Clear Sky Science · fr
Combiner apprentissage fédéré et modèle itinérant améliore les performances et ouvre des opportunités pour l’équité numérique en santé
Pourquoi partager des connaissances médicales sans partager les données est important
La médecine moderne s’appuie de plus en plus sur l’intelligence artificielle pour détecter des motifs dans les scanners et les dossiers de santé. Mais les données des patients sont sensibles et ne peuvent souvent pas quitter l’hôpital où elles ont été collectées. Cela crée une tension : comment des hôpitaux du monde entier peuvent‑ils coopérer pour entraîner des outils d’IA puissants, sans transférer les données brutes des patients à travers les frontières ou vers de grands serveurs centraux ? Cette étude présente un nouveau moyen d’y parvenir, visant non seulement la précision, mais aussi l’équité entre les hôpitaux bien dotés et les cliniques plus petites et moins pourvues en ressources.
Deux façons d’entraîner une IA sans déplacer les données
Aujourd’hui, deux stratégies principales permettent aux hôpitaux d’entraîner l’IA ensemble tout en conservant les données sur site. Dans l’apprentissage fédéré, chaque hôpital entraîne sa propre copie locale d’un modèle en parallèle ; ces modèles locaux sont ensuite combinés en un modèle « global » partagé sur un serveur central. Dans l’approche du modèle itinérant, il n’y a qu’un seul modèle qui se déplace d’hôpital en hôpital, s’entraînant sur chaque site à son tour. Les deux méthodes protègent la confidentialité, mais chacune a des inconvénients. L’apprentissage fédéré peut peiner lorsque certains hôpitaux disposent de très peu de données ou ne voient pas tous les types de patients ; la combinaison de modèles locaux faibles ou déséquilibrés peut aboutir à un modèle global médiocre reflétant principalement les grands sites riches. Le modèle itinérant est plus robuste à ces déséquilibres mais peut être plus lent et plus difficile à gérer.
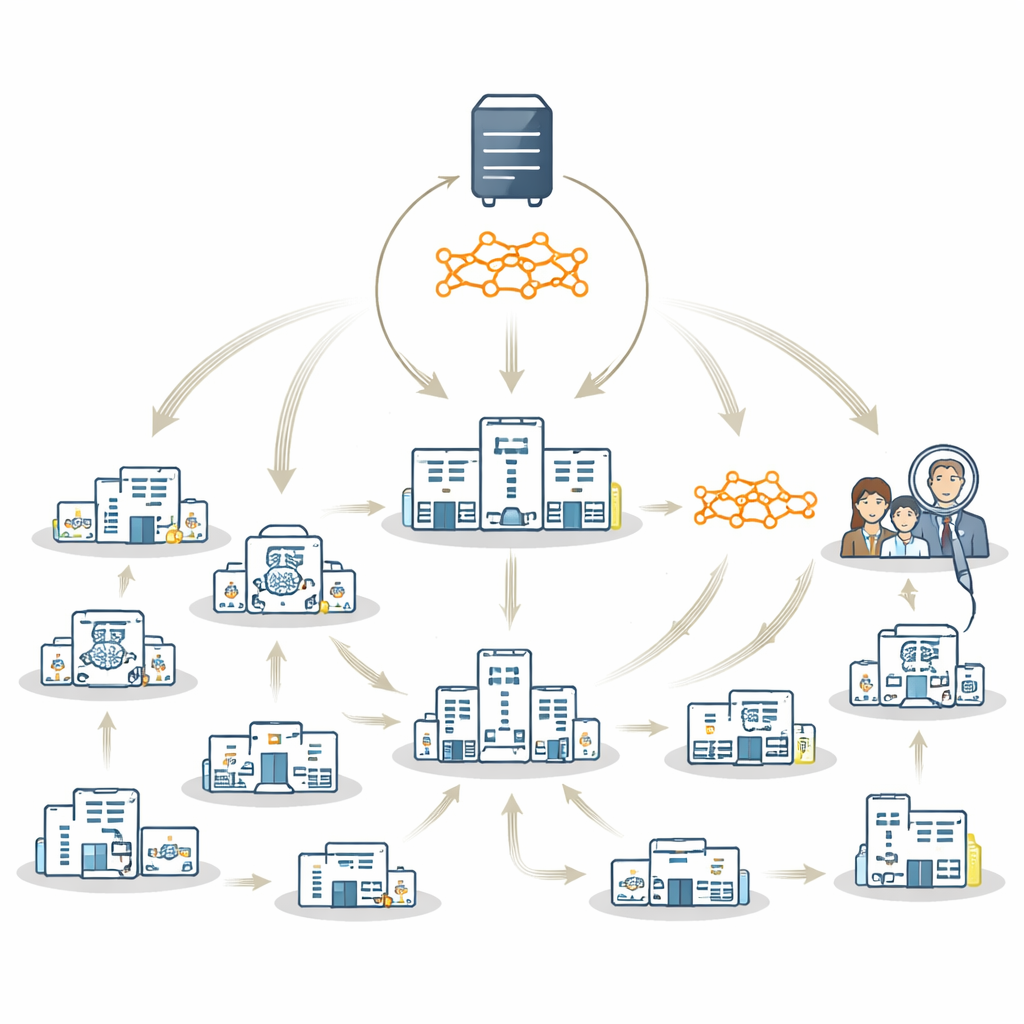
Une stratégie hybride qui tire le meilleur des deux mondes
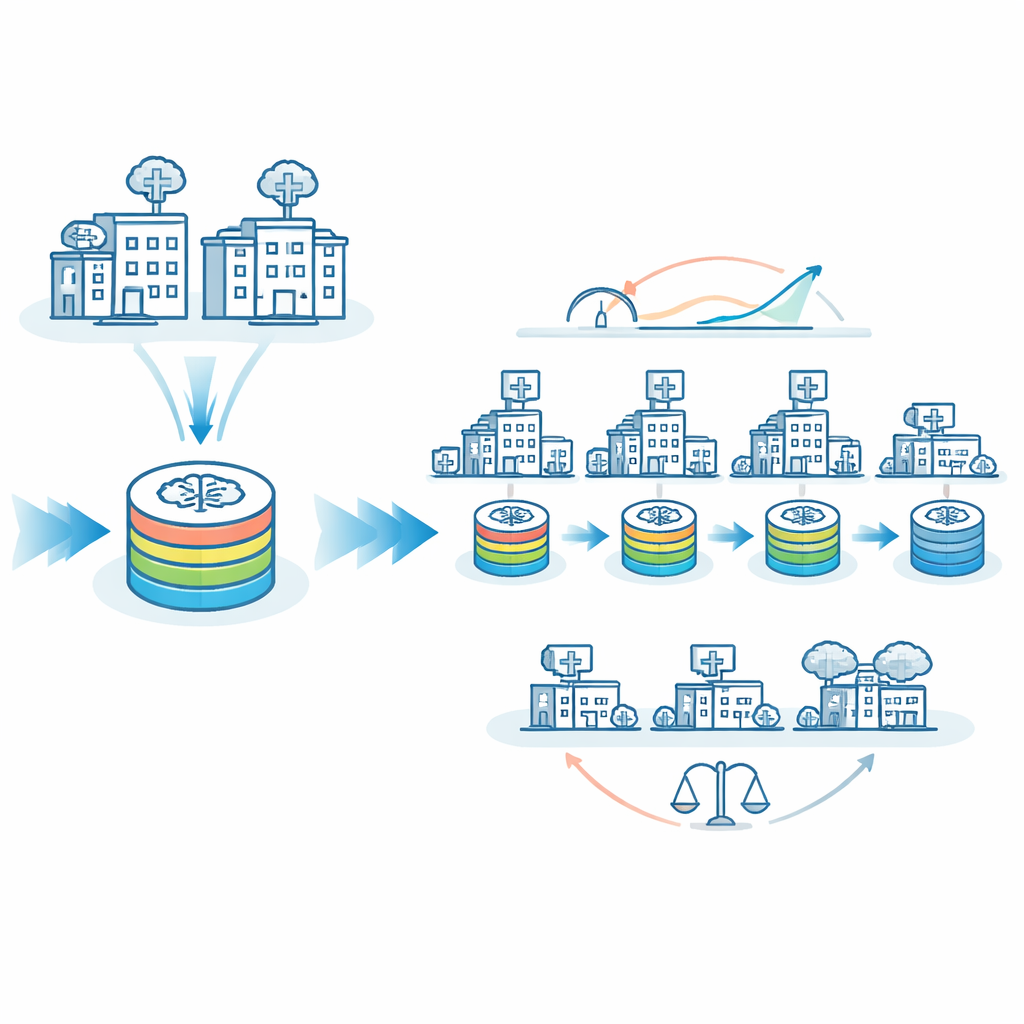
Les auteurs proposent FedTM, un schéma d’entraînement hybride qui mêle les forces de l’apprentissage fédéré et du modèle itinérant. L’entraînement se déroule en deux phases. D’abord une phase de « réchauffement » où seuls les plus grands hôpitaux, disposant d’ensembles de données plus complets et équilibrés, entraînent le modèle en parallèle en utilisant des techniques standard d’apprentissage fédéré. Cela crée un modèle de départ solide. Vient ensuite une phase de « raffinement », où ce modèle réchauffé visite chaque site à la suite, y compris les très petites cliniques qui peuvent n’avoir que quelques scanners cérébraux ou même un seul patient. Dans cette seconde phase, le modèle est progressivement mis à jour au fil du voyage, incorporant les connaissances de chaque site sans jamais nécessiter la sortie des données du contrôle local.
Tester la méthode sur des scanners cérébraux liés à la maladie de Parkinson
Pour évaluer FedTM, les chercheurs ont utilisé 1 817 IRM cérébrales issues de 83 sites d’imagerie dans le monde pour entraîner un système d’IA à distinguer les personnes atteintes de la maladie de Parkinson des individus sains. C’est un contexte particulièrement difficile : plus de la moitié des sites ont fourni moins de dix scanners, seulement environ un tiers disposaient à la fois de données de patients et de témoins sains, et les protocoles d’imagerie différaient largement. Dans ces conditions réelles, l’apprentissage fédéré pur n’a pas réussi à apprendre correctement la tâche, tandis qu’un modèle itinérant pur s’en est mieux sorti mais laissait encore place à l’amélioration. FedTM, en particulier lorsque la phase de réchauffement impliquait les sept sites les plus grands et les plus équilibrés, a clairement surpassé les deux approches : l’aire sous la courbe ROC, mesure standard de la qualité de classification, est passée d’environ 77 % avec le modèle itinérant seul à environ 82 % avec FedTM, avec des gains similaires pour d’autres métriques cliniquement importantes telles que la sensibilité, la spécificité et le F1‑score.
Rendre l’IA plus équitable entre grands et petits hôpitaux
Une préoccupation majeure en IA médicale est l’équité : un modèle fonctionne‑t‑il aussi bien pour les patients des petits hôpitaux ruraux ou sous‑dotés que pour ceux des grands centres académiques ? L’équipe a examiné la fréquence des mauvaises prédictions dans les sites « plus grands » versus « plus petits ». Avec le modèle itinérant seul, les taux de mauvaise classification différaient d’environ 8 points de pourcentage entre ces groupes. Avec FedTM correctement ajusté, les taux de mauvaise classification pour les sites plus grands et plus petits sont devenus presque identiques, autour de 26 %. Autrement dit, le modèle est devenu non seulement plus précis globalement, mais aussi plus équitable. FedTM a aussi déporté la majeure partie du calcul intensif vers la phase de réchauffement dans les sites mieux dotés, réduisant presque de moitié le nombre de cycles d’entraînement que les petits sites devaient effectuer, tout en maintenant un temps d’entraînement total similaire.
Ce que cela signifie pour la santé numérique mondiale
FedTM offre une voie pratique vers des outils d’IA qui respectent la confidentialité, améliorent les performances et répartissent les bénéfices de façon plus équitable à l’échelle mondiale. En permettant même aux sites disposant de très peu de données d’influencer le modèle final, ce cadre peut aider à garantir que les populations des milieux sous‑dotés ou éloignés ne soient pas laissées pour compte lors du développement de nouveaux outils diagnostiques. Bien que l’étude se soit concentrée sur un seul type de scan cérébral et une seule maladie, l’approche peut, en principe, être adaptée à de nombreux autres problèmes médicaux. À mesure que les systèmes de santé adoptent davantage d’appareils mobiles et de capteurs portables, et que les réglementations insistent sur la souveraineté des données, des stratégies hybrides comme FedTM pourraient devenir essentielles pour construire une IA médicale digne de confiance, inclusive et responsable.
Citation: Souza, R., Stanley, E.A.M., Ohara, E.Y. et al. Combining federated learning and travelling model boosts performance and opens opportunities for digital health equity. npj Digit. Med. 9, 294 (2026). https://doi.org/10.1038/s41746-026-02483-y
Mots-clés: apprentissage fédéré, modèle itinérant, maladie de Parkinson, IA en imagerie médicale, équité en santé