Clear Sky Science · fr
Un modèle d’apprentissage profond interprétable pour prédire les sous‑types moléculaires du cancer de l’endomètre à partir de lames colorées H&E
Pourquoi cela compte pour la santé des femmes
Le cancer de l’endomètre, qui prend naissance dans la muqueuse de l’utérus, est l’un des cancers les plus fréquents chez les femmes et son taux de mortalité augmente dans le monde. Les cliniciens savent aujourd’hui que ce cancer se présente en réalité sous plusieurs « saveurs » moléculaires qui répondent différemment à la chirurgie, à la radiothérapie, à la chimiothérapie et aux nouvelles immunothérapies. Actuellement, l’identification de ces sous‑types moléculaires nécessite généralement des tests génétiques coûteux et chronophages que beaucoup d’hôpitaux ne peuvent pas facilement proposer. Cette étude évalue si un système d’intelligence artificielle (IA) soigneusement conçu peut lire les lames de pathologie de routine — les images de tissu roses et violettes déjà réalisées pour chaque patiente — et déduire avec précision ces sous‑types moléculaires, ce qui pourrait rendre les soins de précision plus largement accessibles.
Un examen plus approfondi de la diversité tumorale
Tous les cancers de l’endomètre ne se comportent pas de la même façon. Certains croissent lentement et restent confinés à l’utérus ; d’autres se diffusent tôt et sont plus difficiles à traiter. Les recommandations modernes classent ces tumeurs en quatre sous‑types moléculaires selon les altérations de l’ADN et les mécanismes de réparation des dommages génétiques. Ces catégories aident à prédire le pronostic et orientent des décisions telles que l’étendue de la chirurgie ou l’éligibilité à l’immunothérapie. Toutefois, les tests génétiques et les colorations spéciales nécessaires sont coûteux, demandent une interprétation experte et sont souvent indisponibles dans les établissements plus petits ou à ressources limitées. Les pathologistes soupçonnent depuis longtemps que nombre de ces différences moléculaires laissent des indices visuels dans l’apparence des cellules et du tissu de soutien au microscope — mais ces indices peuvent être trop subtils et complexes pour que l’œil humain les évalue de manière cohérente.
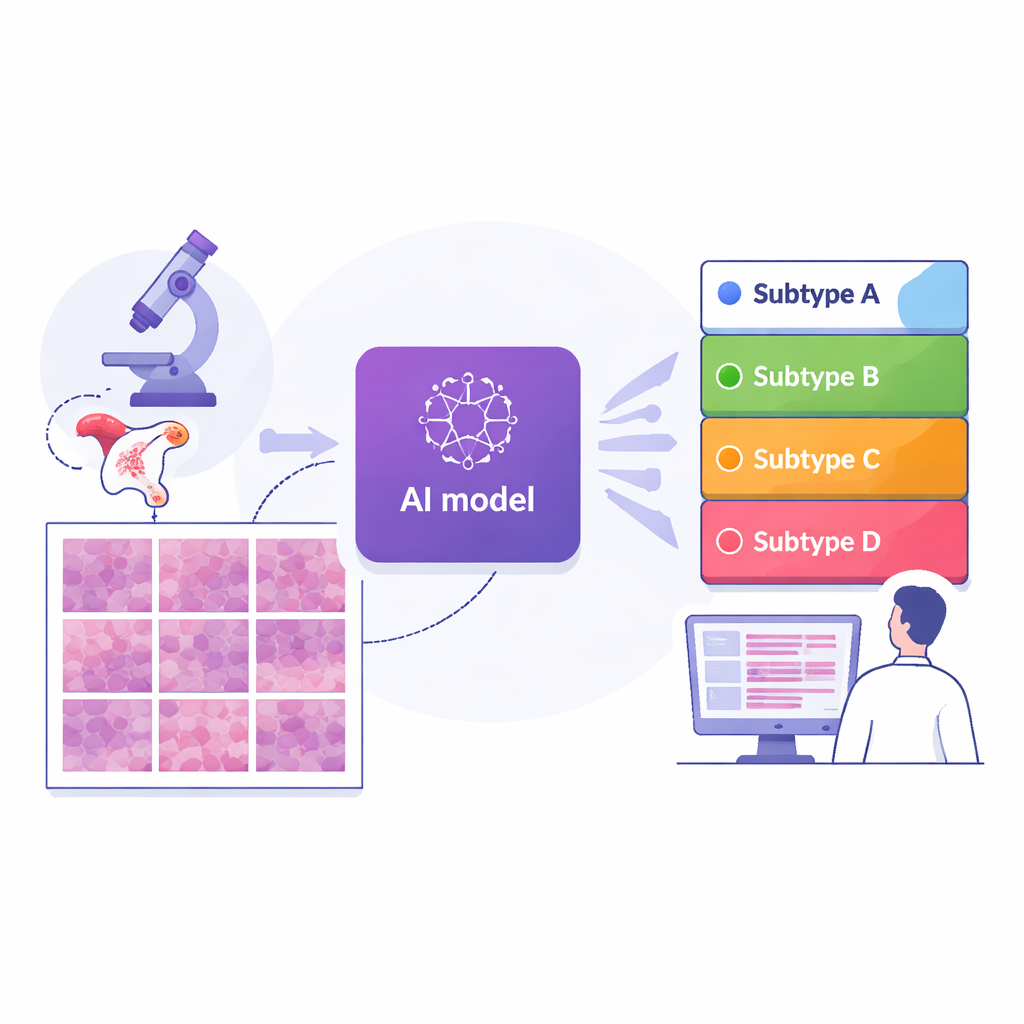
Apprendre aux ordinateurs à lire les lames de pathologie
Les chercheurs ont rassemblé des images numériques de 364 lames issues de 324 femmes traitées dans un grand centre anticancéreux de Shanghai, ainsi que deux groupes de comparaison indépendants : 296 lames provenant d’un jeu de données public international et 36 d’un autre hôpital à Suzhou. Chaque cas avait déjà été classé parmi les quatre sous‑types moléculaires grâce à des tests génétiques avancés. L’équipe a ensuite découpé chaque image de lame entière en milliers de petits carreaux et entraîné un modèle d’apprentissage profond — un type d’IA utilisé pour la reconnaissance d’images — à analyser chaque carreau et estimer la probabilité qu’il appartienne à chaque sous‑type. En moyennant les prédictions des carreaux sur l’ensemble de la lame, le système produisait une prédiction de sous‑type unique pour chaque patiente, reflétant la manière dont les cliniciens considèrent la tumeur dans son ensemble.
Performance du système
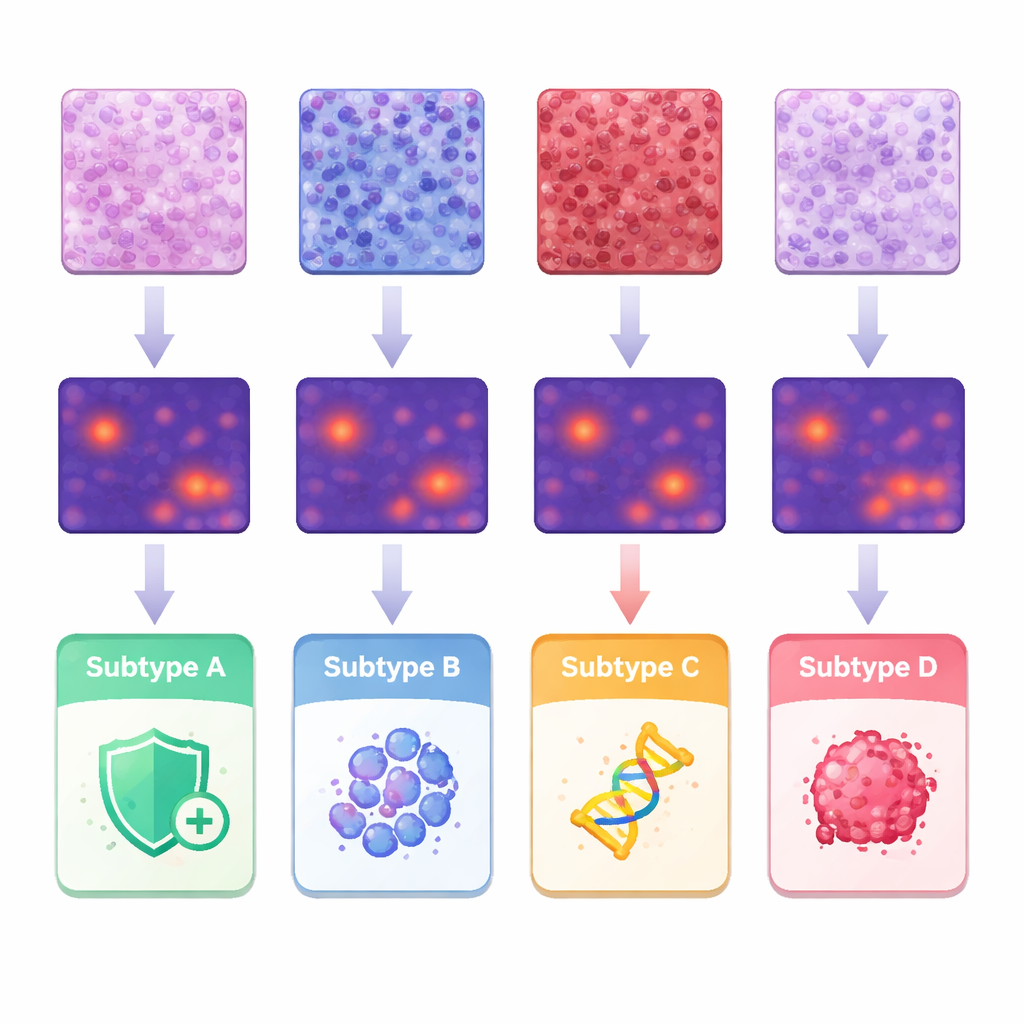
Dans le groupe principal de Shanghai, l’IA a atteint un niveau de précision élevé : son score global pour distinguer les quatre sous‑types (mesuré par une statistique standard allant de 0,5 pour une prédiction aléatoire à 1,0 pour une séparation parfaite) était d’environ 0,87. La performance est restée élevée — autour de 0,84 — lors des tests sur les deux cohortes externes issues d’hôpitaux et de systèmes de numérisation différents, ce qui suggère que l’approche est raisonnablement robuste. Comparé à plusieurs stratégies d’IA de pointe utilisant des schémas d’attention ou d’agrégation plus complexes, ce modèle de bout en bout, construit sur une architecture moderne d’analyse d’images, a généralement mieux performé. Fait important, les auteurs ont conçu le système pour qu’il soit interprétable : ils ont utilisé des outils de visualisation pour mettre en évidence précisément quelles régions de chaque carreau l’IA a utilisées pour prendre ses décisions.
Ce que l’IA « a vu » dans le micro‑environnement tumoral
Pour comprendre quelles caractéristiques guidaient les prédictions, l’équipe a relié les cartes de chaleur de l’IA aux observations pathologiques classiques et à des mesures détaillées des formes et de l’agencement des cellules individuelles. Les tumeurs d’un sous‑type montraient une infiltration dense de cellules immunitaires dans le tissu de soutien, tandis qu’un autre sous‑type avait tendance à présenter des cellules structurelles très serrées. Un troisième groupe affichait des nappes plus solides de cellules tumorales fortement atypiques, et le sous‑type associé à un comportement agressif présentait des structures papillaires en doigts et des noyaux très irréguliers. En segmentant et en analysant environ 245 millions de cellules, les chercheurs ont quantifié les différences de taille cellulaire, de variation et d’espacement, et montré comment certaines combinaisons s’alignaient sur des sous‑types spécifiques. Ces résultats renforcent l’idée que des différences moléculaires laissent une empreinte reconnaissable sur l’architecture tissulaire que les machines peuvent détecter de manière systématique.
Du proof of concept à l’aide clinique
Ce travail n’a pas pour but de remplacer les tests génétiques ; il propose plutôt un outil de tri « H&E d’abord » qui exploite la coloration standard déjà réalisée pour chaque biopsie. En pratique, une carte de probabilités de sous‑type générée par l’IA pourrait aider les pathologistes à décider quels tests de confirmation prescrire en priorité, à réserver le tissu limité pour les assays les plus informatifs et à accélérer les décisions thérapeutiques, en particulier dans les hôpitaux où le profilage moléculaire complet est difficile à obtenir. L’étude souligne aussi les limites actuelles, comme une performance plus faible pour le sous‑type le plus rare et le besoin d’ensembles de données plus grands et diversifiés avant un déploiement clinique. Néanmoins, elle offre une démonstration convaincante que les images microscopiques de routine contiennent suffisamment d’informations cachées pour que l’IA puisse approximer des étiquettes moléculaires complexes, ouvrant la voie à des soins plus équitables et guidés par les données pour les femmes atteintes de cancer de l’endomètre.
Citation: Guo, Q., Cui, H., Zhang, Y. et al. An interpretable deep learning model for predicting endometrial cancer molecular subtypes from H&E-stained slides. npj Precis. Onc. 10, 71 (2026). https://doi.org/10.1038/s41698-026-01280-w
Mots-clés: cancer de l’endomètre, pathologie numérique, apprentissage profond, sous‑types moléculaires, oncologie de précision