Clear Sky Science · fr
Un nouveau cadre hybride d'apprentissage profond pour la prédiction de l'attrition client utilisant RFM et le regroupement d'embeddings
Pourquoi il est important de conserver les acheteurs en ligne
Toute boutique en ligne se confronte à la même question : quels clients s'éloignent discrètement, et lesquels reviendront probablement ? Les repérer tôt permet aux entreprises de dépenser moins pour attirer de nouveaux acheteurs et davantage pour retenir ceux qu'elles ont déjà. Cette étude propose une méthode fondée sur les données pour identifier les clients à risque en transformant des historiques de clics et d'achats désordonnés en signaux clairs indiquant qu'une personne est sur le point d'arrêter d'acheter.
Examiner la fréquence et le montant des achats
Les auteurs partent d'une idée simple mais connue des marketeurs : les clients diffèrent par la récence de leurs achats, la fréquence à laquelle ils achètent et le montant dépensé. Ces trois chiffres, appelés récence, fréquence et valeur monétaire (RFM), esquisseront un portrait basique de chaque acheteur. Ceux qui achètent souvent, dépensent davantage et ont acheté récemment sont généralement fidèles. Ceux qui n'ont rien acheté depuis longtemps, achètent rarement et dépensent peu sont plus enclins à partir. L'étude utilise ces trois signaux, ainsi que quelques statistiques supplémentaires liées au temps, comme fondation pour toutes les analyses ultérieures.
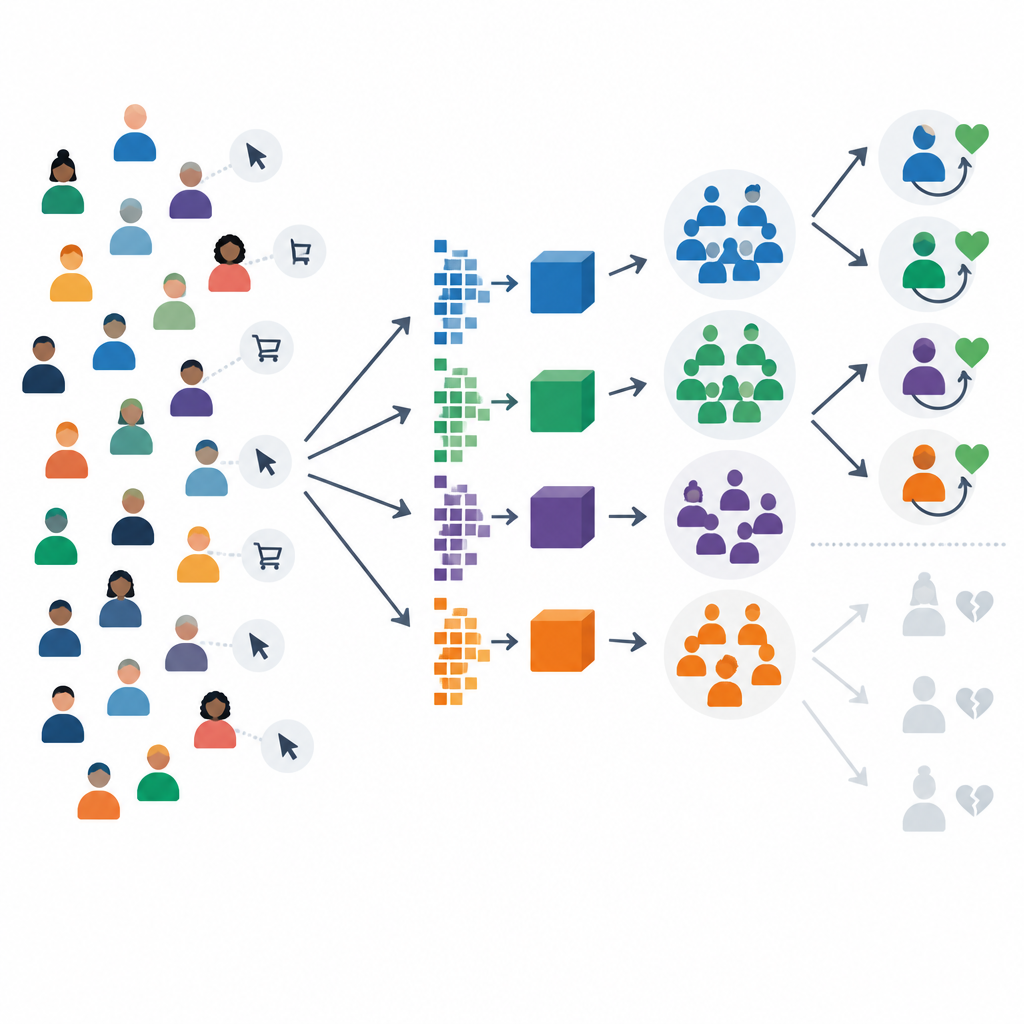
Regrouper les acheteurs selon leurs habitudes
Plutôt que de traiter tous les clients comme un seul groupe, les chercheurs les segmentent d'abord selon leur comportement. Ils utilisent une technique d'apprentissage profond qui compresse le profil d'achat de chaque client en un code compact, puis forme automatiquement des clusters dans cet espace de codes. Cela permet de révéler des motifs difficiles à discerner avec des règles simples, comme des différences subtiles entre acheteurs réguliers stables, acheteurs saisonniers et ceux qui se désengagent. Les clusters obtenus correspondent à des significations commerciales réelles : certains groupes sont presque entièrement composés de clients fidèles, tandis que d'autres contiennent une forte proportion de personnes sur le point d'arrêter d'acheter.

Apprendre au système à suivre les parcours clients dans le temps
Une fois les clients regroupés, l'étude alimente ces segments, ainsi que les schémas de dépenses, dans des réseaux neuronaux aptes à traiter des séquences. Ces réseaux, conçus à l'origine pour lire des phrases ou des sons, lisent ici des flux d'événements d'achat. Ils apprennent comment l'activité d'une personne évolue sur des semaines ou des mois et comment ces évolutions se terminent, soit par la poursuite des achats, soit par le silence. Les chercheurs entraînent et testent leurs modèles sur deux jeux de données réels très différents : l'un constitué d'enregistrements d'achats classiques, l'autre construit à partir de logs détaillés de clics et d'événements.
Comparer les nouvelles méthodes aux outils traditionnels
L'équipe compare ensuite leur approche hybride à des outils standards tels que la régression logistique et les machines à vecteurs de support. Les modèles simples donnent de bons résultats lorsque les données sont déjà propres mais peinent lorsque le comportement est complexe ou bruité. En revanche, le nouveau cadre reshape d'abord les données via un clustering profond puis capture les motifs temporels avec des réseaux séquentiels. Sur les deux jeux de données, cette configuration atteint une précision proche de la perfection tout en restant équilibrée entre la détection des churners et la limitation des fausses alertes. Une étude d'ablation montre que l'ajout de l'étape de clustering améliore nettement les performances par rapport à l'utilisation seule des modèles séquentiels.
Qu'est‑ce que cela signifie pour les entreprises en ligne
Pour un non‑spécialiste, le message principal est que l'exploitation plus riche des données sur le quand et le comment des achats peut transformer des logs routiniers en alertes précoces sur ceux qui risquent de partir. En combinant des résumés simples des dépenses, un regroupement intelligent des clients et des modèles qui suivent le comportement dans le temps, le cadre offre un moyen plus fiable d'identifier les clients à risque. Les entreprises peuvent alors concentrer leurs offres de rétention, leur support ou leur contenu sur les personnes qui en ont le plus besoin, améliorant la fidélité sans se fier au hasard ou à l'intuition seule.
Citation: Ibrahim, S., Tawfik, B.S., Makhlouf, M.A. et al. A novel hybrid deep learning framework for customer churn prediction using RFM and embedding clustering. Sci Rep 16, 16563 (2026). https://doi.org/10.1038/s41598-026-53220-0
Mots-clés: attrition client, e‑commerce, segmentation de la clientèle, apprentissage profond, analyse RFM