Clear Sky Science · fr
ADMM stochastique inexact préconditionné pour modèles profonds
Un entraînement plus intelligent pour une IA plus intelligente
Les systèmes d’intelligence artificielle modernes, des chatbots aux générateurs d’images, reposent sur d’immenses réseaux de neurones qui sont notoirement difficiles et coûteux à entraîner. À mesure que entreprises et chercheurs répartissent les données sur de nombreux appareils et serveurs, les méthodes d’entraînement courantes ralentissent souvent, deviennent instables ou ne parviennent tout simplement pas à gérer la désordre du monde réel. Cet article présente une nouvelle famille d’algorithmes d’entraînement, centrée sur une méthode appelée PISA, qui promet un apprentissage plus rapide et plus fiable pour un large éventail de modèles profonds tout en faisant moins d’hypothèses mathématiques sur les données.
Pourquoi les méthodes d’entraînement actuelles peinent
La plupart des modèles d’apprentissage profond sont entraînés avec des variantes de la descente de gradient stochastique, une approche qui ajuste à plusieurs reprises les paramètres du modèle dans la direction qui réduit l’erreur. Au fil des années, de nombreux raffinements — tels qu’Adam, RMSProp et d’autres — ont tenté de rendre ces ajustements plus « intelligents » en adaptant les pas ou en ajoutant de la momentum. Cependant, ces méthodes supposent généralement que les données d’entraînement sont bien mélangées et statistiquement similaires entre les machines, et que certaines quantités mathématiques restent bornées. En pratique, notamment dans des contextes comme l’apprentissage fédéré où des téléphones ou des appareils en périphérie contiennent des données très différentes, ces hypothèses sont souvent violées, ce qui entraîne une convergence lente ou des performances médiocres.
Une nouvelle façon de coordonner de nombreux apprenants
Les auteurs s’appuient sur un cadre d’optimisation différent connu sous le nom de méthode des directions alternées des multiplicateurs (ADMM), qui est efficace pour découper un grand problème en plusieurs sous-problèmes plus petits pouvant être résolus en parallèle. Leur contribution principale, PISA (ADMM stochastique inexact préconditionné), conserve les points forts d’ADMM tout en évitant ses inconvénients habituels — comme la nécessité de calculer des gradients complets sur l’ensemble des données ou d’effectuer des inversions matricielles coûteuses. À la place, PISA permet à chaque client ou nœud de travail de mettre à jour sa propre copie du modèle en n’utilisant qu’un mini‑lot de données, puis de coordonner ces mises à jour via une variable centrale. Des matrices de « préconditionnement » soigneusement conçues réorientent les directions de mise à jour pour que l’apprentissage progresse de manière plus fluide et efficace. 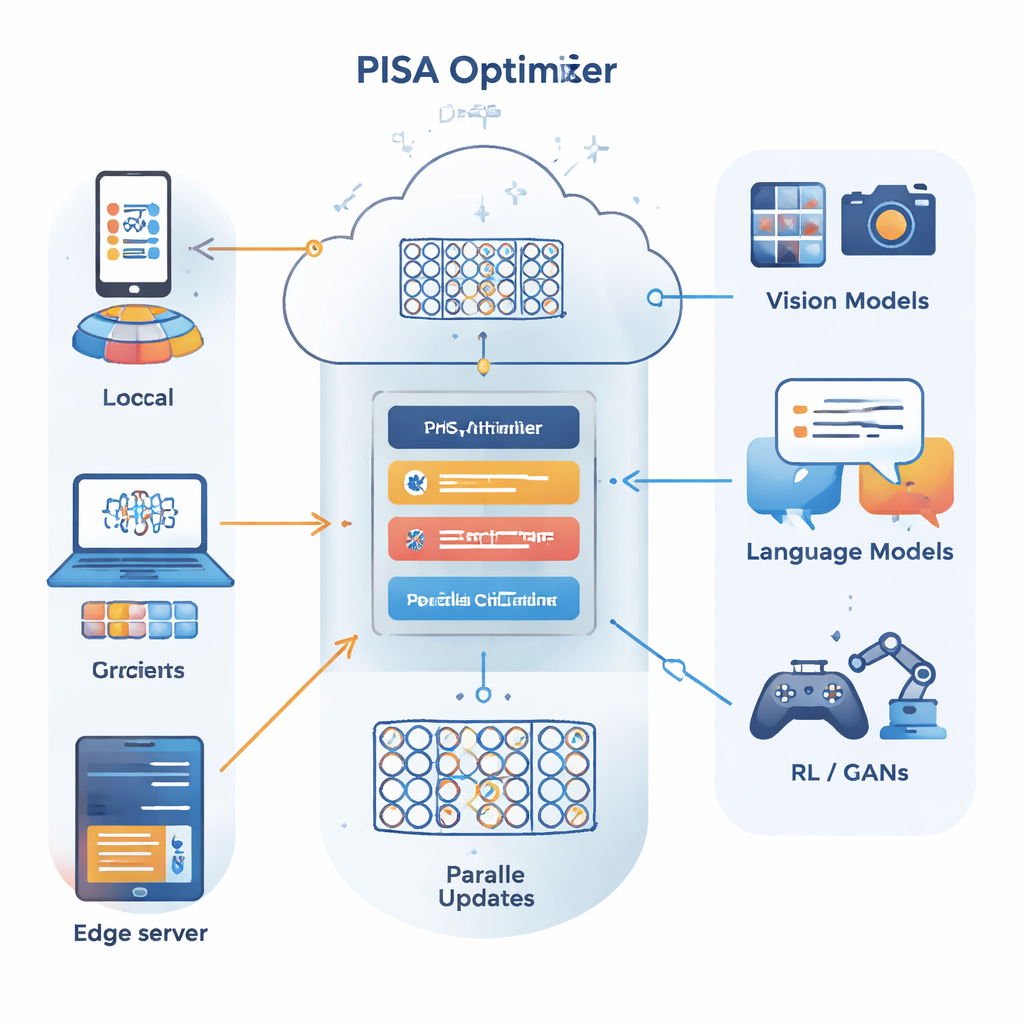
Des garanties plus solides avec des hypothèses plus faibles
Une caractéristique distincte de PISA est sa fondation théorique. Les auteurs démontrent que leur algorithme converge sous une unique hypothèse relativement faible : que le gradient de la fonction de perte est Lipschitzien dans une région bornée, condition satisfaite par de nombreuses pertes standard en réseaux de neurones. Contrairement à la plupart des méthodes stochastiques, PISA n’exige pas que les gradients soient non biaisés, qu’ils aient une variance bornée, ni qu’ils proviennent de données parfaitement mélangées. Malgré ce cadre assoupli, la méthode atteint un taux de convergence linéaire en termes de stabilisation des valeurs de la fonction et des mises à jour des paramètres, la plaçant parmi les algorithmes les plus performants du tableau comparatif fourni. Cela rend PISA particulièrement attrayante pour des distributions de données hétérogènes et non uniformes, courantes en déploiement réel.
Variantes pratiques pour de vrais réseaux profonds
Pour rendre le cadre praticable sur de grands réseaux de neurones, les auteurs introduisent deux variantes efficaces, SISA et NSISA. SISA utilise l’information du second moment — essentiellement en suivant l’amplitude des mises à jour passées dans chaque direction de paramètre — pour former des préconditionneurs diagonaux simples, similaires aux idées derrière Adam et RMSProp mais intégrés dans la structure ADMM. NSISA va plus loin en incorporant une technique connue sous le nom d’orthogonalisation de Newton–Schulz, inspirée de l’optimiseur Muon, afin d’aligner mieux la momentum avec les directions utiles dans l’espace des paramètres. Les deux variantes conservent les garanties de convergence de PISA tout en gardant la charge de calcul suffisamment légère pour les GPU modernes et les grands modèles.
Performances en vision, langage et modèles génératifs
Les auteurs testent SISA et NSISA sur un large éventail de tâches d’apprentissage profond. Dans des expériences d’apprentissage fédéré avec des distributions d’étiquettes volontairement biaisées — un contexte difficile où chaque client ne voit qu’un sous‑ensemble de classes — SISA surpasse de manière spectaculaire des méthodes populaires comme FedAvg, FedProx, FedNova et Scaffold, atteignant une bien meilleure précision de test sur des bancs d’essai tels que MNIST et CIFAR-10. Pour la classification d’images standard avec des modèles comme ResNet et DenseNet sur CIFAR-10 et ImageNet, SISA égalise ou dépasse de solides optimiseurs incluant SGD avec momentum, AdaBelief et AdamW. Lors du fine-tuning de modèles de langage GPT2 de tailles croissantes, NSISA obtient une perte de validation plus faible en moins de temps que des optimiseurs spécialisés tels que Shampoo, SOAP, Adam-mini et Muon, l’avantage se renforçant pour le modèle le plus grand. Il stabilise également l’entraînement des réseaux antagonistes génératifs, obtenant des scores Fréchet Inception Distance plus bas, qui mesurent la qualité visuelle et la diversité des images générées. 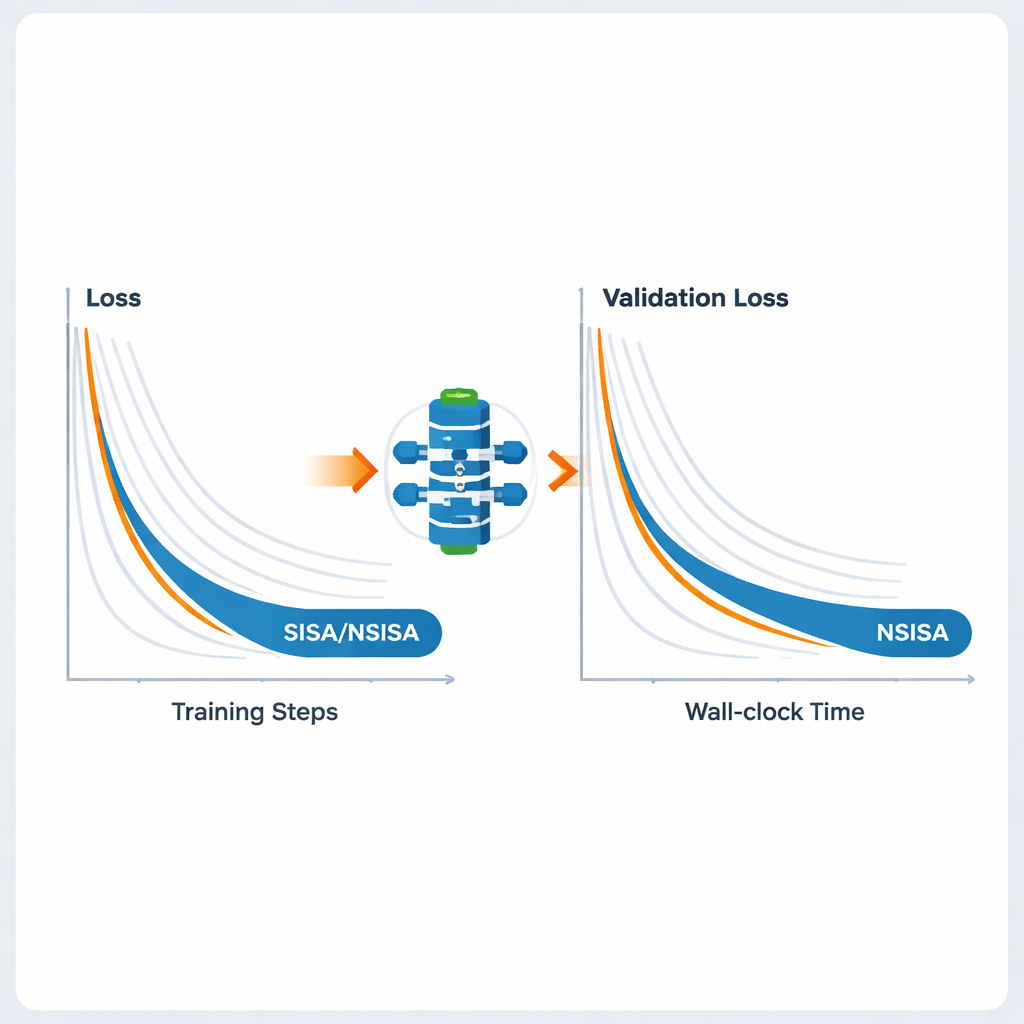
Ce que cela signifie pour l’IA du quotidien
En termes simples, ce travail montre qu’il est possible d’entraîner des modèles d’IA puissants plus rapidement et de manière plus fiable, même lorsque les données sont désordonnées, déséquilibrées ou réparties sur de nombreux appareils. En repensant le processus d’optimisation sous-jacent plutôt qu’en se contentant d’ajuster les taux d’apprentissage, PISA et ses variantes offrent un outil unifié qui fonctionne bien pour la vision, le langage, l’apprentissage par renforcement et les tâches génératives. Pour les utilisateurs finaux, cela pourrait se traduire par une personnalisation plus intelligente sur les téléphones, des modèles de langage et d’image plus performants et une utilisation plus efficace des ressources informatiques dans les grands centres de données — le tout rendu possible par un algorithme d’entraînement mieux adapté aux réalités des systèmes d’IA modernes.
Citation: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Mots-clés: optimisation en apprentissage profond, apprentissage fédéré, ADMM stochastique, grands modèles de langage, données hétérogènes