Clear Sky Science · fr
L’apprentissage profond multi-omique améliore la prédiction à long terme du cancer du sein basée sur la TEP-TDM au FDG
Pourquoi cela compte pour les patientes et leurs familles
Lorsqu’une personne se voit diagnostiquer un cancer du sein, l’une des premières questions est : « Qu’est-ce que cela signifie pour mon avenir ? » Les systèmes de stadification et les analyses de laboratoire actuels ne fournissent que des estimations approximatives. Cette étude examine si la combinaison des images médicales, des comptes rendus des médecins et des informations cliniques de base avec une intelligence artificielle avancée peut offrir un aperçu plus clair et personnalisé de la survie à long terme et du risque de récidive.
Regarder l’utilisation du carburant du corps
Un outil clé de cette recherche est un examen appelé TEP-TDM au FDG. Il montre non seulement la morphologie des tissus, comme une TDM classique, mais aussi leur consommation de glucose, ce qui révèle l’activité d’une tumeur. Les cliniciens savent déjà que certains chiffres tirés de ces examens — par exemple la « brillance » de la tumeur ou sa taille — sont liés aux résultats. Cependant, ces mesures traditionnelles ne capturent qu’une petite partie de la riche information contenue dans les images et dépendent souvent du travail fastidieux d’experts pour tracer manuellement les tumeurs.
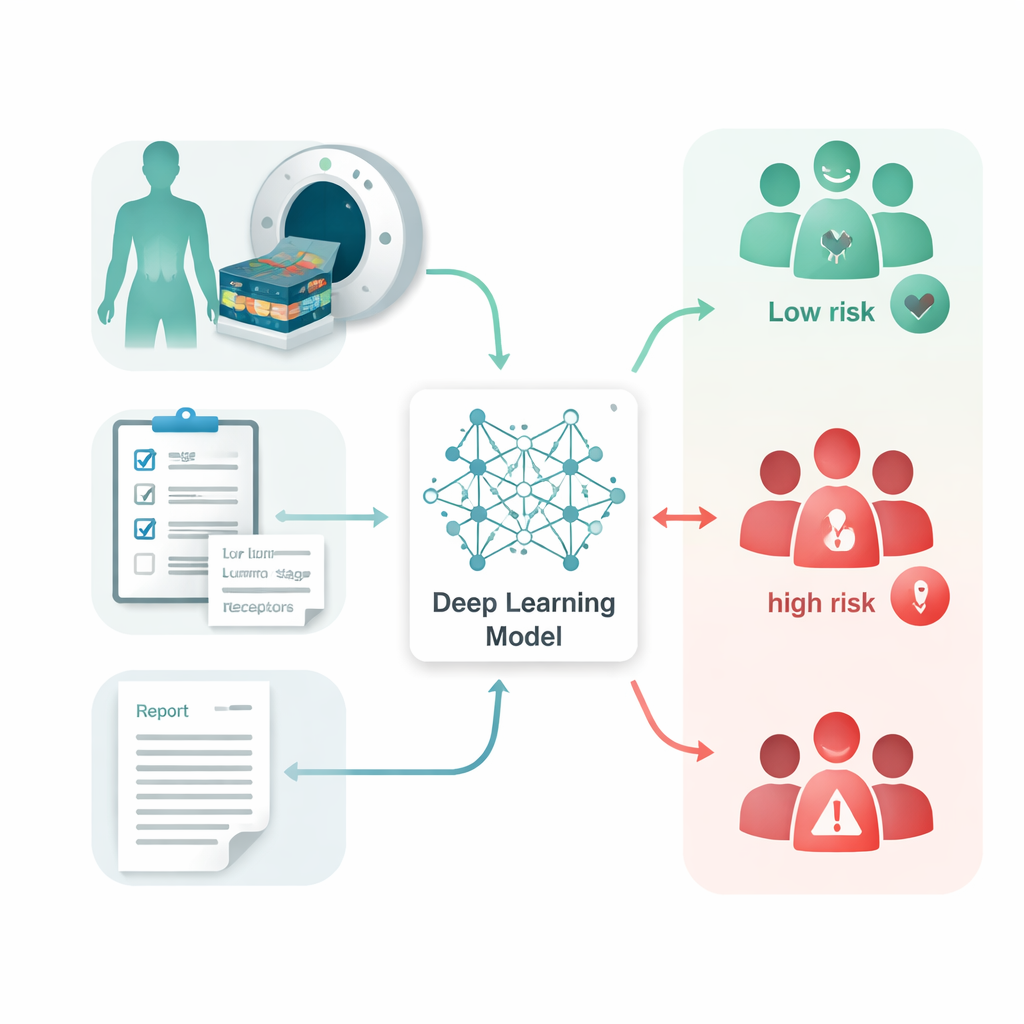
Apprendre aux ordinateurs à lire les images et les rapports
Les chercheurs ont rassemblé des TEP-TDM au FDG, les comptes rendus de radiologie correspondants et des données cliniques de routine de 1 210 femmes atteintes de cancer du sein prises en charge dans un centre oncologique néerlandais sur 15 ans. Aucune n’avait de métastases à distance visibles au moment du diagnostic. Ils ont construit un système appelé Multi-Omics Prognostic Stratification (MOPS), qui utilise l’apprentissage profond — un type d’intelligence artificielle qui apprend des motifs à partir de grands jeux de données — pour combiner trois types d’informations : les images elles‑mêmes, les rapports écrits décrivant les constatations des radiologues, et des facteurs cliniques tels que l’âge, la taille de la tumeur, l’état des ganglions lymphatiques et le statut des récepteurs hormonaux. Un programme automatisé a d’abord délimité les tumeurs du sein et les ganglions affectés afin que le modèle puisse se concentrer sur les régions les plus pertinentes sans contour manuel.
Tirer davantage en combinant de nombreux indices
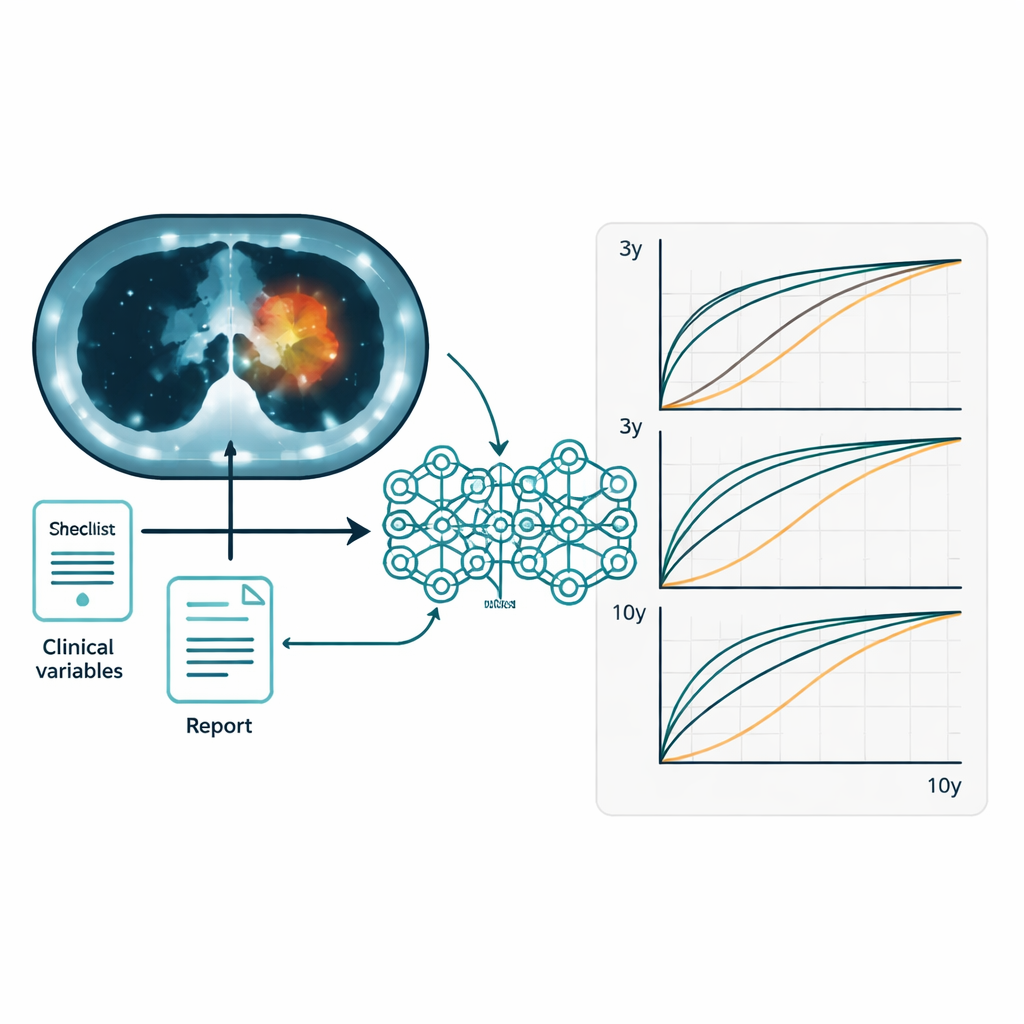
L’équipe a d’abord vérifié à quel point les paramètres usuels basés sur l’imagerie prédisaient la durée de survie et le risque de récidive. Les mesures reflétant la charge tumorale globale, telles que le volume tumoral métabolique et la glycolyse lésionnelle totale, ont mieux performé qu’une simple mesure de brillance maximale, mais leur précision restait modeste. Un modèle d’apprentissage profond analysant l’ensemble du thorax sur la TEP-TDM s’est avéré supérieur à ces paramètres traditionnels. Ensuite, les chercheurs ont testé séparément trois « fils » de données : les images, les rapports écrits et les informations cliniques. Parmi eux, les données cliniques isolées ont fourni la source unique la plus prédictive. Pourtant, lorsque les trois flux ont été fusionnés dans le système MOPS, la performance s’est encore améliorée, offrant des prédictions plus fiables pour la survie globale et la survie sans maladie à 3, 5 et 10 ans.
Ouvrir la boîte noire
Parce que les médecins doivent pouvoir faire confiance et expliquer tout outil influençant les décisions thérapeutiques, l’équipe a conçu MOPS en tenant compte de l’interprétabilité. Des cartes de chaleur superposées aux coupes TDM ont montré que le modèle se concentrait sur les tumeurs mammaires primaires et les ganglions impliqués, plutôt que sur des parties non pertinentes de l’image. Pour les données cliniques, le modèle a mis en avant des facteurs connus et à fort impact tels que la taille de la tumeur (stade T), l’état ganglionnaire et les antécédents familiaux. Dans les rapports textuels, il a eu tendance à souligner des mots décrivant les ganglions, la localisation de la tumeur et l’activité métabolique, faisant écho au raisonnement des radiologues. À travers différents stades tumoraux et sous‑types biologiques, le modèle a pu séparer les patientes en groupes de risque plus élevé et plus faible, bien que la distinction soit naturellement moins marquée pour les tumeurs très petites et de stade précoce qui bénéficient déjà d’excellents taux de survie.
Ce que cela pourrait signifier pour la prise en charge
En termes pratiques, ce travail suggère que la combinaison réfléchie de l’imagerie, des comptes rendus médicaux et des informations cliniques standard peut affiner les estimations du pronostic à long terme d’une patiente atteinte de cancer du sein au‑delà de ce que peut fournir une source isolée. Si cet outil est validé dans d’autres hôpitaux et sur d’autres types de scanners, un système comme MOPS pourrait aider les médecins à identifier les patientes nécessitant véritablement un suivi plus étroit ou un traitement intensifié, tout en épargnant aux patientes à moindre risque des thérapies et une anxiété inutiles. Plutôt que de remplacer les cliniciens, le système agit comme une seconde paire d’yeux, distillant des données complexes en un score de risque individualisé qui facilite des discussions plus claires sur le pronostic et les étapes suivantes.
Citation: Liang, X., Zhang, T., Braga, M. et al. Multi-omics deep learning improves FDG PET-CT-based long-term prognostication of breast cancer. npj Precis. Onc. 10, 74 (2026). https://doi.org/10.1038/s41698-026-01283-7
Mots-clés: pronostic du cancer du sein, imagerie TEP-TDM, apprentissage profond, multi-omique, prédiction de survie