Clear Sky Science · fr
Le rôle des grands modèles de langage dans les soins d’urgence : une étude de référence complète
Pourquoi cela compte pour toute personne susceptible de se rendre aux urgences
Les services d’urgence sont plus sollicités que jamais, avec des temps d’attente plus longs et moins de personnel pour prendre en charge un nombre croissant de patients gravement malades. Cette étude pose une question qui concerne presque tout le monde : les systèmes d’IA modernes, appelés grands modèles de langage, peuvent‑ils aider de manière sûre les médecins et les infirmiers à travailler plus vite et plus intelligemment en service d’urgence ? En soumettant plusieurs IA de pointe à une série de tests médicaux et de cas simulés d’urgences, les chercheurs explorent dans quelle mesure ces outils se rapprochent d’un statut de « copilote » de confiance pour les soins urgents.
Des services d’urgence sous pression intense
L’article commence par décrire une crise croissante dans les soins d’urgence, en particulier aux États‑Unis. Le vieillissement de la population et l’augmentation des maladies chroniques entraînent un nombre record de visites aux urgences, atteignant environ 155 millions rien qu’en 2022. Dans le même temps, les hôpitaux font face à de graves pénuries d’infirmiers et de médecins, et le nombre de lits par habitant a diminué au fil des décennies. Un système de santé fragmenté rend la coordination des soins plus difficile, augmentant le risque de retards et d’erreurs. Dans ce contexte, les auteurs soutiennent que de nouveaux outils sont urgemment nécessaires pour aider les cliniciens à trier les patients, prendre des décisions rapides et documenter les soins sans alourdir leur charge de travail.
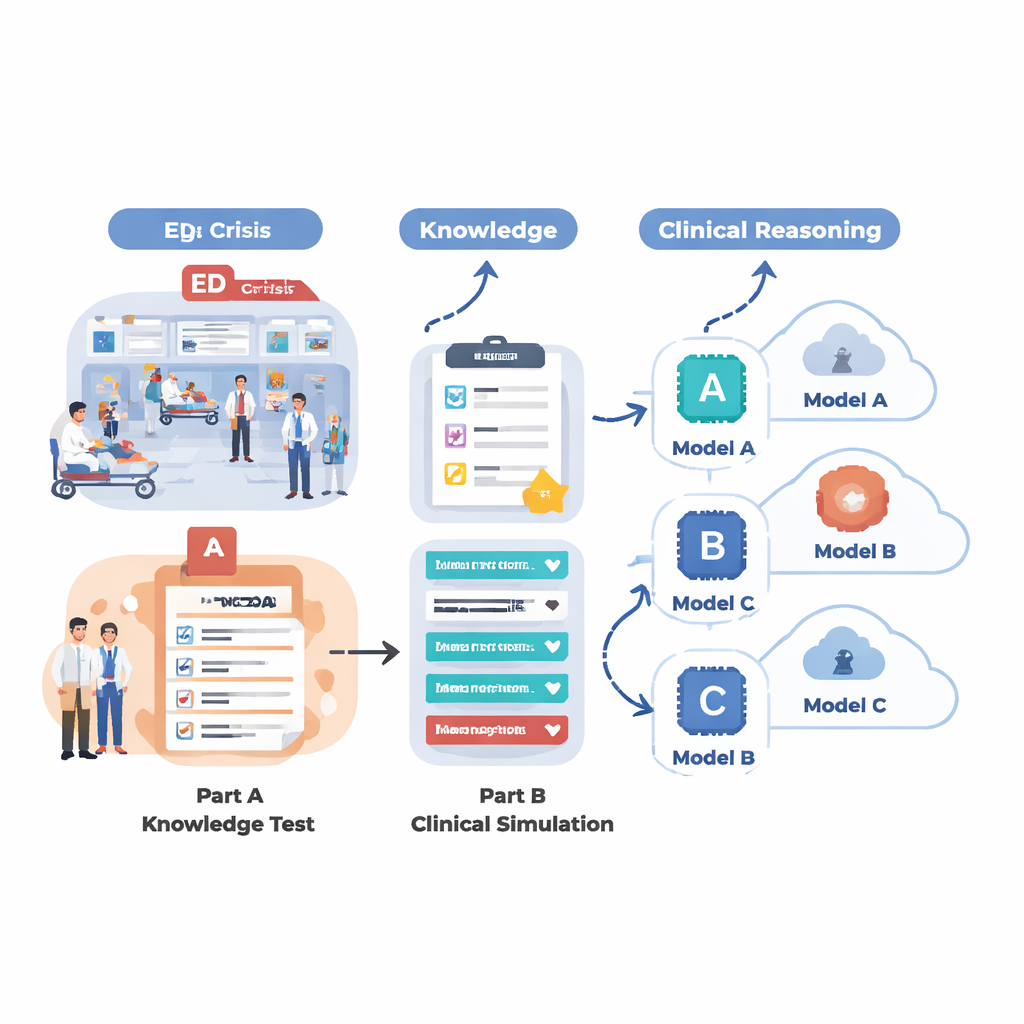
Comment les chercheurs ont testé l’IA médicale
Pour évaluer ce que les systèmes d’IA actuels peuvent réellement faire en contexte proche de l’urgence, l’équipe a conçu une évaluation en deux volets. D’abord, ils ont testé 18 modèles de langage différents sur un vaste ensemble de questions à choix multiple tirées de MedMCQA, une base de données de type examen médical couvrant 12 motifs fréquents en urgence, tels que douleur thoracique, dyspnée, céphalée et douleur abdominale. Cette phase mesurait les connaissances médicales de base : l’IA pouvait‑elle choisir la bonne réponse parmi quatre options sur des milliers de questions ? Ensuite, les cinq modèles les plus performants de cette première phase ont été invités à traiter 12 cas réalistes d’urgence, étape par étape, comme le ferait un médecin. Pour chaque cas, l’IA devait résumer le patient, attribuer un score d’urgence pour le triage, proposer les questions de suivi clés, suggérer des étapes de prise en charge et lister les diagnostics probables au fur et à mesure que de nouvelles informations (constantes vitales, antécédents, examen, résultats de laboratoire et d’imagerie) étaient progressivement révélées.
Quels modèles connaissaient les faits — et lesquels savaient raisonner
Sur la simple restitution factuelle, plusieurs modèles ont obtenu des résultats impressionnants. Un système spécialisé appelé LLaMA 4 Maverick a obtenu environ 91 % de précision globale sur les questions médicales, suivi de près par LLaMA 3.1, GPT‑4.5, GPT‑5 et Claude 4. Ces modèles de tête étaient régulièrement performants selon les différents motifs principaux, suggérant que les IA de pointe approchent peut‑être un plafond pour les connaissances médicales de type manuel scolaire. Les systèmes de milieu de gamme étaient nettement à la traîne, certains atteignant environ 60 % et rencontrant des difficultés dans des domaines clés comme les soins des plaies et les problèmes respiratoires. Cependant, lorsque la tâche est passée de la réponse à des questions isolées au raisonnement à travers des récits patients riches et évolutifs, les différences se sont accentuées. Dans ces simulations cliniques, GPT‑5 s’est nettement distingué : il a produit les résumés les plus précis et complets, posé les questions de suivi les plus utiles, recommandé des étapes suivantes judicieuses et sûres, et fourni les listes de diagnostics possibles les plus exhaustives et bien ordonnées.
Forces, faiblesses et problèmes de sécurité
Des cliniciens ont évalué soigneusement chaque sortie d’IA selon l’exactitude, la pertinence et la sécurité. GPT‑5 n’a pas seulement obtenu les meilleurs scores globaux ; c’était également le seul modèle dont les performances sont restées stables ou se sont améliorées à mesure que les cas devenaient plus complexes, tout en maintenant les hallucinations et les erreurs graves en dessous d’environ 2 %. D’autres modèles ont montré des schémas de faiblesse distincts. Certains avaient tendance à manquer des diagnostics secondaires ou à privilégier des problèmes mineurs au détriment de situations dangereuses. D’autres devenaient excessivement prudents ou vagues, ou se focalisaient trop rapidement sur un diagnostic unique. De manière générale, la plupart des systèmes ont sous‑estimé la gravité des patients lors de l’attribution des niveaux de triage, un biais conservateur qui pourrait retarder les soins urgents s’il n’est pas corrigé. Les résultats soulignent un point clé : connaître des faits médicaux n’est pas équivalent à les intégrer de façon fiable dans des décisions sûres et séquentielles quand l’information est incomplète, désordonnée et variable.

Ce que cela pourrait signifier pour les futures visites aux urgences
Les auteurs concluent que si plusieurs IA modernes se valent désormais en connaissances médicales, GPT‑5 affiche en particulier un nouveau niveau de capacité de raisonnement qui pourrait le rendre utile comme outil d’aide à la décision dans les services d’urgence. Ils insistent sur le fait que ces systèmes ne sont pas prêts à remplacer les cliniciens ni à agir de manière autonome. Le rôle le plus prometteur à court terme est plutôt celui d’un assistant supervisé : aider les infirmiers de triage à estimer l’urgence, rédiger des résumés de patients, suggérer des questions ou des examens, et vérifier que des diagnostics graves ont été envisagés. L’étude souligne aussi que davantage de recherches sont nécessaires en milieu clinique réel, avec des mesures de sécurité strictes et des règles d’utilisation claires. Pour les patients, le message est d’un optimisme prudent : l’IA progresse dans le raisonnement sur des problèmes médicaux, mais son usage sûr aux urgences dépendra d’une conception et d’une supervision rigoureuses, et d’un maintien de l’objectif d’épauler — et non de substituer — le jugement humain des médecins et infirmiers.
Citation: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Mots-clés: médecine d’urgence, grands modèles de langage, assistance à la décision clinique, triage, évaluation comparative de l’IA médicale