Clear Sky Science · fr
Quand les grands modèles de langage sont fiables pour juger la communication empathique
Pourquoi l’empathie des machines vous concerne
De plus en plus, les gens se tournent vers des chatbots et des assistants numériques lorsqu’ils sont stressés, seuls ou confrontés à des décisions difficiles. Ces systèmes peuvent sembler attentionnés et compréhensifs — mais peuvent-ils aussi juger si un message est vraiment bienveillant et soutenant ? Cet article examine quand les grands modèles de langage (GML), la technologie qui alimente de nombreux chatbots, peuvent évaluer de manière fiable à quel point une réponse écrite paraît empathique, et ce que cela implique pour des outils du quotidien comme les applications de bien‑être, les thérapeutes virtuels et les bots de service client. 
Étudier des conversations de soutien
Les chercheurs ont analysé 200 conversations textuelles réelles dans lesquelles une personne décrivait un problème personnel — par exemple le stress au travail, des conflits familiaux, des soucis d’argent ou des difficultés de santé mentale — et une autre personne cherchait à répondre de façon bienveillante. Ces conversations proviennent de quatre jeux de données existants, chacun associé à un ensemble différent de questions pour évaluer l’empathie. Certaines se concentraient sur le fait que le répondant montre de la compréhension ou offre un réconfort émotionnel ; d’autres demandaient s’il donnait des conseils pratiques, encourageait l’interlocuteur à s’exprimer davantage, ou, au contraire, recentrait la conversation sur lui‑même. Ensemble, ces cadres décomposent « être empathique » en 21 comportements spécifiques pouvant être évalués sur des échelles, un peu comme une enquête de satisfaction client.
Experts, foule et machines
Pour évaluer la capacité des GML à noter l’empathie, l’équipe a comparé trois types d’évaluateurs : des experts en communication, des travailleurs en ligne recrutés en foule et des modèles de langage modernes. Trois chercheurs chevronnés en communication empathique ont évalué indépendamment chaque conversation sur les 21 comportements. Les membres de la foule — des utilisateurs ordinaires d’internet — avaient déjà fourni des notes pour les mêmes messages dans des études antérieures. Enfin, trois modèles de langage de pointe ont été soigneusement invités à suivre des consignes en langage clair et des exemples de notes fournis par les experts, puis on leur a demandé de noter chaque conversation sur les mêmes échelles. Cette configuration a permis aux auteurs de mesurer à quel point chaque groupe s’accordait, non seulement par rapport à une « réponse correcte », mais entre eux. 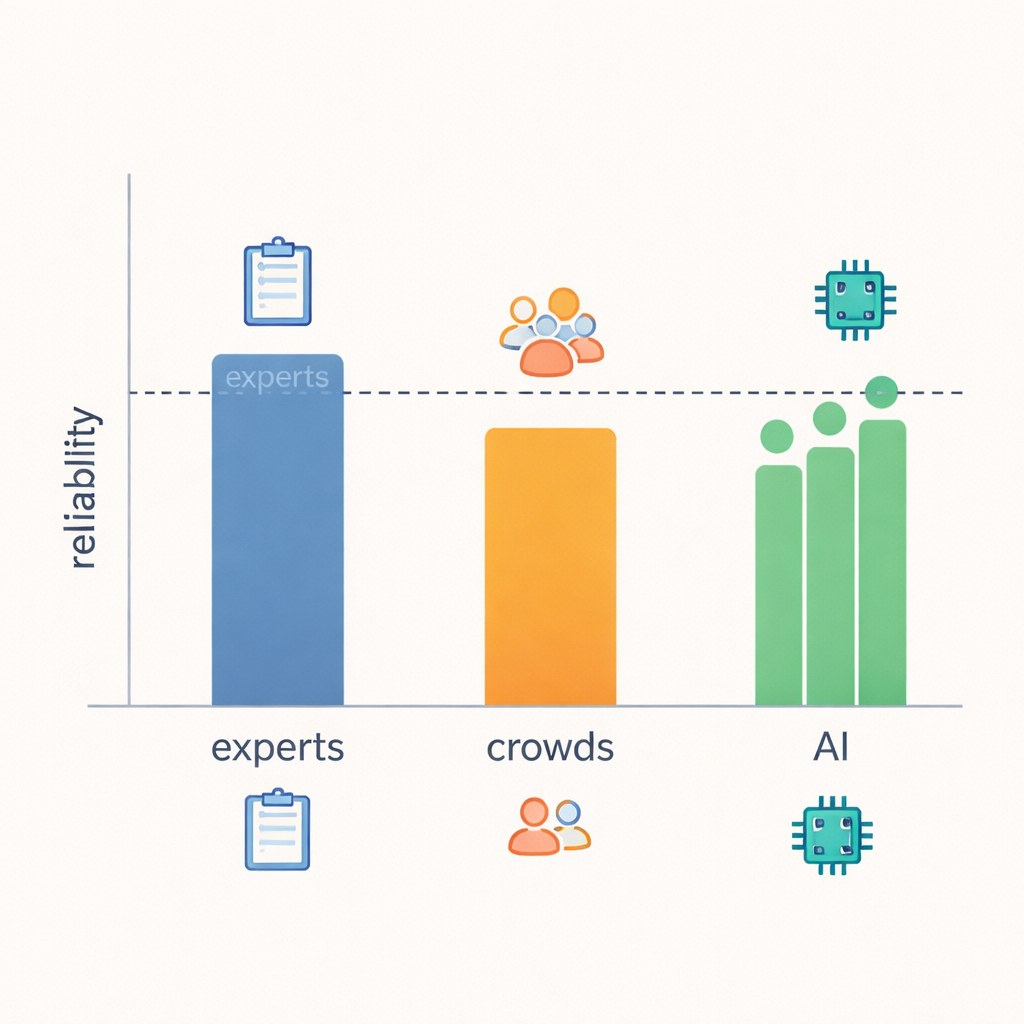
Dans quelle mesure s’accordent‑ils ?
La conclusion principale est que les GML se sont révélés étonnamment proches de la fiabilité de niveau expert. Lorsque les chercheurs ont mesuré la fréquence des concordances et l’ampleur des désaccords, les modèles égalent ou frôlent la performance des experts pour la plupart des 21 comportements, et ils surpassent nettement les évaluateurs issus de la foule. Dans les domaines où les signaux sont clairs et observables — par exemple si une réponse a donné des conseils pratiques, posé des questions de suivi ou ramené l’attention vers la personne qui parlait — experts, GML et même la foule avaient tendance à être plus d’accord. Mais lorsqu’il s’agit de juger des notions plus floues, comme si une réponse « démontrait réellement de la compréhension » ou quelles étaient les intentions du répondant, même les experts étaient plus souvent en désaccord, et la fiabilité des GML baissait avec la leur. Cela suggère que certains aspects de l’empathie sont tout simplement plus difficiles à cerner à partir du texte seul, quel que soit l’évaluateur.
Pourquoi des scores simples peuvent tromper
Be nombreuses études en IA rapportent des succès en utilisant des scores de classification familiers — traitant chaque notation d’expert comme une vérité incontestable et mesurant la fréquence à laquelle un modèle la reproduit. Les auteurs montrent que cette approche peut donner une image déformée lorsqu’il s’agit de jugements humains subtils. Par exemple, un système peut obtenir de bons résultats en devinant surtout la note majoritaire sur une échelle déséquilibrée, même s’il échoue sur des cas rares mais importants. De même, une méthode qui produit souvent des scores « presque corrects » — à un point près — peut paraître mauvaise sur une métrique d’accord strict, alors qu’elle se comporte de manière très proche d’un expert humain. En se concentrant sur la fiabilité inter‑évaluateurs — la cohérence avec laquelle différents juges notent la même chose — l’étude offre un aperçu plus honnête de ce que les humains et les machines peuvent réellement évaluer de façon fiable.
Ce que cela signifie pour l’IA du quotidien
Pour le grand public, la leçon est à la fois porteuse d’espoir et pleine de prudence. Des GML bien configurés peuvent désormais aider à vérifier si des réponses écrites — émanant d’aidants humains ou d’autres bots — répondent aux standards experts de la communication empathique, et ils le font souvent de manière plus cohérente que des évaluateurs humains non formés. Cela pourrait faciliter la surveillance et l’amélioration des chatbots utilisés en santé, en éducation et en service client. Dans le même temps, l’étude avertit que toutes les « évaluations d’empathie » ne se valent pas : des questions vagues ou qui se recoupent entraînent un faible accord humain et, par conséquent, des jugements automatisés fragiles. Avant de faire confiance à l’IA pour noter quelque chose d’aussi délicat que le soutien émotionnel, il convient d’abord de s’assurer que les experts eux‑mêmes peuvent s’accorder sur ce à quoi ressemble une « bonne » réponse — et d’utiliser ce référentiel pour décider où les machines peuvent assister en toute sécurité et où le jugement humain reste indispensable.
Citation: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
Mots-clés: communication empathique, grands modèles de langage, compagnons IA, soutien en santé mentale, interaction humain–IA