Clear Sky Science · fr
Les grands modèles de langage améliorent la transférabilité des prédictions basées sur les dossiers de santé électroniques entre pays et systèmes de codage
Pourquoi un partage plus intelligent des données médicales importe
Hôpitaux et cliniques du monde entier disposent d’une mine d’or d’informations : des dossiers de santé électroniques qui consignent diagnostics, traitements et résultats sur de nombreuses années. En théorie, ces données pourraient aider les médecins à repérer tôt les personnes à haut risque de maladies graves, bien avant que les symptômes ne se manifestent. En pratique, toutefois, les modèles informatiques actuels peinent à « voyager » d’un pays ou d’un système hospitalier à un autre parce que chaque lieu enregistre les données de santé différemment. Cette étude présente une nouvelle approche, appelée GRASP, qui utilise les progrès de l’intelligence artificielle pour combler ces écarts afin qu’un modèle entraîné dans un système de santé puisse fonctionner de manière fiable dans d’autres.
Des hôpitaux différents, des langages différents
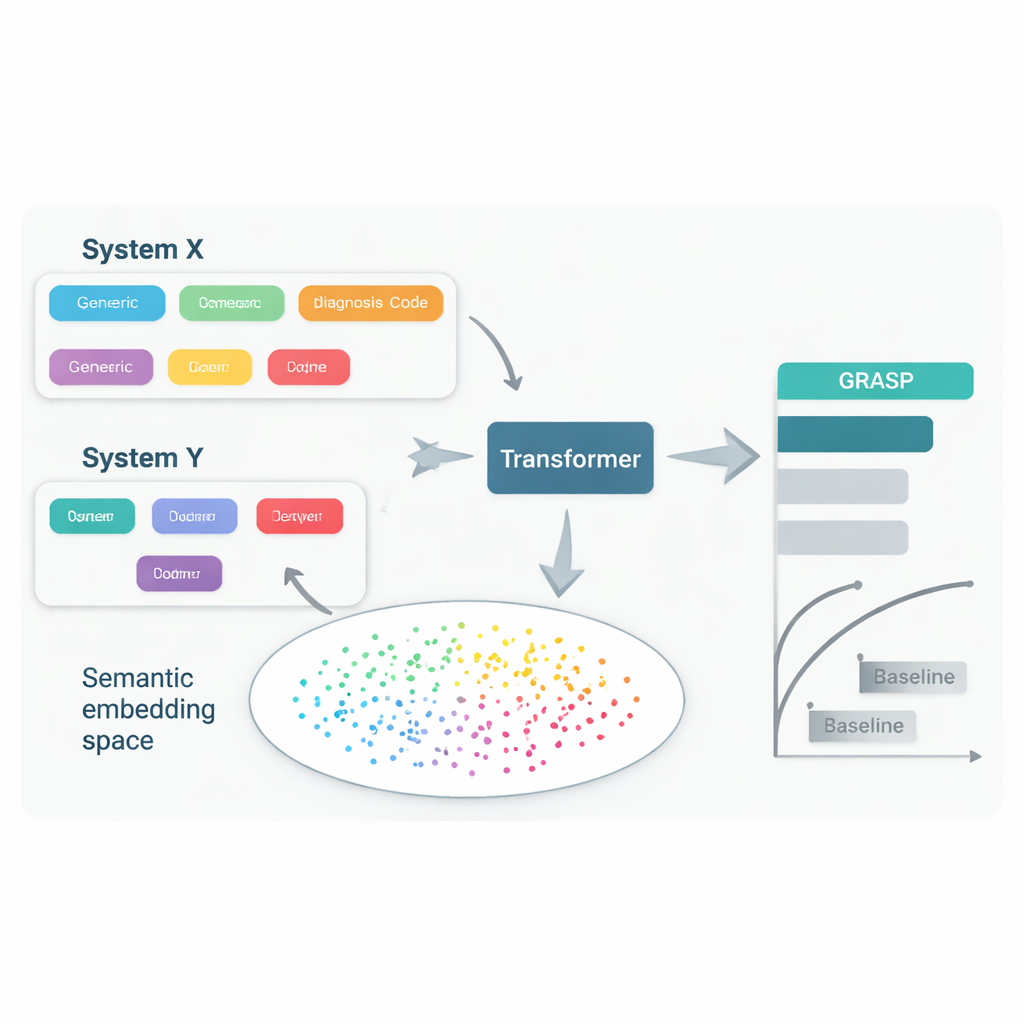
Même lorsque les médecins traitent la même maladie, ils utilisent souvent des systèmes de codes et des habitudes locales différents pour l’enregistrer dans le dossier médical. Un hôpital peut stocker « glycémie élevée » sous un code, tandis qu’un autre utilise un code différent pour « hyperglycémie », et un troisième adopte un système encore différent. Les efforts visant à imposer un standard commun — comme les grands schémas de codage internationaux — sont utiles mais lents, coûteux et laissent encore des différences importantes. En conséquence, un modèle informatique qui prédit une maladie à partir des dossiers d’un pays peut perdre en précision lorsqu’on l’applique ailleurs, limitant ainsi qui peut bénéficier de ces outils.
Laisser l’IA lire le sens, pas seulement le code
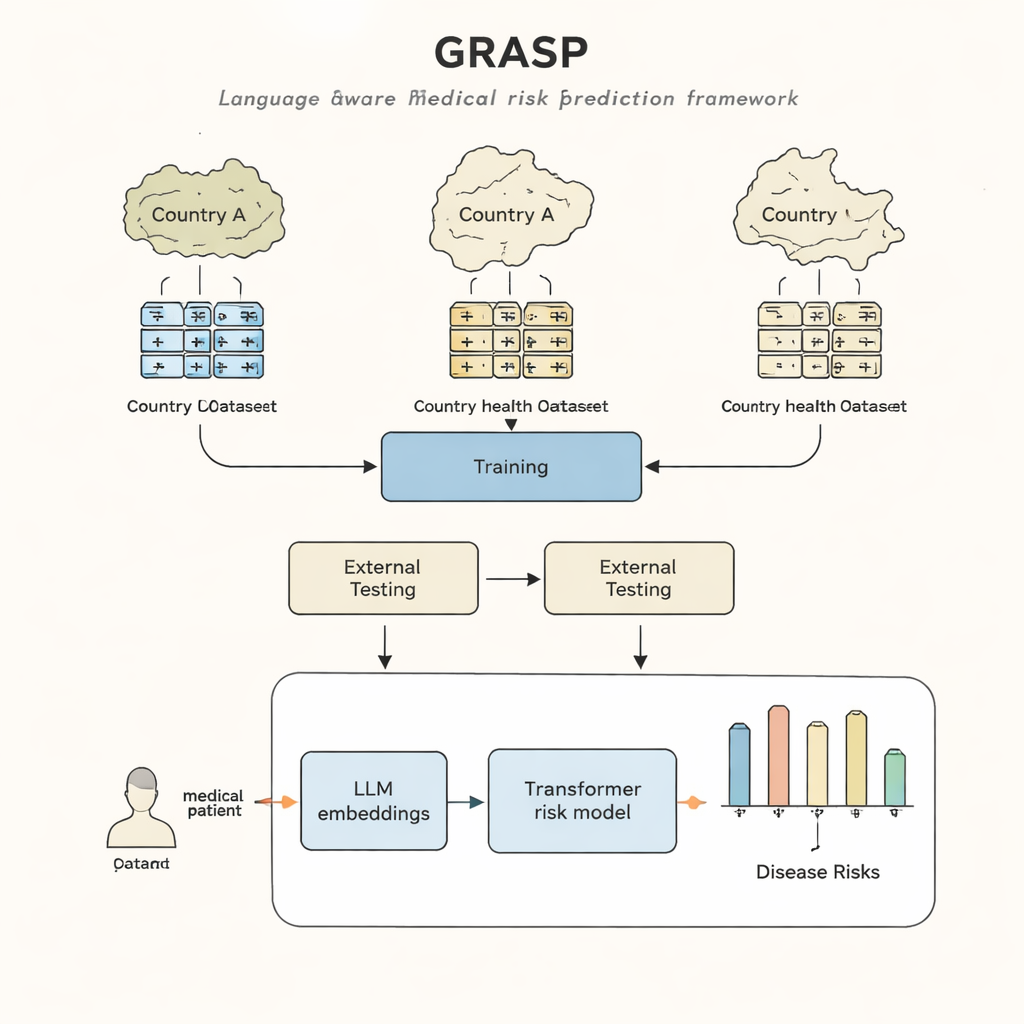
L’approche GRASP part d’une idée simple : plutôt que de traiter chaque code médical comme un numéro d’identification dépourvu de sens, laisser un grand modèle de langage lire la description humaine qui le sous-tend, telle que « infection aiguë des voies respiratoires supérieures », et transformer ce sens en un « embedding » numérique. Ces embeddings placent les concepts liés proches les uns des autres dans un espace partagé, même s’ils proviennent de systèmes de codage ou de pays différents. GRASP pré-calcul des embeddings pour des millions de termes médicaux standard et les stocke dans une table de consultation. L’historique médical d’un patient est ensuite représenté comme une série de ces vecteurs riches, qui sont fournis à un réseau de type transformer — un type de réseau neuronal bien adapté au traitement de collections d’entrées diverses — pour estimer le risque de 21 maladies majeures ainsi que le risque global de décès.
Tester à travers pays et systèmes de dossiers
Les chercheurs ont entraîné GRASP en utilisant les données de près de 400 000 participants du UK Biobank, puis l’ont testé sans réentraînement dans deux contextes très différents : le projet FinnGen en Finlande et un grand réseau hospitalier de New York. GRASP a égalé ou surpassé de solides alternatives, y compris une méthode populaire appelée XGBoost et un transformer similaire qui n’utilisait pas d’embeddings basés sur le langage. En Finlande, GRASP a particulièrement bien performé, montrant des gains nets pour des affections telles que l’asthme, la maladie rénale chronique et l’insuffisance cardiaque. Fait remarquable, même lorsque les données hospitalières américaines sont restées dans un schéma de codage différent au lieu d’être converties vers une norme commune, GRASP a tout de même fourni de meilleures prédictions que les seules données démographiques, parce qu’il pouvait aligner les codes simplement en comprenant la formulation de leurs descriptions.
Obtenir plus avec moins de données
Un autre avantage de GRASP est son efficacité. Parce que le modèle de langage a déjà appris que de nombreux concepts médicaux sont liés, le réseau de prédiction n’a pas besoin de redécouvrir ces liens à partir de zéro. Lorsque les auteurs ont entraîné GRASP sur des sous-ensembles beaucoup plus petits des données britanniques — jusqu’à seulement 10 000 personnes — il a tout de même surpassé les modèles concurrents entraînés sur ces mêmes échantillons limités, tant au Royaume-Uni que lors du transfert à l’étranger. Les scores de risque produits par GRASP étaient également plus étroitement corrélés au risque génétique hérité des personnes pour plusieurs maladies, ce qui suggère qu’il capture des aspects plus profonds de la susceptibilité aux maladies plutôt que de se contenter de mémoriser des motifs dans un seul jeu de données.
Ce que cela signifie pour les soins futurs
Pour les non-spécialistes, le message clé est que GRASP montre comment l’IA moderne basée sur le langage peut aider différents systèmes de santé à « parler la même langue » sans les contraindre à un schéma de codage unique et rigide. En lisant le sens des termes médicaux, GRASP peut produire des prédictions de risque de maladie qui se généralisent mieux entre pays et formats de dossiers, et le faire avec moins d’exemples de patients. Si la méthode nécessite encore des tests attentifs, des recalibrages et des vérifications d’équité avant son utilisation en pratique courante, elle ouvre la voie à un avenir où des outils de prédiction puissants développés en un lieu peuvent être partagés de manière sûre et efficace avec des hôpitaux et cliniques du monde entier.
Citation: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Mots-clés: dossiers de santé électroniques, prévision du risque de maladie, grands modèles de langage, partage de données médicales, IA en santé