Clear Sky Science · fr
Définir la sécurité opérationnelle dans les systèmes d’intelligence artificielle clinique
Pourquoi une IA sûre en médecine importe
Les hôpitaux adoptent rapidement l’intelligence artificielle pour lire les examens et signaler les maladies, mais il existe une question à laquelle les simples scores d’exactitude ne peuvent répondre : quand est‑il réellement sûr de laisser la machine trancher ? Cet article propose une méthode pratique pour décider quand les médecins peuvent faire confiance à un système d’IA, quand ils doivent l’ignorer et quand ils doivent examiner eux‑mêmes le cas de plus près. L’objectif n’est pas seulement de concevoir des algorithmes plus performants, mais de les intégrer dans les soins quotidiens de manière à protéger les patients, réduire les tests inutiles et alléger la charge des cliniciens plutôt que de l’alourdir.
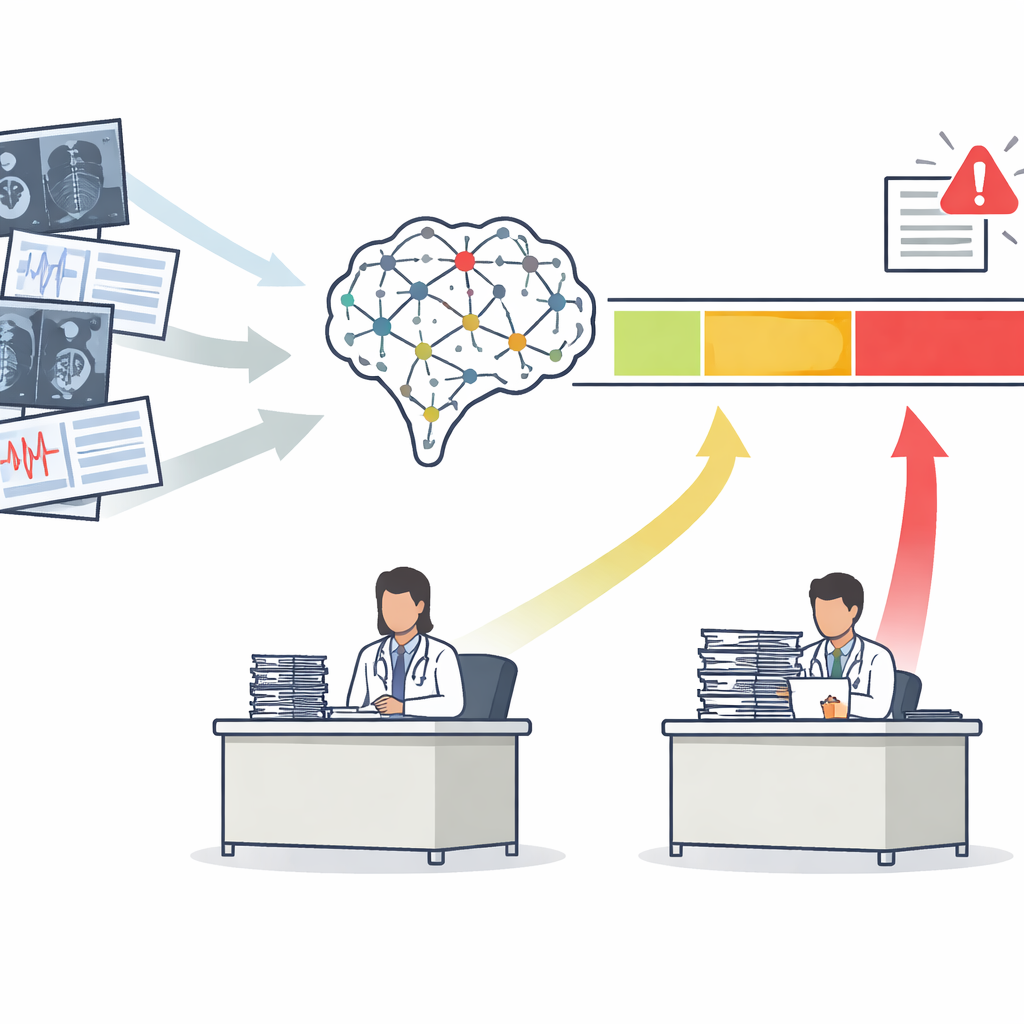
Passer d’un score unique à trois zones d’action claires
La plupart des outils d’IA médicale produisent un score de risque unique, par exemple la probabilité qu’une mammographie révèle un cancer. Traditionnellement, les développeurs évaluent ces outils avec une courbe qui résume leur capacité à séparer globalement les patients malades des patients sains. Les auteurs soutiennent que cela ne suffit pas. Ils proposent le cadre Safety‑Aware ROC (SA‑ROC), qui part des mêmes scores de risque mais les reconfigure en trois régions pratiques. Une zone « rule‑in » à score élevé regroupe les patients dont les résultats sont suffisamment fiables pour déclencher une action, comme un suivi urgent. Une zone « rule‑out » à score faible regroupe les patients dont les résultats sont suffisamment fiables pour être dépriorisés en toute sécurité. Entre les deux se trouve une « zone grise » d’incertitude, où l’IA n’est pas assez digne de confiance et où un expert humain doit examiner le cas.
Permettre aux cliniciens de fixer le seuil de sécurité
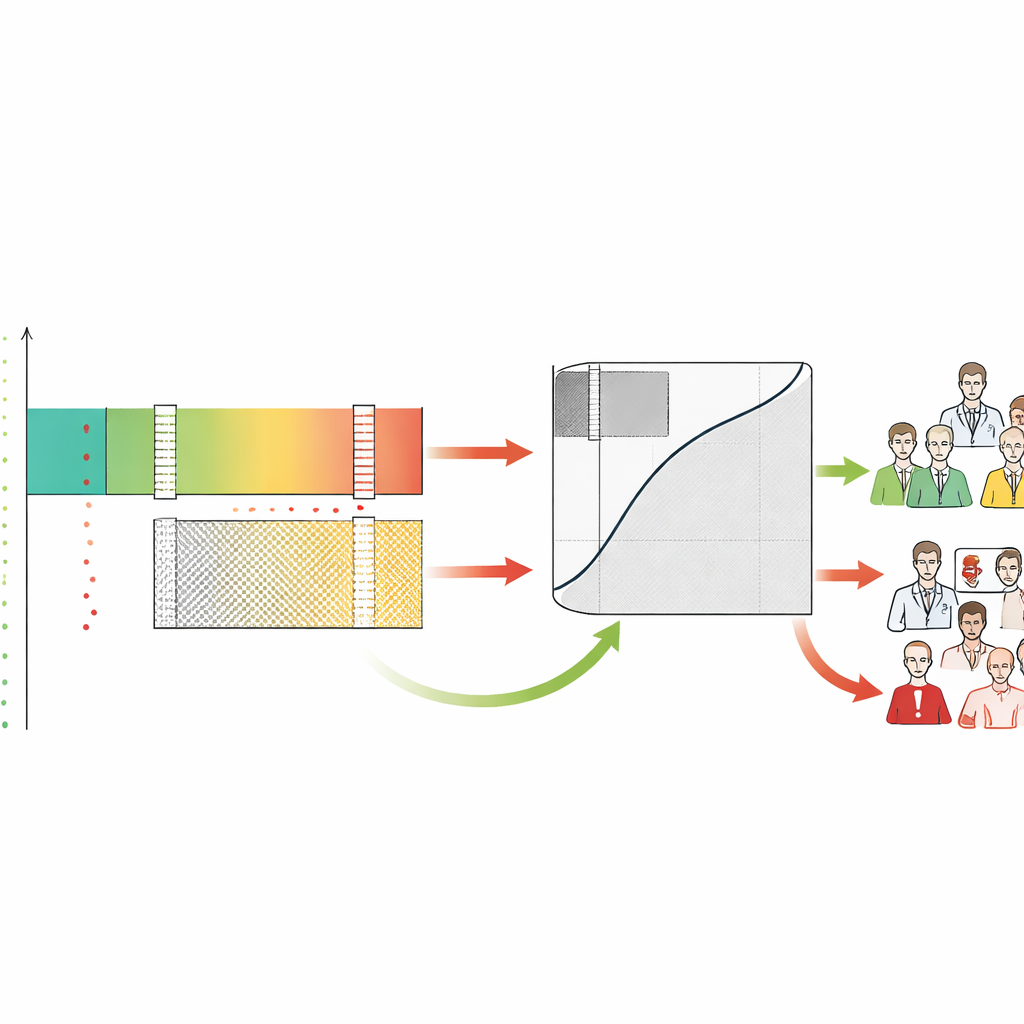
De manière cruciale, SA‑ROC permet aux cliniciens et aux institutions de définir eux‑mêmes des objectifs de sécurité dès le départ. Ils choisissent à quel degré de certitude ils veulent agir sur un résultat positif (la probabilité minimale acceptable qu’une anomalie signalée soit réellement présente) et à quel degré de certitude ils veulent s’autoriser à relâcher la prise en charge sur un résultat négatif (la probabilité minimale acceptable qu’un cas jugé clair soit réellement normal). À partir de ces cibles, le cadre parcourt les scores du modèle pour trouver les bornes exactes qui les satisfont. Les scores au‑dessus de la borne supérieure forment la zone sûre de rule‑in, les scores en dessous de la borne inférieure forment la zone sûre de rule‑out, et tout ce qui se situe entre devient la zone grise. Le cadre quantifie ensuite combien de patients se retrouvent dans chaque région et quelle charge d’incertitude — cas renvoyés aux humains — l’IA laisse non résolue.
Faire apparaître des différences cachées entre IA similaires
Les auteurs montrent que deux systèmes d’IA ayant des scores d’exactitude traditionnels presque identiques peuvent se comporter très différemment lorsqu’on les regarde sous cet angle de sécurité. Dans des simulations, des modèles avec une performance globale similaire ont produit des tailles très différentes de zones de rule‑in, rule‑out et grises selon la distribution de leurs scores. L’un pouvait exceller pour confirmer la maladie avec confiance, tandis qu’un autre pouvait exceller pour écarter en toute sécurité un grand nombre de patients à faible risque. Dans une étude de cas réelle portant sur deux outils autorisés par la Food and Drug Administration américaine pour le dépistage du cancer du sein, le système affichant le score d’exactitude standard le plus élevé était en réalité moins performant pour le dépistage à haute confiance. Au réglage de sécurité le plus strict — n’autorisant aucun cancer manqué dans le groupe à faible risque — le système apparemment plus faible a permis d’exclure en toute sécurité près de deux fois plus de femmes de la file d’attente du radiologue. SA‑ROC met ainsi en évidence une sorte de « renversement de performance » que les métriques conventionnelles masquent.
Comprendre la tension humain–IA et la charge de travail
En étiquetant chaque cas comme rule‑in, rule‑out ou gris, le cadre révèle aussi comment les médecins se comportent dans ces zones. Les auteurs ont constaté que les radiologues avaient souvent tendance à sur‑interpréter des cas que l’IA jugeait à faible risque sûr, générant de nombreuses fausses alertes précisément dans la région où la machine était la plus fiable. En revanche, humains et IA peinaient tous deux dans la zone grise, ce qui la valide comme la zone nécessitant véritablement l’attention d’un expert. SA‑ROC capture la taille de cette zone grise par un seul nombre, qui représente le coût de l’indécision. Une petite zone grise signifie plus d’automatisation sûre et moins de charge humaine ; une grande zone grise signifie que de nombreux cas requièrent encore une revue manuelle attentive et que le système peut accroître l’épuisement professionnel plutôt que de l’atténuer.
Transformer les règles de sécurité en pratique quotidienne
Au‑delà de la mesure, le cadre est conçu comme un outil de gouvernance qui transforme les politiques en comportements concrets de l’IA. Les hôpitaux peuvent l’utiliser de deux façons. Premièrement, ils peuvent spécifier directement des exigences de sécurité ou des limites sur le nombre de cas qu’ils sont prêts à envoyer dans la zone grise et laisser le cadre calculer les seuils correspondants. Deuxièmement, ils peuvent attribuer des valeurs et des pénalités à différents résultats — détecter un cancer, en manquer un, prescrire un examen inutile ou renvoyer à une revue humaine — et demander au cadre de rechercher la politique qui maximise le bénéfice global. Ces stratégies peuvent être ajustées pour des objectifs très différents, tels que des programmes de dépistage de masse, des orientations vers des spécialistes ou des cohortes de recherche, en utilisant toutes le même modèle sous‑jacent.
Ce que cela signifie pour les patients et les cliniciens
En termes simples, ce travail offre un moyen de dire non seulement « cette IA est précise », mais « voici exactement quand et comment elle peut être fiable en clinique ». En découpant les sorties de l’IA en régions sûres, non sûres et incertaines liées à des promesses de sécurité explicites, SA‑ROC aide les systèmes de santé à décider quand les machines peuvent agir seules et quand les humains doivent garder la maîtrise. Il souligne que les scores d’exactitude traditionnels peuvent être trompeurs et que la véritable sécurité dépend du comportement d’un modèle aux extrémités où les erreurs sont les plus coûteuses. Si ce cadre est largement adopté et validé dans des contextes réels plus vastes, il pourrait favoriser une automatisation plus fiable, réduire les fausses alertes et les examens inutiles, et transformer les cas d’IA les plus difficiles — la zone grise — en un point focal d’apprentissage et d’amélioration pour les algorithmes et la médecine elle‑même.
Citation: Kim, YT., Kim, H., Bahl, M. et al. Defining operational safety in clinical artificial intelligence systems. npj Digit. Med. 9, 281 (2026). https://doi.org/10.1038/s41746-026-02450-7
Mots-clés: intelligence artificielle clinique, sécurité opérationnelle, imagerie médicale, aide à la décision, stratification du risque