Clear Sky Science · fr
Améliorer la reconnaissance d'entités nommées en few-shot pour les grands modèles de langue en utilisant un prompting dynamique structuré avec génération augmentée par récupération
Pourquoi une lecture plus intelligente des textes médicaux est importante
La médecine moderne génère des océans de texte — des notes en soins intensifs aux conversations en ligne sur l'usage de médicaments. Cachées dans ces mots se trouvent des informations cruciales sur les maladies, les traitements et les effets secondaires. Repérer et étiqueter automatiquement ces extraits, une tâche appelée « reconnaissance d'entités nommées », peut aider les chercheurs à suivre les épidémies, détecter plus tôt les problèmes liés aux médicaments et assister les médecins en temps réel. Mais les systèmes traditionnels nécessitent de vastes jeux de données annotés manuellement, coûteux à constituer et souvent inexistants pour les problèmes de santé rares ou émergents. Cette étude examine comment les grands modèles de langue, comme ceux derrière les chatbots actuels, peuvent être guidés par des prompts soigneusement conçus et par une récupération intelligente d'exemples afin d'effectuer correctement cette tâche d'étiquetage même lorsque seuls quelques échantillons annotés sont disponibles.
Apprendre aux machines à repérer les mots importants
Les auteurs se concentrent sur la reconnaissance d'entités nommées biomédicales — trouver les mentions de maladies, de médicaments, de symptômes et d'impacts sociaux dans le texte. C'est difficile parce que le langage médical est très spécialisé, varie selon l'hôpital ou le sous-domaine, et implique souvent des affections rares qui apparaissent seulement quelques fois dans un jeu de données. Les modèles d'apprentissage automatique existants peuvent atteindre des performances proches de celles des humains mais exigent généralement de grands corpus bien annotés, coûteux à créer et à partager, surtout sous des règles strictes de confidentialité. L'apprentissage few-shot, où les modèles apprennent à partir d'une poignée d'exemples étiquetés, offre une alternative à ce goulot d'étranglement. Les grands modèles de langue sont particulièrement prometteurs car ils peuvent apprendre des motifs directement à partir d'instructions et d'exemples fournis dans le prompt, sans réentraîner leurs poids internes.
Construire de meilleures instructions pour les modèles de langue
La première partie du travail conçoit un prompt « statique » fortement structuré — un bloc réutilisable d'instructions et d'exemples présenté au modèle pour chaque phrase qu'il doit annoter. Plutôt que de simplement demander au modèle d'étiqueter des entités, le prompt est découpé en six éléments : une description claire de la tâche et des définitions des types d'entités ; une brève description de la source et du thème du jeu de données ; des mots d'exemple fréquents typiques de chaque entité ; des connaissances médicales contextuelles optionnelles ; un résumé des retours d'erreurs antérieures du modèle ; et quelques phrases entièrement annotées en exemple. L'équipe a testé ce cadre avec trois grands modèles de langue — GPT-3.5, GPT-4 et LLaMA 3-70B — sur cinq jeux de données biomédicaux couvrant dossiers cliniques, résumés scientifiques et publications Reddit sur l'usage d'opioïdes. L'ajout soigneux de ces composants a augmenté les scores F1 (équilibre entre précision et rappel) d'environ 11–12 points de pourcentage par rapport à un prompt basique, GPT-4 obtenant la meilleure performance globale.
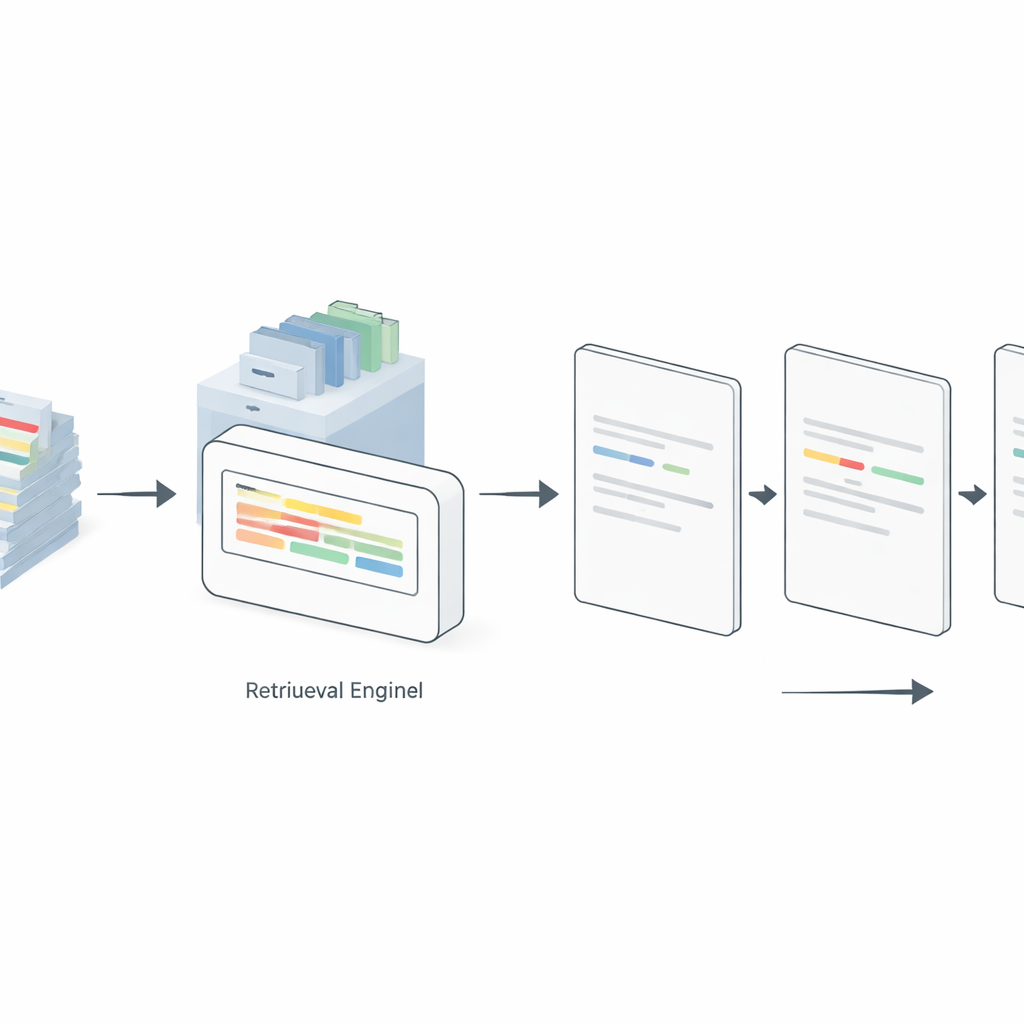
Laisser le modèle rechercher de meilleurs exemples à la volée
Les prompts statiques montrent cependant toujours les mêmes exemples, même lorsqu'ils sont mal assortis à la nouvelle phrase à annoter. Pour y remédier, les auteurs introduisent une stratégie de prompting « dynamique » alimentée par la génération augmentée par récupération. Ici, un moteur de recherche distinct indexe tous les exemples annotés disponibles. Pour chaque nouvelle phrase d'entrée, le système recherche dans cette banque les phrases étiquetées les plus similaires et n'insère dans le prompt que celles-ci. L'étude compare plusieurs méthodes de récupération, d'un schéma simple de fréquence de termes (TF–IDF) à des modèles d'embeddings neuronaux tels que Sentence-BERT (SBERT), ColBERT et Dense Passage Retrieval. Sur GPT-4, LLaMA 3 et un modèle à poids ouvert appelé GPT-OSS-120B, la sélection dynamique d'exemples pertinents a systématiquement surpassé le prompting statique en configurations 5-, 10- et 20-shot. Fait surprenant, la méthode simple TF–IDF a souvent égalé ou dépassé des approches plus complexes, spécialement sur des jeux de données plus propres et standardisés, tandis que SBERT s'est démarqué sur des textes de médias sociaux plus bruyants.
Tirer davantage de moins d'exemples annotés
Étant donné que l'annotation de textes médicaux est coûteuse, les auteurs ont aussi étudié combien d'exemples annotés le moteur de récupération devait indexer pour être utile. Avec LLaMA 3-70B, ils ont fait varier la banque de récupération de 50 exemples jusqu'à l'entièreté du jeu d'entraînement. Les performances s'amélioraient généralement à mesure que la banque grandissait, mais les gains se sont rapidement aplanis : des banques d'environ 100–200 exemples atteignaient presque la même précision que l'indexation de toutes les données disponibles, souvent dans la marge d'erreur statistique. Dans certains cas, des banques extrêmement larges nuisaient légèrement aux performances, probablement parce qu'elles introduisaient davantage d'exemples non pertinents ou confus et rallongeaient le prompt. Ces résultats suggèrent que, associés à un modèle de langue performant et à des prompts bien conçus, des efforts d'annotation modestes peuvent suffire à obtenir une reconnaissance d'entités biomédicales robuste, rendant l'approche faisable pour les maladies rares, les nouveaux concepts cliniques ou les institutions aux ressources limitées.
Ce que cela implique pour la médecine réelle
Dans l'ensemble, l'étude montre que les grands modèles de langue peuvent identifier de façon fiable des concepts médicaux importants dans le texte en n'utilisant qu'une poignée d'exemples annotés, à condition d'être guidés par des prompts structurés et un système de récupération qui remonte les cas antérieurs les plus pertinents. GPT-4 offre la meilleure performance générale, tandis que les modèles ouverts et plus petits tirent encore un bénéfice substantiel de la même recette de prompting et de récupération. Pour les praticiens, cela signifie qu'il n'est pas nécessaire de construire des jeux de données massifs chaque fois qu'un nouveau type d'entité ou une nouvelle préoccupation sanitaire apparaît ; un ensemble compact et soigneusement sélectionné d'exemples, associé à un prompting intelligent, peut suffire. À mesure que les systèmes de santé numérisent davantage de notes et que les patients évoquent leurs expériences en ligne, de tels outils efficaces et adaptables pourraient faciliter considérablement l'extraction de connaissances cliniquement utiles du vaste et désordonné univers du texte médical.
Citation: Ge, Y., Guo, Y., Das, S. et al. Improving few-shot named entity recognition for large language models using structured dynamic prompting with retrieval augmented generation. npj Artif. Intell. 2, 39 (2026). https://doi.org/10.1038/s44387-025-00062-2
Mots-clés: reconnaissance d'entités nommées biomédicales, apprentissage few-shot, grands modèles de langue, génération augmentée par récupération, extraction de texte clinique