Clear Sky Science · fr
Comparer l’apprentissage machine décentralisé et les modèles cliniques d’IA aux alternatives locales et centralisées : une revue systématique
Pourquoi partager des connaissances médicales sans partager les données compte
La médecine moderne s’appuie de plus en plus sur l’intelligence artificielle pour détecter les maladies plus tôt, choisir le bon traitement et prédire qui présente le risque le plus élevé. Pourtant, les meilleurs outils d’IA nécessitent d’énormes volumes de données patient, et les hôpitaux ne peuvent pas simplement mutualiser leurs dossiers en raison de lois strictes sur la confidentialité et de contraintes éthiques. Cet article passe en revue plus d’une décennie de recherches sur l’apprentissage « décentralisé » — des méthodes permettant aux hôpitaux d’entraîner des IA ensemble sans jamais partager les données brutes des patients — et pose une question pratique : ces méthodes préservant la vie privée sont‑elles réellement compétitives par rapport aux approches traditionnelles ?
Nouvelles façons d’apprendre des patients tout en protégeant la vie privée
Dans l’apprentissage centralisé classique, les hôpitaux copient toutes leurs données dans une grande base commune et entraînent un modèle unique. Dans l’apprentissage local, chaque institution construit son propre modèle sur ses données, sans collaboration. L’apprentissage décentralisé offre une voie intermédiaire. Par exemple, en apprentissage fédéré, chaque hôpital entraîne un modèle localement, puis seuls les paramètres du modèle (les « réglages » d’un réseau neuronal) sont envoyés pour être agrégés en un modèle partagé ; les dossiers patients ne quittent jamais le site. Le swarm learning supprime le coordinateur central et permet aux institutions d’échanger directement des mises à jour de modèles. D’autres approches décentralisées combinent des prédictions issues de plusieurs modèles locaux ou répartissent le modèle entre plusieurs sites. Ces méthodes ont été testées sur des problèmes allant de la détection du cancer et du diagnostic du COVID‑19 aux maladies cardiaques, diabète, troubles cérébraux et affections psychiatriques.
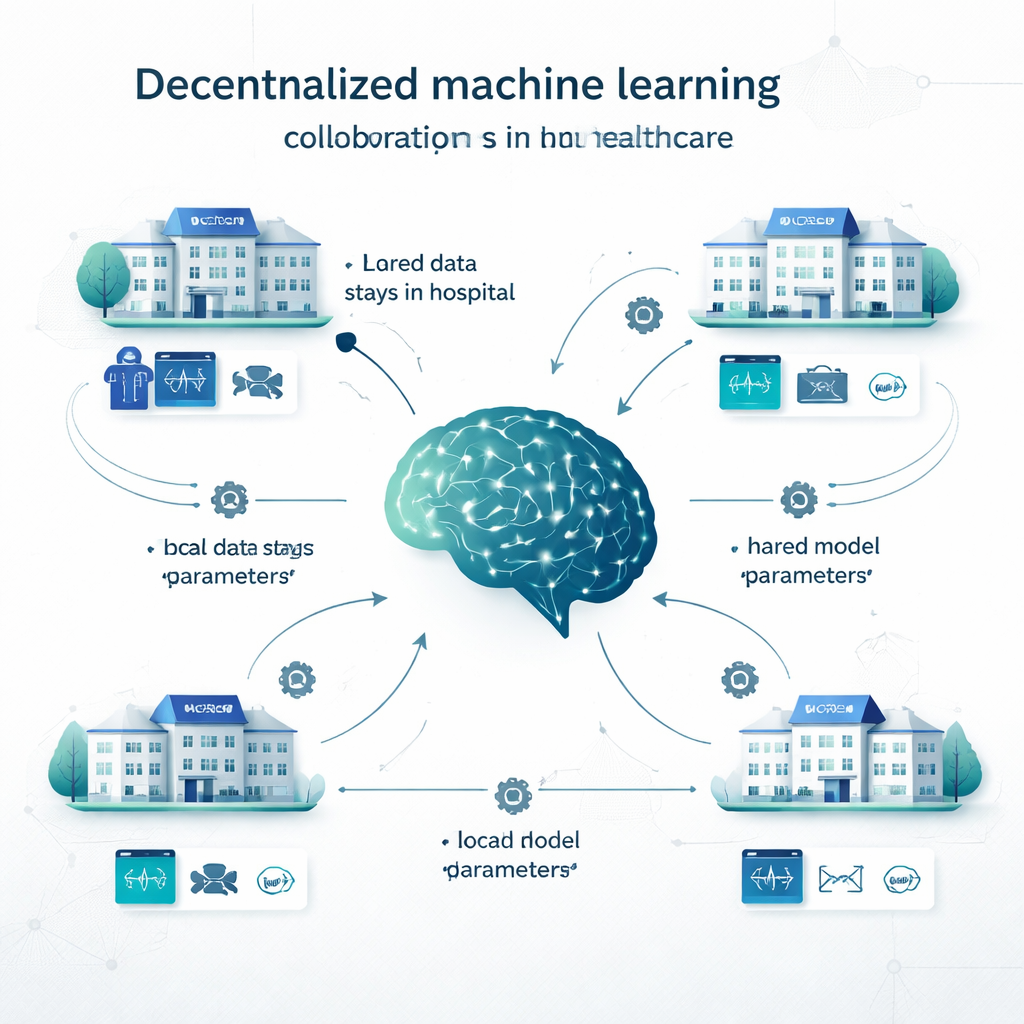
Ce que les chercheurs ont examiné
Les auteurs ont recherché systématiquement dans 11 grandes bases et ont dépouillé 165 010 études publiées entre 2012 et mars 2024. Après élimination des doublons et des études n’impliquant pas de décisions cliniques réelles, 160 articles ont été retenus. Ensemble, ces articles rapportaient 710 modèles décentralisés et 8 149 comparaisons de performance directe contre des modèles centralisés ou locaux. La plupart des études portaient sur le diagnostic, mais on en trouve aussi beaucoup sur la segmentation d’images (par exemple, le contour des tumeurs), la prédiction d’issues futures comme la survie ou les complications, et des tâches combinées. Les types de données couvraient presque toutes les sources majeures utilisées en médecine : dossiers de santé électroniques, scanners et IRM, radiographies, lames de pathologie numérique, signaux cardiaques et cérébraux, et même données génétiques.
Comment les modèles préservant la vie privée se comparent à l’IA centralisée
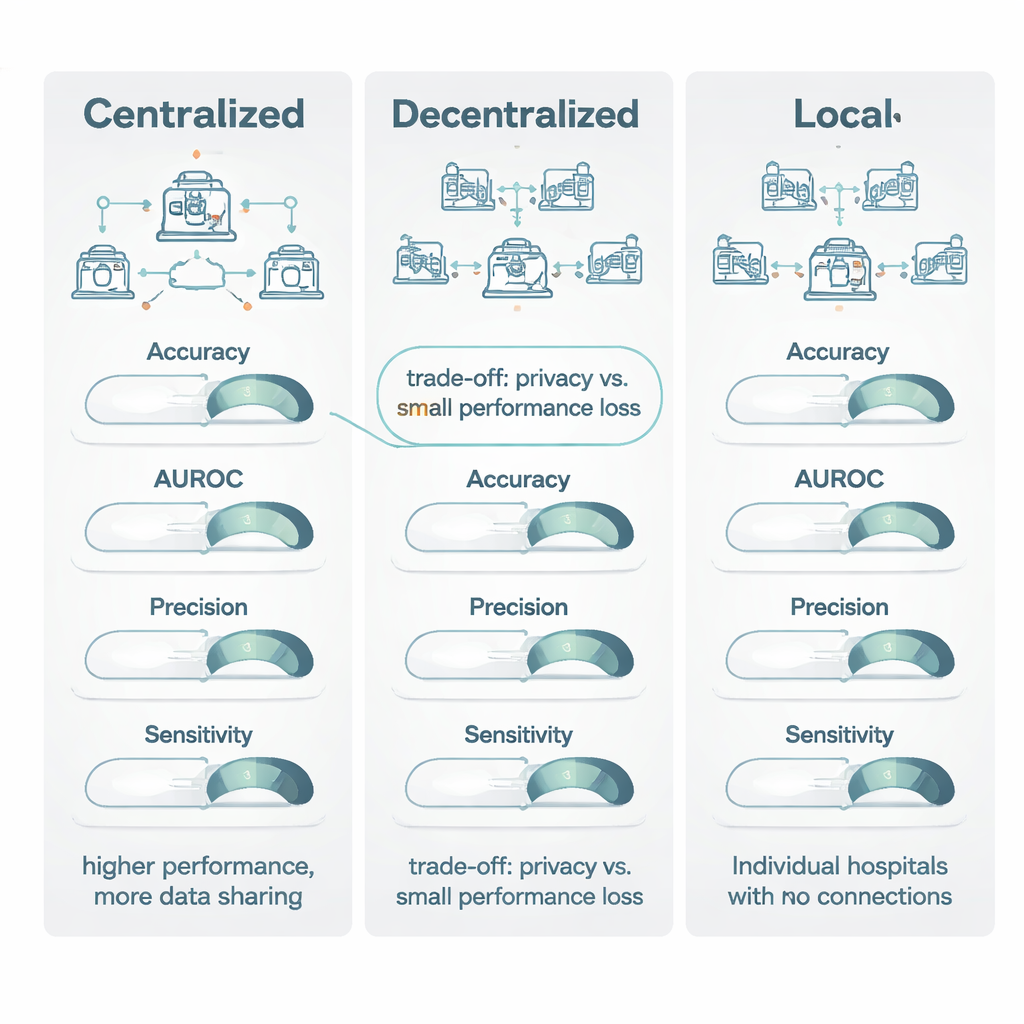
Lorsque des modèles décentralisés ont été comparés à des modèles centralisés entraînés sur des données regroupées, l’apprentissage centralisé était généralement légèrement en tête. Il brillait particulièrement sur des mesures « à seuil » comme la précision et un score d’imagerie courant appelé coefficient de Dice, l’emportant environ trois fois sur quatre et avec un avantage suffisant pour être considéré comme modéré à important. Cependant, pour les mesures de type classement — comme l’aire sous la courbe ROC (AUROC), qui capture la capacité d’un modèle à ordonner les patients du moindre au plus grand risque — les modèles décentralisés et centralisés étaient bien plus proches, avec un léger avantage pour l’entraînement centralisé. Fait important, lorsque les deux modèles atteignaient ce que les auteurs appellent une performance « cliniquement viable » (un score d’au moins 0,80), le gain typique du modèle centralisé était modeste : souvent inférieur à 1–1,5 point de pourcentage. Dans de nombreuses situations, cela se traduisait par « excellent contre acceptable », et non par « utilisable contre inutile ».
Pourquoi l’apprentissage décentralisé surpasse l’approche isolée
Le signal le plus fort de la revue est apparu en comparant les modèles décentralisés aux modèles purement locaux. Sur toutes les métriques majeures — précision, AUROC, score F1, sensibilité, spécificité, et particulièrement la précision positive — les méthodes décentralisées faisaient presque toujours mieux, souvent avec un avantage marqué. Dans des tests directs, l’apprentissage décentralisé a surpassé les modèles locaux dans plus de 80 % des comparaisons pour des mesures clés telles que la précision, la précision positive et l’AUROC. Dans de nombreux cas, les modèles locaux n’atteignaient pas le seuil de 0,80 pour être utiles cliniquement, tandis que le modèle décentralisé correspondant le dépassait confortablement, améliorant la sensibilité jusqu’à 27 points de pourcentage. Les auteurs attribuent cela à l’expérience plus large acquise par les modèles multi‑sites : en « voyant » des schémas provenant de nombreux hôpitaux, ils sont moins trompés par des particularités liées à un établissement (appareils d’imagerie, pratiques de tenue de dossiers) et mieux à même de détecter des caractéristiques de la maladie qui se généralisent réellement.
Équilibrer performance, confidentialité et utilisation pratique
La revue conclut que l’apprentissage centralisé reste la référence lorsque les règles de confidentialité et la logistique permettent de combiner les données et lorsque chaque fraction de point de pourcentage en performance compte, comme pour les maladies très rares. Toutefois, l’apprentissage décentralisé offre une alternative puissante et cliniquement acceptable pour les situations où le partage des données est restreint par des lois comme le RGPD et l’AI Act de l’UE, ou par des politiques institutionnelles. Comparées au maintien de modèles entièrement locaux, les approches décentralisées apportent de larges gains en précision et en fiabilité tout en conservant les données à l’intérieur des murs de l’hôpital. Les auteurs préconisent que les travaux futurs rendent compte plus clairement des techniques de protection de la vie privée et des coûts informatiques, afin que les systèmes de santé puissent faire des choix éclairés sur les moments où de légers compromis de performance valent les avantages substantiels en matière de confidentialité et de collaboration.
Citation: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Mots-clés: apprentissage fédéré, IA en santé, confidentialité des données médicales, apprentissage machine décentralisé, modèles de prédiction clinique