Clear Sky Science · fr
Correction des erreurs d'addition-accumulation en traitement en mémoire avec des LDPC
Pourquoi corriger les erreurs mathématiques en mémoire est essentiel
Les puces d'intelligence artificielle modernes gagnent en vitesse et en efficacité en effectuant les calculs directement dans la mémoire, au lieu de transférer sans cesse les données vers des processeurs séparés. Cette approche de « traitement en mémoire » économise de l'énergie mais introduit un problème sérieux : de petites imperfections électriques peuvent inverser des bits stockés ou déformer des signaux analogiques, dégradant silencieusement la précision de tâches comme la reconnaissance d'images. L'article décrit une nouvelle méthode pour détecter et corriger automatiquement ces erreurs à la volée, aidant le matériel IA futur à rester à la fois rapide et digne de confiance.
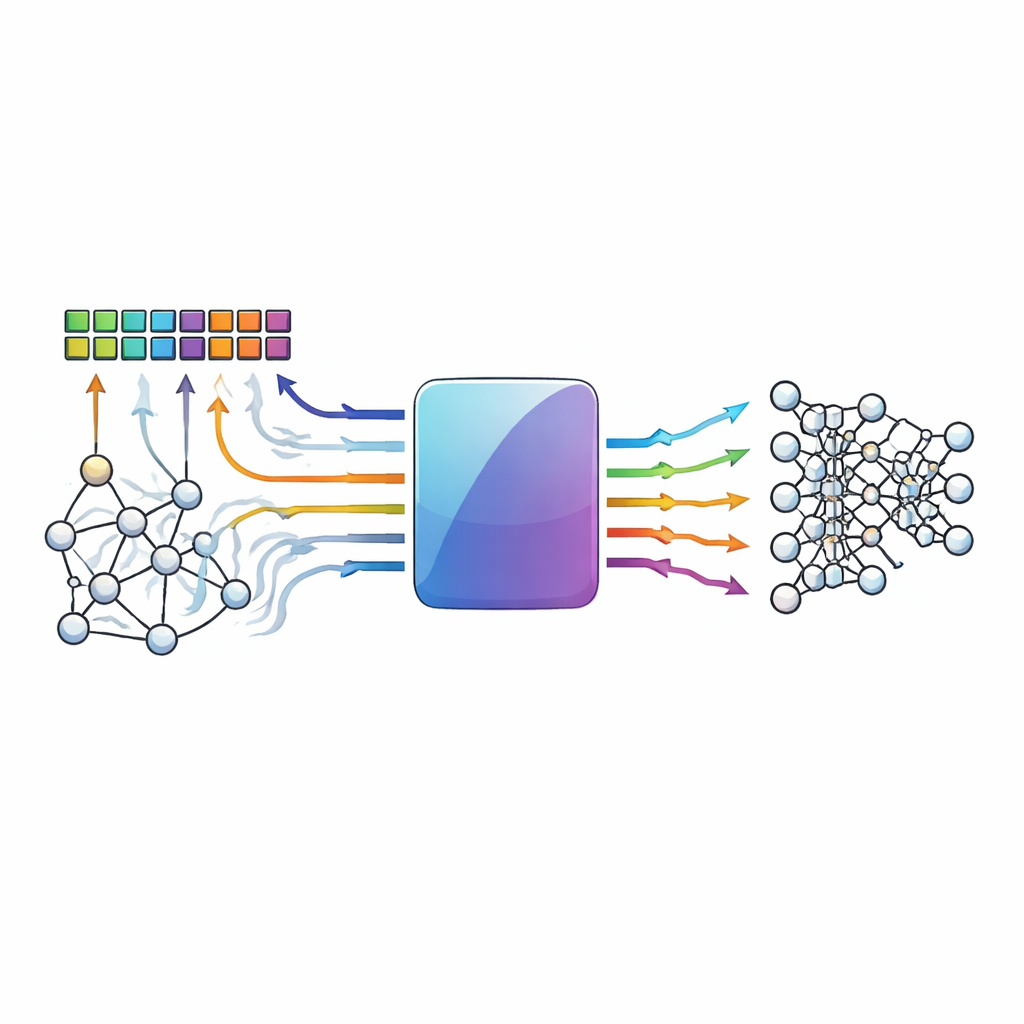
Calculer là où vivent les données
Les ordinateurs conventionnels sont ralentis par la nécessité de déplacer les données entre la mémoire et le processeur. Les architectures de traitement en mémoire évitent ce goulot d'étranglement en réalisant des opérations de multiplication-accumulation — l'épine dorsale des réseaux neuronaux — à l'intérieur d'ensembles denses de cellules mémoire. Des dispositifs émergents tels que la mémoire résistive et d'autres éléments mémristifs sont particulièrement attractifs car ils peuvent stocker de nombreuses valeurs et effectuer des calculs analogiques avec grande efficacité. Cependant, la même nature analogique et la variabilité des dispositifs qui les rendent puissants les rendent aussi bruyants : les fluctuations thermiques, les discordances entre dispositifs et les chutes de tension peuvent tous déplacer les valeurs stockées ou les résultats calculés hors de leur place prévue.
Quand de petites perturbations s'accumulent
Dans ces matrices en mémoire, de nombreuses lignes de cellules sont activées simultanément et leurs contributions sont sommées le long de fils partagés. À mesure que davantage de lignes participent, leurs imperfections individuelles s'additionnent, créant des schémas d'erreurs à la fois fréquents et complexes. Plutôt qu'un unique bit erroné, les concepteurs observent souvent plusieurs erreurs regroupées dans la même colonne d'une matrice ou réparties sur plusieurs colonnes d'une façon qui rend inefficaces les méthodes classiques de correction d'erreurs. Les codes standards supposent généralement des schémas d'erreurs simples et des longueurs de mot courtes ; ils peuvent manquer des défaillances multi-bits ou ne pas contenir dans leurs tables de consultation des combinaisons rares mais dommageables. En conséquence, la précision des modèles de réseaux profonds peut chuter fortement dès que le matériel sous-jacent devient même modestement peu fiable.
Un nouveau filet de sécurité numérique
Les auteurs introduisent un code LDPC à faible densité non binaire (NB-LDPC) spécifiquement adapté au matériel de traitement en mémoire. Plutôt que de travailler uniquement avec des zéros et des uns, leur schéma opère sur de petits groupes de bits traités comme des symboles dans une structure mathématique appelée corps fini construit à partir d'un nombre premier (ici, trois). Cela permet au même code de protéger à la fois le stockage binaire ordinaire et les codages multi-niveaux ou différentiels couramment utilisés dans les accélérateurs analogiques. Le système ajoute un nombre modeste de symboles supplémentaires — des symboles de contrôle — à chaque bloc de données. Lors des lectures mémoire normales et des opérations de multiplication-accumulation en mémoire, le matériel calcule les résultats pour les données et les symboles de contrôle ensemble, de sorte que la détection d'erreurs est naturellement intégrée au calcul.
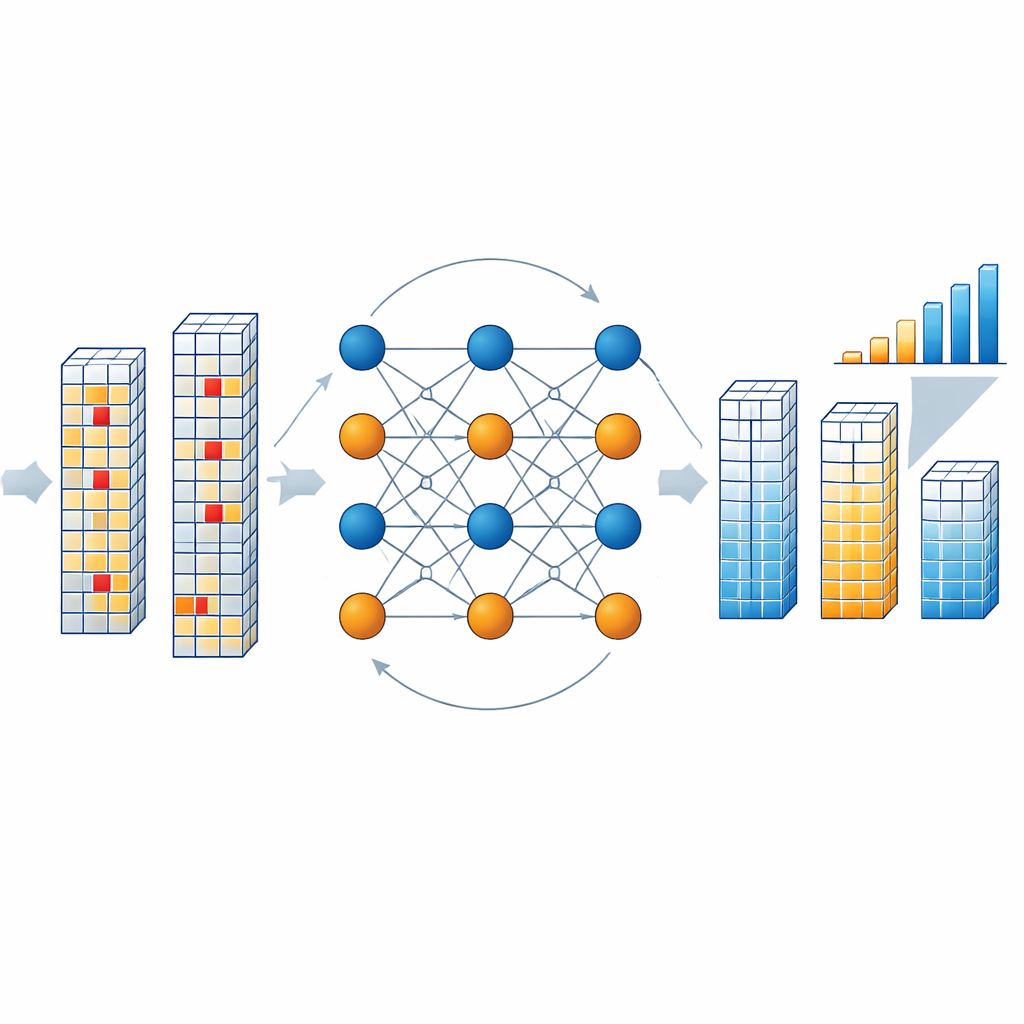
Comment le moteur de correction fonctionne à l'intérieur de la puce
Lorsque la puce lit un bloc de résultats, un décodeur dédié vérifie si les symboles de données combinés et de contrôle respectent les relations de parité définies par le code. S'ils le font, le bloc est considéré propre. Sinon, le décodeur lance un processus itératif dans lequel des « nœuds variables » abstraits représentant chaque symbole et des « nœuds de contrôle » représentant les conditions de parité échangent des messages de probabilité. Ces messages estiment la probabilité pour chaque symbole de prendre chacune des valeurs autorisées, sur la base des sorties observées et du taux d'inversion de bits attendu de la mémoire. Les auteurs simplifient ce raisonnement mathématique à l'aide d'approximations par distance de Manhattan, ce qui réduit fortement le coût matériel tout en maintenant de bonnes performances. Après quelques tours — typiquement trois — le décodeur converge vers la version corrigée la plus plausible du vecteur de résultats, sans jamais avoir besoin de relire la mémoire ou d'interrompre le flux de calcul.
Preuve en silicium et impact sur la précision IA
Pour tester l'idée en pratique, l'équipe a conçu une puce prototype en technologie 40 nanomètres qui combine une matrice de mémoire résistive, des convertisseurs analogique-numérique légers et le nouveau décodeur NB-LDPC. Avec une configuration protégeant 256 symboles d'information à l'aide de 32 symboles de contrôle, le décodeur atteint un taux de code élevé (environ 0,8), une efficacité énergétique mesurée maximale d'environ 88 térabits de données corrigées par seconde et par watt, et un surcoût en surface modeste qui peut être réduit en partageant un décodeur entre plusieurs macros mémoire. Des simulations sur de nombreuses tailles de code montrent que, en protégeant 1024 symboles de données avec 128 symboles de contrôle, le schéma peut améliorer le taux d'erreur binaire d'un facteur proche de 60. Appliqué à un modèle de classification d'images ResNet-34 exécuté sur du matériel de traitement en mémoire, la correction restaure plus de 20 points de pourcentage de précision perdus dans des conditions d'erreur difficiles.
Ce que cela signifie pour les puces IA de demain
En termes simples, ce travail fournit au matériel de traitement en mémoire un « correcteur orthographique » robuste pour ses calculs, capable de comprendre des ensembles de symboles plus riches et des schémas d'erreurs complexes sans ralentir le flux de données. En unifiant la protection du stockage et des calculs à la volée, et en démontrant une implémentation silicium efficace, l'étude montre que les accélérateurs en mémoire haute densité et basse consommation n'ont pas à sacrifier la fiabilité. Ce type de correction d'erreurs sur mesure pourrait devenir un ingrédient clé pour rendre les accélérateurs neuromorphiques et IA futurs à la fois économes en énergie et suffisamment fiables pour des applications réelles, des appareils mobiles aux centres de données à grande échelle.
Citation: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
Mots-clés: processing-in-memory, correction d'erreurs, codes LDPC, mémoire résistive, matériel pour réseaux neuronaux