Clear Sky Science · fr
Évaluation des grands modèles de langage pour la génération d’un impression diagnostique à partir des constatations d’IRM cérébrale : étude de référence multicentrique et étude lecteur
Pourquoi des comptes rendus d’IRM plus intelligents comptent pour les patients
Lorsque vous passez un scanner cérébral, un radiologue doit transformer des milliers de nuances de gris en une déclaration claire sur ce qui ne va pas — ou sur le fait que tout semble normal. Cette « impression » finale guide des décisions cruciales concernant la prise en charge des AVC, les tumeurs cérébrales, les infections et plus encore. Mais la lecture des IRM cérébrales est complexe et prend du temps, et des médecins surchargés peuvent commettre des erreurs, surtout dans des hôpitaux très occupés. Cette étude examine si des modèles de langage avancés peuvent aider de manière fiable les radiologues à convertir des constatations écrites d’IRM en impressions diagnostiques précises, rapides et cohérentes.
Transformer des descriptions brutes d’examen en réponses claires
Les IRM cérébrales produisent une série d’images que les radiologues décrivent dans une section « constatations », notant par exemple où se situe une lésion, son aspect en intensité et la présence éventuelle d’un œdème. Le véritable défi est ensuite de combiner tous ces éléments en une impression diagnostique, comme « infarctus aigu » ou « abcès cérébral ». Les chercheurs ont rassemblé 4 293 comptes rendus d’IRM cérébrale provenant de trois hôpitaux en Chine, couvrant 16 catégories diagnostiques qui incluent plus de 95 % des affections cérébrales courantes. Ils ont ensuite testé 10 grands modèles de langage différents — des systèmes d’IA textuels avancés — pour évaluer dans quelle mesure chacun pouvait convertir les constatations écrites en diagnostics corrects.
Les gros modèles bien entraînés arrivent en tête
L’équipe a comparé des modèles allant d’environ 8 milliards à 671 milliards de paramètres internes, ce qui peut être grossièrement comparé à un passage des connaissances d’un étudiant en médecine à celles d’une équipe d’experts. Le plus grand modèle, appelé DeepSeek‑R1, a systématiquement obtenu les meilleures performances lorsqu’on lui fournissait à la fois des versions structurées des constatations et des informations cliniques clés telles que l’âge du patient, les symptômes ou des antécédents de traumatisme. Dans ces conditions, DeepSeek‑R1 identifiait correctement la présence ou l’absence de conditions cérébrales spécifiques avec une sensibilité et une spécificité élevées, atteignant une précision au niveau du patient supérieure à 87 %. Les modèles plus petits, en particulier ceux en dessous de 10 milliards de paramètres, ont eu de grandes difficultés, ne trouvant souvent la bonne réponse que dans environ 30 % des cas — bien en deçà de ce qui serait acceptable en pratique clinique réelle.
Pourquoi la structure et le contexte rendent l’IA plus performante
Les chercheurs n’ont pas simplement soumis aux modèles du texte libre. Ils ont aussi utilisé un autre système d’IA pour restructurer les comptes rendus en éléments clairs et standardisés : localisation de chaque lésion, nombre de lésions, et leur aspect sur différentes séquences IRM. Ajouter cette structure, et la combiner avec de courts éléments cliniques, a fait une différence frappante. Pour DeepSeek‑R1, le passage de constatations en texte libre à des constatations structurées plus le contexte clinique a augmenté la sensibilité, la précision globale et les mesures synthétiques de performance. En termes simples, l’IA a beaucoup mieux performé lorsqu’on lui fournissait des informations plus propres et organisées et un peu de contexte patient — ce qui reflète la manière dont les radiologues humains travaillent mieux quand les rapports sont soignés et que la question clinique est claire.
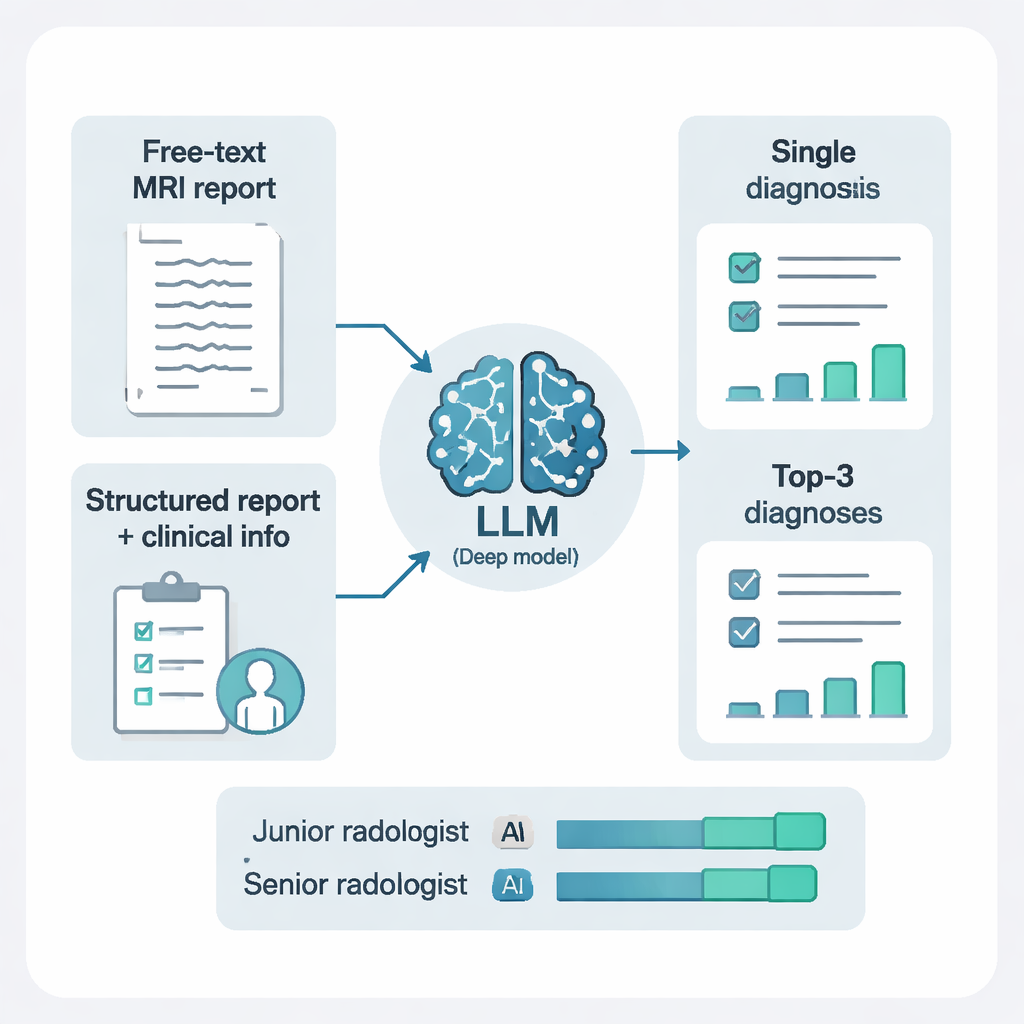
Passer d’une seule hypothèse à une liste courte classée
Dans la pratique, les radiologues proposent souvent plus d’un diagnostic possible pour les cas difficiles. L’étude a testé deux styles d’invite : demander à l’IA un seul diagnostic, ou demander ses trois premières possibilités, chacune avec une brève explication. Autoriser trois diagnostics classés a considérablement amélioré les performances. Avec cette approche de « diagnostic différentiel », la bonne réponse figurait parmi les trois premières suggestions pour plus de 97 % des patients. Cela a été particulièrement utile dans des cas complexes comme les tumeurs, les hémorragies ou les maladies inflammatoires, où une seule réponse forcée peut induire en erreur mais une courte liste argumentée peut orienter efficacement les examens et traitements complémentaires.
Impact réel pour des radiologues surchargés
Pour savoir si ces gains ont un impact en pratique, les auteurs ont mené une étude lecteur avec six radiologues — trois juniors et trois seniors — qui ont interprété 500 comptes rendus d’IRM cérébrale avec et sans l’aide de DeepSeek‑R1. Avec l’assistance de l’IA, la précision diagnostique globale est passée d’environ les trois quarts des cas à plus de 90 %, et une mesure clé alliant précision et rappel s’est également améliorée de façon substantielle. Le temps de lecture a diminué aussi, passant d’environ une minute par cas à moins d’une minute, ce qui pourrait se traduire par des dizaines d’heures gagnées par radiologue chaque année. Les plus grands bénéfices ont été observés chez les radiologues juniors, dont les performances se sont rapprochées de celles d’experts aguerris, bien que l’étude souligne aussi que les médecins doivent rester prudents et ne pas faire une confiance aveugle à l’IA, en particulier pour des affections très subtiles comme certains types d’hémorragie cérébrale.
Ce que cela signifie pour les futurs comptes rendus de scanners cérébraux
Pour les patients, la conclusion principale est que des systèmes d’IA puissants basés sur le langage peuvent déjà aider les radiologues à transformer des descriptions IRM complexes en impressions diagnostiques plus claires et plus précises, surtout lorsqu’ils reçoivent des informations bien structurées et des éléments cliniques clés. Ces outils ne remplacent pas l’expertise humaine mais peuvent agir comme une seconde paire d’yeux attentive, offrant des suggestions argumentées et faisant gagner du temps. Si ces approches sont validées plus largement et intégrées de manière sûre dans les systèmes hospitaliers, ce soutien par l’IA pourrait contribuer à rendre les comptes rendus d’IRM cérébrale plus rapides, plus fiables et plus cohérents — améliorant in fine la prise en charge des personnes atteintes d’AVC, de tumeurs, d’infections et de nombreuses autres affections cérébrales.
Citation: Wang, ML., Zhang, RP., Wu, WJ. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. npj Digit. Med. 9, 187 (2026). https://doi.org/10.1038/s41746-026-02380-4
Mots-clés: diagnostic IRM cérébrale, intelligence artificielle en radiologie, grands modèles de langage, aide à la décision clinique, DeepSeek-R1