Clear Sky Science · fr
Modèles d’apprentissage automatique pour la prédiction des interactions médicamenteuses : de la découverte computationnelle à l’application clinique
Pourquoi combiner des médicaments peut être risqué
La médecine moderne repose souvent sur la prise simultanée de plusieurs médicaments — pour le cancer, les maladies cardiaques, les infections, ou simplement pour gérer les multiples affections liées à l’âge. Mais lorsque des médicaments se rencontrent dans l’organisme, ils peuvent modifier les effets des uns et des autres, rendant parfois le traitement moins efficace voire dangereux. Cette revue examine la manière dont l’intelligence artificielle, en particulier les méthodes modernes d’apprentissage automatique, est utilisée pour prédire à l’avance ces interactions médicamenteuses, afin que les médecins puissent choisir des combinaisons plus sûres et adapter les traitements à chaque patient.
Du tâtonnement aux prévisions fondées sur les données
Traditionnellement, les combinaisons médicamenteuses problématiques ont été découvertes à la dure — lors des essais cliniques de phase avancée ou après la commercialisation d’un médicament, quand des patients en ont été lésés. Les tests en laboratoire sur cellules, animaux et volontaires restent la référence, mais ils sont lents, coûteux et impossibles à appliquer à l’énorme nombre de paires potentielles de médicaments. Les auteurs soutiennent que la prédiction computationnelle offre une issue à ce goulot d’étranglement. En apprenant à partir d’énormes collections numériques d’informations pharmaceutiques — telles que les structures chimiques, les cibles biologiques, les effets secondaires connus et les signalements réels d’effets indésirables — les systèmes d’apprentissage automatique peuvent repérer des paires à risque bien avant qu’elles n’atteignent un grand nombre de patients.
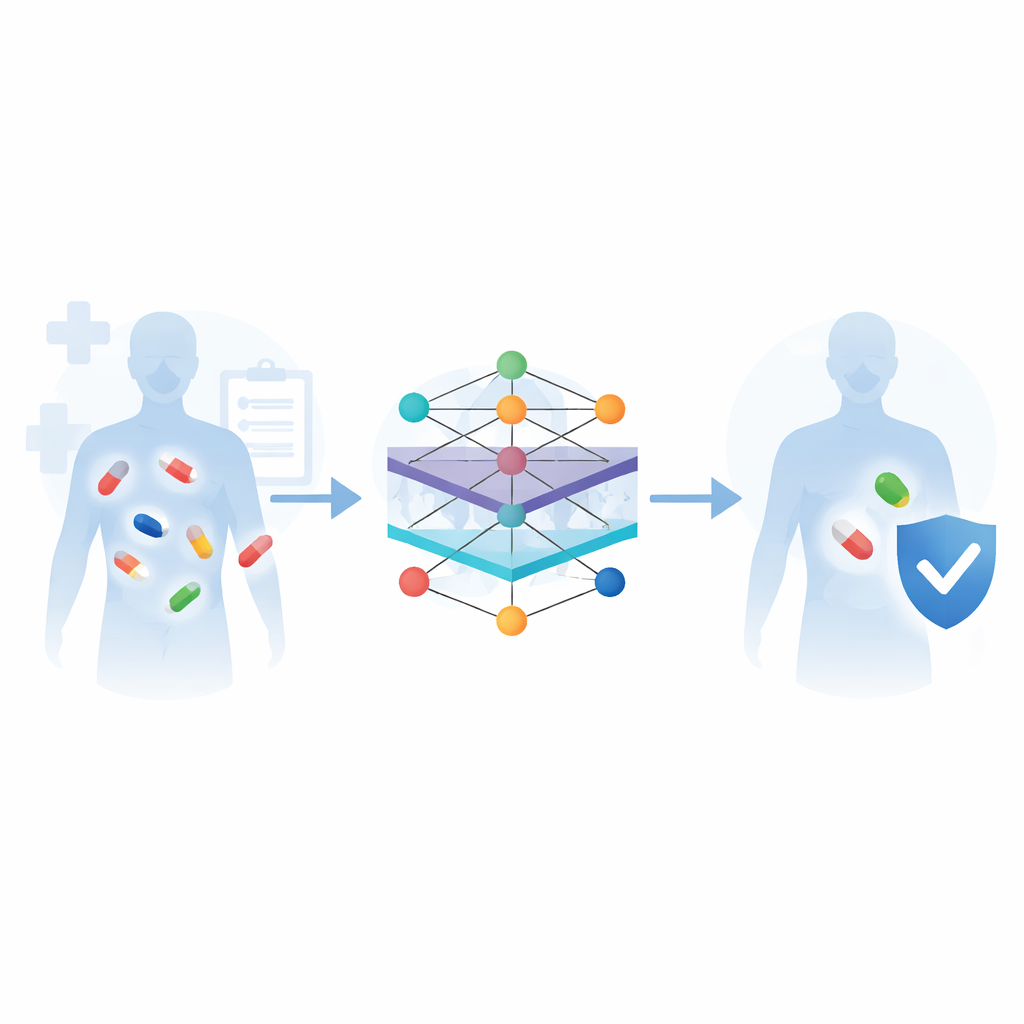
Comment les machines apprennent à partir de divers types de données médicamenteuses
La revue décrit un flux de travail courant pour ces systèmes de prédiction. D’abord, on collecte des informations dans les principales bases de données biomédicales : bibliothèques chimiques décrivant l’apparence de chaque molécule, cartes de voies métaboliques montrant comment les médicaments sont traités dans l’organisme, et listes annotées d’interactions et d’effets indésirables connus. Ensuite, des algorithmes convertissent ces données brutes en motifs numériques compréhensibles par ordinateur — par exemple en mesurant la similarité entre deux médicaments, ou en représentant chaque médicament comme un nœud dans un réseau relié à ses cibles, voies et réactions passées. Différents modèles d’apprentissage automatique sont alors entraînés à reconnaître quelles paires de médicaments tendent à poser problème, et leurs performances sont évaluées sur des jeux de données de référence à l’aide de mesures standard d’exactitude.
Différentes familles d’algorithmes abordent le problème chacune à leur manière
Parce que les interactions médicamenteuses sont complexes, aucun type de modèle n’est optimal dans toutes les situations. Certaines approches reposent sur des classifieurs traditionnels utilisant des caractéristiques conçues manuellement, tandis que d’autres apprennent directement à partir de la structure des molécules ou du réseau de connexions entre médicaments et entités biologiques. Les méthodes basées sur les graphes et l’apprentissage profond ont été particulièrement performantes : elles traitent les médicaments et leurs relations comme un réseau, permettant à l’algorithme de « raisonner » sur des chaînes de connexions qui échappent souvent aux modèles plus simples. D’autres stratégies partagent l’information entre tâches connexes, comme prédire à la fois si deux médicaments interagissent et quel type d’effet ils produisent, ce qui aide lorsque les données sont rares. L’article met également en lumière de nouvelles directions telles que les grands modèles de langage qui lisent textes scientifiques et notes cliniques, et les modèles génératifs qui explorent des schémas d’interaction possibles dans des jeux de données très vastes et épars.
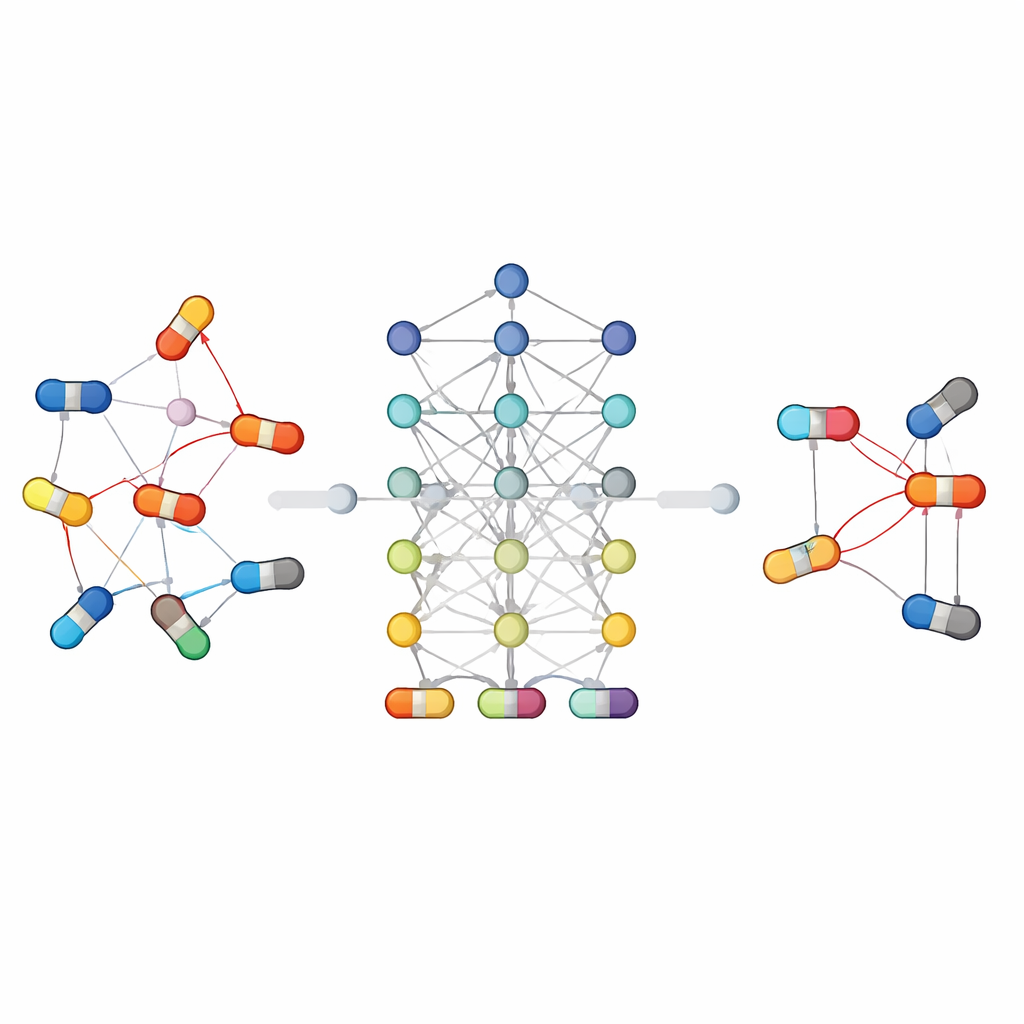
Relier les prédictions informatiques aux patients réels
Au-delà des méthodes, l’article insiste sur la manière dont ces outils peuvent soutenir les soins en conditions réelles. Les auteurs discutent de la façon dont des modèles entraînés sur des bases de données annotées et des dossiers cliniques peuvent alerter les cliniciens sur des combinaisons dangereuses au chevet, aider à concevoir des schémas thérapeutiques multi-médicaments plus sûrs en oncologie, cardiologie et maladies infectieuses, et prioriser les interactions prédites qui méritent des tests en laboratoire. Ils passent aussi en revue des exemples cliniques classiques — tels que des antibiotiques modifiant les niveaux de médicaments hypolipémiants, des antalgiques s’opposant mutuellement, ou des jus de fruits augmentant de façon inattendue les concentrations de médicaments — pour montrer les nombreux mécanismes par lesquels surgissent les interactions. Les systèmes d’apprentissage automatique capturant ces motifs peuvent ainsi servir d’appareils d’alerte précoce, en particulier chez les patients âgés prenant de nombreux médicaments.
Les défis pour aboutir à une IA digne de confiance pour les médicaments
Malgré des performances impressionnantes sur des jeux de test, les auteurs soulignent que les modèles actuels rencontrent encore des obstacles importants avant de pouvoir être largement adoptés en clinique. Beaucoup demeurent des « boîtes noires » offrant peu d’explications sur les raisons pour lesquelles une paire spécifique est jugée à risque, ce qui complique l’évaluation et l’explication de la recommandation par les médecins. Les modèles peuvent buter lorsque les données sont bruyantes ou déséquilibrées — par exemple lorsque les interactions nuisibles sont rares par rapport aux paires sûres. Intégrer des informations provenant de la chimie, de la génétique, des dossiers de santé électroniques et de la littérature publiée est techniquement difficile, et les cadres réglementaires exigent des preuves solides avant que de tels outils puissent influer sur la prescription. Les auteurs plaident pour des travaux futurs axés sur des modèles plus interprétables, une meilleure gestion des données biaisées et incomplètes, et des systèmes capables d’apprendre en continu à partir de nouvelles expériences cliniques tout en respectant les règles de confidentialité et de sécurité.
Qu’est-ce que cela signifie pour le traitement quotidien
En termes simples, cette revue montre que l’intelligence artificielle devient un allié puissant pour sécuriser les associations médicamenteuses. En filtrant des montagnes de données numériques bien au-delà de ce qu’un expert humain peut gérer, les modèles d’apprentissage automatique peuvent mettre en lumière des paires dangereuses, suggérer des alternatives plus sûres et soutenir des prescriptions plus personnalisées. Ces outils ne remplaceront pas le jugement clinique ni les tests de laboratoire rigoureux, mais ils peuvent contribuer à ce que la complexité croissante des thérapies modernes ne se fasse pas au détriment de la sécurité des patients.
Citation: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
Mots-clés: interactions médicamenteuses, apprentissage automatique en médecine, réseaux neuronaux graphiques, pharmacologie clinique, sécurité de l’intelligence artificielle