Clear Sky Science · fr
Une évaluation de l’incertitude estimative dans les grands modèles de langage
Pourquoi les termes flous sur le risque comptent vraiment
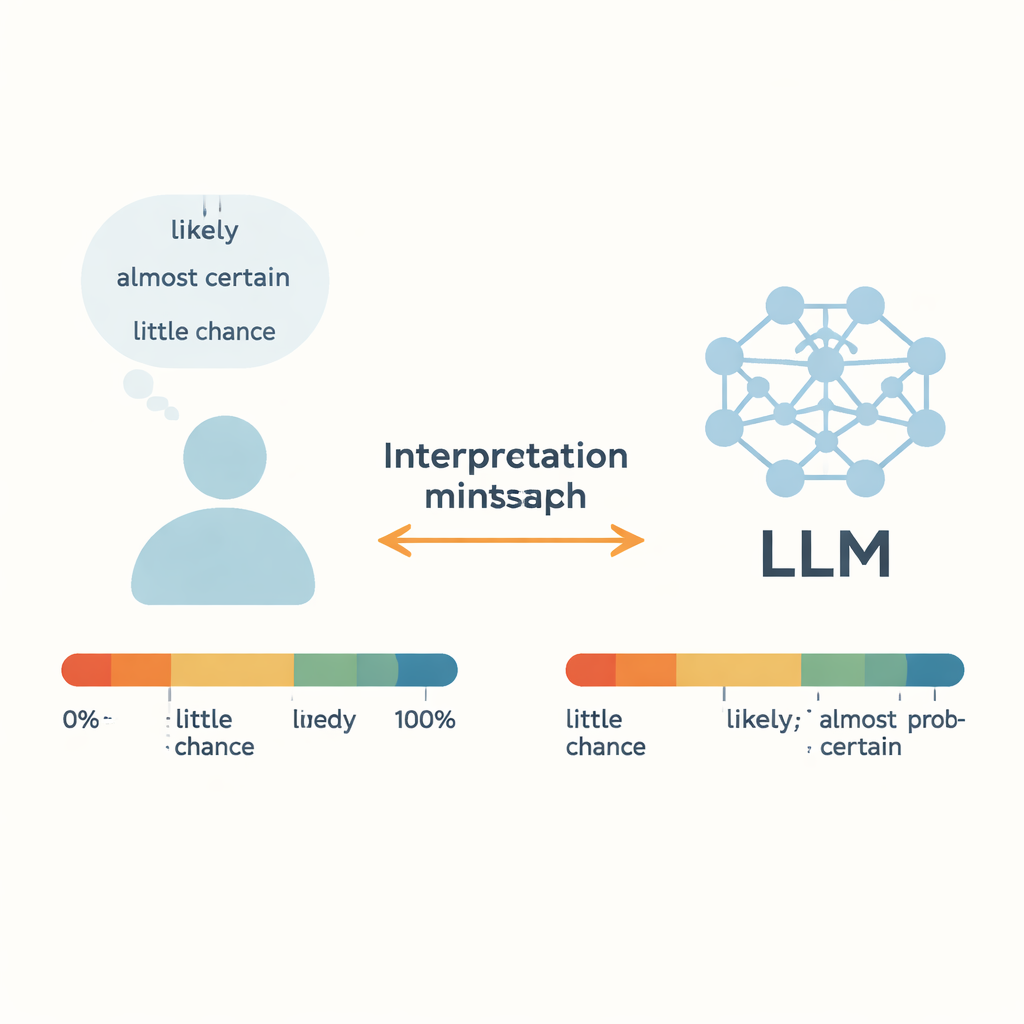
Quand un médecin dit qu’un traitement est « probablement » efficace, ou qu’un météorologue avertit qu’il y a « peu de chances » qu’un ouragan se produise, nous nous fions à ces mots imprécis pour prendre de véritables décisions. Aujourd’hui, les grands modèles de langage (LLM) — comme les chatbots en ligne — commencent à employer le même vocabulaire. Cette étude pose une question simple mais cruciale : quand une IA dit « probablement », entend‑elle la même chose que nous — et peut‑elle de manière fiable transformer des nombres bruts en mots d’incertitude du quotidien ?
Mettre l’incertitude quotidienne sous la loupe
Les auteurs se concentrent sur les « mots de probabilité estimative » (WEP) — des termes comme « presque certain », « probable » ou « peu de chances » que les gens utilisent à la place de pourcentages précis. Des travaux antérieurs, remontant aux analystes du renseignement des années 1960, ont tenté de relier ces mots à des probabilités numériques en interrogeant des personnes. Cette étude compare ces jugements humains aux sorties de cinq LLM modernes, dont GPT‑3.5, GPT‑4, les modèles Llama de Meta et un système chinois appelé ERNIE‑4.0. Pour 17 mots d’incertitude courants, chaque modèle a reçu des amorces de type récit en anglais ou en chinois et a été invité à répondre par une probabilité numérique entre 0 et 100 pourcent. En répétant cela dans de nombreux contextes, les auteurs ont construit des distributions de probabilité complètes pour chaque mot et chaque modèle, puis les ont comparées aux données d’enquête humaines.
Où humains et IA parlent la même langue
Pour les expressions les plus extrêmes — telles que « presque certain » à l’extrémité haute et « presque aucune chance » à l’extrémité basse — les LLM et les humains s’alignent étonnamment bien. Tant les personnes que les modèles ont tendance à regrouper ces expressions dans des plages de probabilité étroites, très élevées ou très faibles, ce qui suggère que ces termes forts ont des significations relativement stables selon les contextes. Il en va de même pour « à peu près égal », que la plupart des humains et des modèles traitent comme une chance d’environ 50–50. Les tests statistiques révèlent peu de différences significatives entre les distributions humaines et celles des modèles pour ces mots particuliers, ce qui implique que les LLM peuvent saisir des cas clairs de quasi‑certitude ou de quasi‑impossibilité avec une précision comparable à celle des humains.
Où les significations divergent doucement
Les mots ambigus, situés au milieu de l’échelle, racontent une histoire différente. Pour des expressions telles que « probable », « vraisemblable », « nous doutons » et « peu de chances », les interprétations numériques des modèles diffèrent sensiblement des jugements humains. GPT‑4, malgré des capacités globales supérieures à GPT‑3.5, montre souvent des écarts plus importants. Les auteurs suggèrent que cela tient peut‑être au fait que ces mots mêlent deux dimensions : un sens de probabilité et une attitude ou une position du locuteur. Dans la conversation réelle, « probable » peut sonner prudent ou assuré selon le ton et le contexte, et « nous doutons » peut exprimer du scepticisme plutôt qu’une probabilité précise. Formés sur d’énormes corpus hétérogènes issus d’internet, les LLM peuvent faire la moyenne de nombreuses utilisations contradictoires, estompant ces subtilités. Le résultat est un décalage caché : humains et IA peuvent voir la même phrase mais attacher discrètement des nombres différents au même mot.
Genre, langue et résonances culturelles
Les chercheurs ont également testé comment la formulation genrée et les langues différentes influencent ces mots de probabilité. Lorsque les amorces faisaient référence à « il » ou « elle » au lieu de sujets neutres, GPT‑3.5 et GPT‑4 produisaient souvent des estimations de probabilité moins variables, plus « figées », parfois ramenées à un point unique. Cela suggère que les modèles ont pu absorber des schémas rigides issus de stéréotypes présents dans leurs données d’entraînement, même si les moyennes générales pour les amorces masculines et féminines restaient similaires. En comparant les amorces en anglais et en chinois, les modèles GPT montraient des décalages notables dans l’interprétation des mêmes mots d’incertitude. ERNIE‑4.0, principalement entraîné sur des textes chinois, se rapprochait davantage des locuteurs chinois sur de nombreux termes mais surestimait ou sous‑estimait encore certaines expressions. Ces résultats soulignent que la façon dont une IA parle de l’incertitude dépend non seulement du mot choisi, mais aussi des patterns linguistiques et culturels inscrits dans son entraînement.
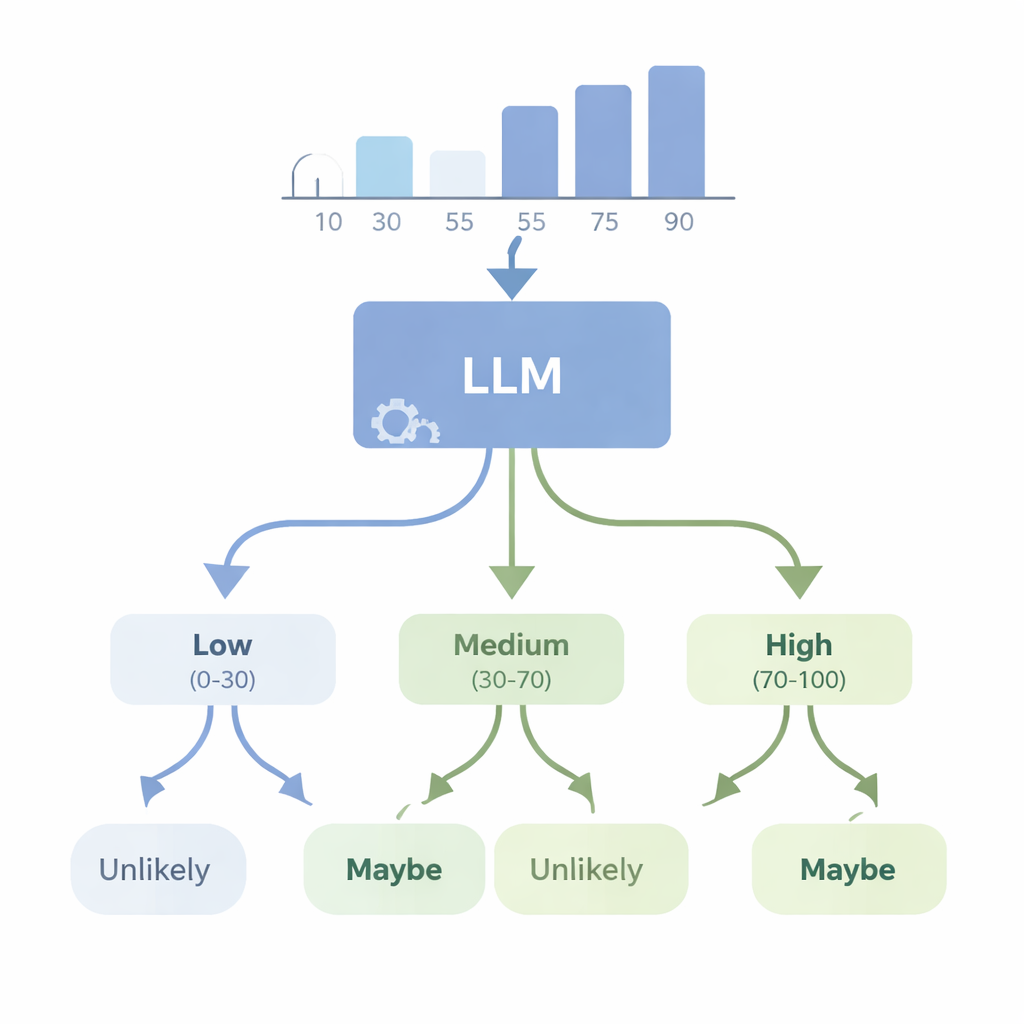
Les IA peuvent‑elles transformer des nombres en doutes formulés clairement ?
Dans une seconde série d’expériences, les auteurs ont étudié le problème inverse : un modèle avancé comme GPT‑4 peut‑il partir de données numériques et choisir le mot d’incertitude approprié ? Ils ont fourni au modèle des jeux de données simples — listes de tailles ou de notes — et lui ont demandé de choisir le WEP le mieux adapté (par exemple « presque certainement », « probable », « peut‑être », « improbable », ou « presque certainement pas ») pour des énoncés sur des résultats futurs. Ils ont ensuite évalué GPT‑4 avec quatre nouveaux scores de « cohérence » vérifiant si ses choix de mots ont du sens logique lorsque les probabilités augmentent ou diminuent, quand des événements complémentaires sont décrits, et lorsque les nombres sous‑jacents changent de manière contrôlée. GPT‑4 a fait bien mieux qu’un choix aléatoire et a souvent suivi les variations grossières de probabilité, mais il est resté loin d’une cohérence parfaite. Dans certains tests, il a répondu presque de la même manière pour différents niveaux de confiance, ce qui suggère qu’il traite parfois ces mots comme des étiquettes larges plutôt que comme une échelle finement accordée aux données réelles.
Ce que cela signifie pour les décisions dans le monde réel
Pour le lecteur, le message est prudent mais non alarmiste. Les LLM peuvent déjà imiter nos expressions les plus fortes de certitude et d’impossibilité, et ils peuvent souvent résumer des données en affirmations « probable » ou « improbable » raisonnables. Mais cette étude montre que, pour de nombreux mots d’incertitude du quotidien, leur calibration interne ne correspond pas entièrement à l’intuition humaine, et leur conversion des nombres en langage peut être incohérente. Dans des domaines comme la médecine, les politiques publiques ou la communication scientifique — où de petits changements dans la formulation du risque ou de la confiance peuvent avoir des conséquences — le « probablement » d’un modèle peut ne pas être le vôtre. Les auteurs soutiennent que pour utiliser ces systèmes en toute sécurité, il faut considérer les mots d’incertitude comme un code partagé qui nécessite encore un alignement, des tests et peut‑être un soutien numérique explicite, plutôt que de supposer automatiquement que l’humain et la machine ont la même intention.»
Citation: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Mots-clés: incertitude langage, grands modèles de langage, mots de probabilité, communication humain-IA, interprétation du risque