’une scène, les yeux scrutent largement la vue, guidés principalement par l’emplacement des éléments. Dans la phase d’examen, l’attention se fixe sur la région la plus informative — par exemple un piéton traversant ou une voiture obstruante — et en étudie les détails et la signification. Enfin, dans la phase de réévaluation, les conducteurs comparent cet objet clé à d’autres, déplaçant leur regard d’avant en arrière pour confirmer leur décision.
Où les machines regardent versus où regardent les personnes
L’équipe a ensuite construit un modèle d’apprentissage profond basé sur l’attention pour des scènes de conduite et a comparé ses « cartes d’attention » internes à celles issues des mouvements oculaires humains. En entraînant le modèle à la détection générale d’objets, son attention devenait quelque peu plus humaine, mais le réglage fin pour des tâches de conduite spécifiques l’éloignait souvent des schémas humains, surtout pendant la riche phase d’examen centrée sur le sens. Globalement, les corrélations entre l’attention humaine et algorithmique sont restées modestes, ce qui suggère que l’IA de conduite actuelle a du mal à découvrir les principes organisateurs expliquant où les humains regardent et pourquoi.
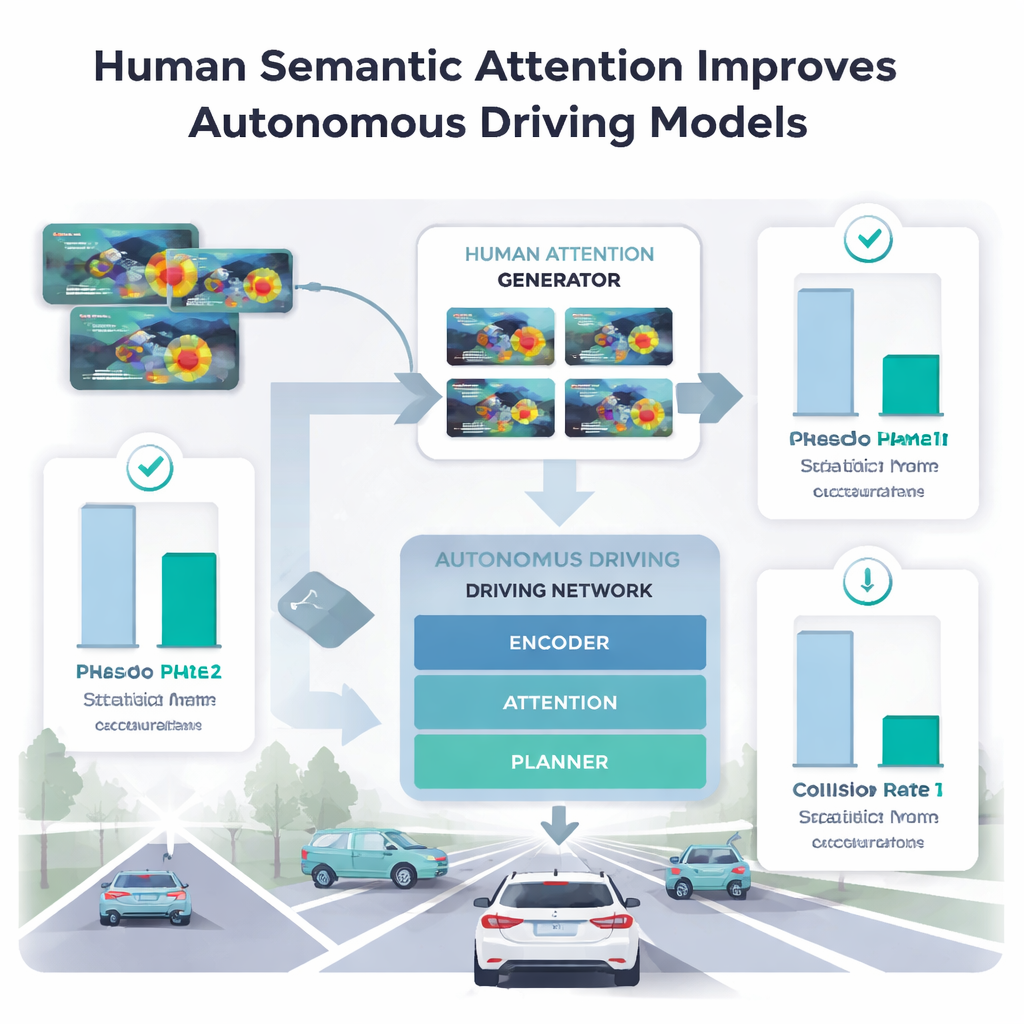
Apprendre aux voitures à emprunter le focus humain
Pour déterminer quelles parties de l’attention humaine aident vraiment les machines, les auteurs ont injecté différentes phases du regard humain dans leur modèle de conduite. Collecter directement des données de suivi oculaire pour des millions d’images est impraticable, ils ont donc entraîné un « générateur d’attention humaine » séparé sur un petit échantillon provenant de seulement cinq conducteurs. Ce générateur a appris à prédire des cartes de chaleur d’attention de type humain pour de nouvelles scènes. Quand le modèle principal de conduite utilisait uniquement la phase spatiale et précoce de balayage, ses performances en détection d’anomalies et en planification de trajectoire se sont souvent dégradées ou ont produit des trajectoires apparemment plus sûres mais plus sujettes aux collisions. En revanche, lorsqu’il utilisait la phase d’examen — où les humains se concentrent sur la région la plus significative — la précision s’est améliorée au-delà des méthodes précédentes qui exploitaient le regard sur toute la durée, et les taux de collision dans les tâches de planification ont diminué.
Ce que les grands modèles vision–langage manquent encore
Les chercheurs ont aussi testé de grands modèles vision–langage qui répondent à des questions de conduite ou génèrent des légendes denses pour des scènes de rue 3D. Pour une tâche de question-réponse qui met l’accent sur le raisonnement de haut niveau, l’ajout de l’attention humaine a à peine aidé et a parfois nui, ce qui implique que ces modèles capturent déjà une grande partie des connaissances abstraites nécessaires. Mais pour une tâche de légende exigeante, qui requiert d’assigner des mots précis à des objets précis, l’attention humaine de la phase d’examen a encore apporté de grands bénéfices. Cela suggère que les grands modèles raisonnent bien en général, mais butent encore lorsqu’il faut lier étroitement des mots à des emplacements exacts dans une scène visuelle encombrée — un fossé que le regard humain peut aider à combler.
Ce que cela signifie pour des voitures autonomes plus sûres
En termes simples, l’étude soutient que ce qui sépare réellement les humains de l’IA de conduite actuelle n’est pas seulement où nous regardons, mais comment nous jugeons instantanément ce qui importe dans une scène. Cette rafale compacte d’attention sémantique — quand nous scrutons la région qui rend une situation sûre ou dangereuse — s’avère être précisément le signal qui manque à de nombreux algorithmes. En apprenant à imiter cette phase à partir d’une petite quantité de données de suivi oculaire, les systèmes de conduite peuvent acquérir une compréhension des scènes routières proche de celle des humains sans se reposer uniquement sur des modèles d’IA toujours plus grands et coûteux. Ce « raccourci sémantique » pourrait être un moyen efficace de rendre les futures voitures automatisées plus fiables dans les conditions chaotiques et imprévisibles du trafic réel.
Citation: Zheng, C., Li, P., Jin, B. et al. Human and algorithmic visual attention in driving tasks. npj Artif. Intell. 2, 23 (2026). https://doi.org/10.1038/s44387-026-00079-1
Mots-clés: conduite autonome, attention visuelle, suivi oculaire humain, modèles vision-langage, sécurité routière