Clear Sky Science · fr
IMFLKD : un mécanisme d'incitation pour l'apprentissage fédéré décentralisé basé sur la distillation des connaissances
Pourquoi le partage peut être sûr et équitable
L'intelligence artificielle moderne s'alimente de données, pourtant la plupart de nos données restent sur des téléphones personnels, des serveurs hospitaliers ou des clouds d'entreprise qui ne peuvent pas être simplement copiés et partagés. L'apprentissage fédéré offre une manière pour de nombreux appareils d'entraîner un modèle commun sans exposer leurs données brutes, mais les systèmes actuels souffrent encore de fuites de confidentialité, de points de défaillance centraux et de récompenses injustes pour ceux qui contribuent le plus. Cet article présente un nouveau cadre, IMFLKD, qui combine trois idées puissantes — la blockchain, la distillation des connaissances et le scoring de réputation — pour rendre cet apprentissage collectif plus privé, plus robuste et plus juste sur le long terme.
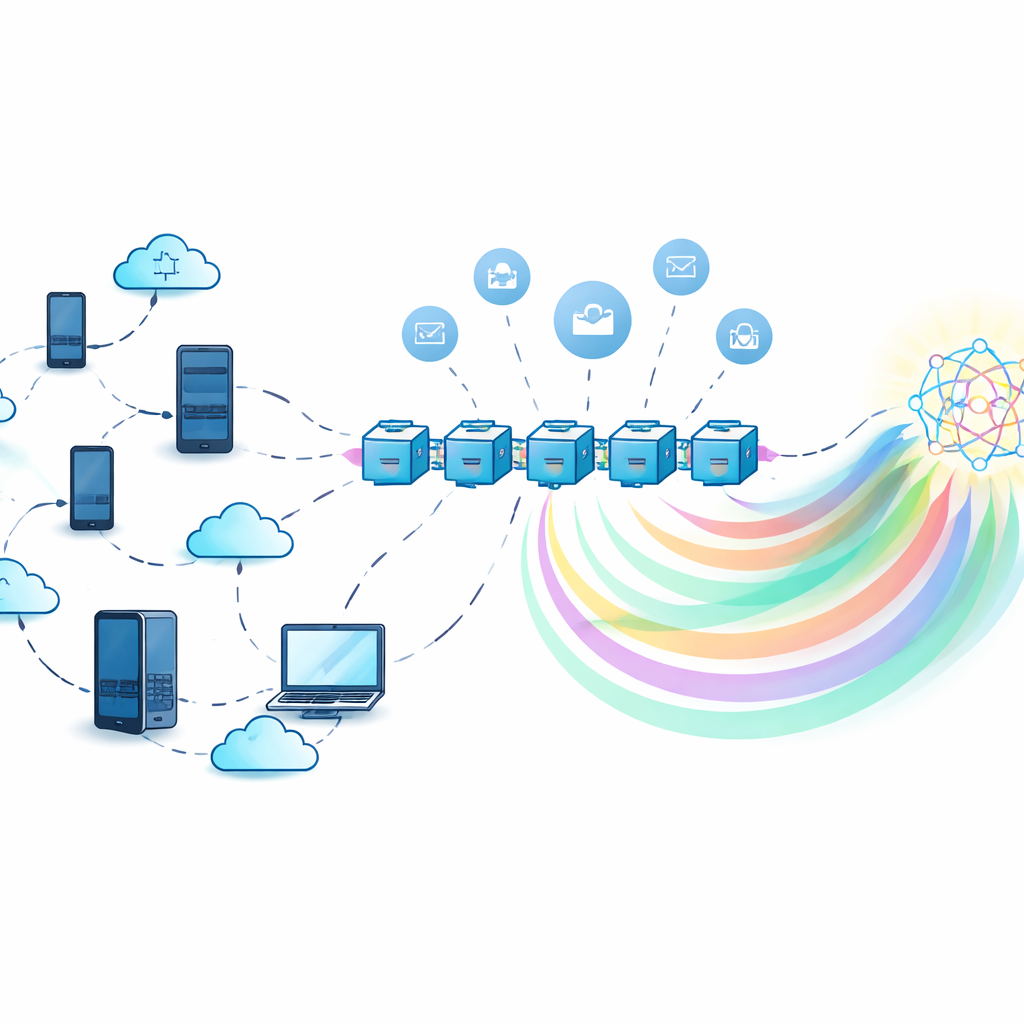
S'entraîner ensemble sans partager de secrets
Dans l'apprentissage fédéré classique, un serveur central collecte des mises à jour de modèle de nombreux participants et les combine. Cela évite la circulation des données brutes, mais le serveur devient lui-même une cible attrayante : s'il tombe en panne, tout le système s'arrête, et s'il n'est pas digne de confiance, il peut abuser ou divulguer des informations contenues dans les mises à jour du modèle. Les auteurs utilisent à la place un registre décentralisé de type blockchain pour coordonner l'entraînement. Chaque participant entraîne un modèle local sur ses propres données puis interagit avec des contrats intelligents sur la blockchain qui enregistrent les contributions, agrégeront l'information et distribuent les récompenses, le tout sans dépendre d'une autorité centrale unique.
Partager des connaissances, pas des modèles lourds
Pour réduire les coûts de communication et protéger davantage la confidentialité, le cadre s'appuie sur la distillation des connaissances. Plutôt que d'envoyer des paramètres de modèle complets, chaque participant n'envoie que des « étiquettes molles » — les probabilités prédictives du modèle sur un ensemble d'entrées partagées — qui sont beaucoup plus légères et révèlent moins sur les données d'une personne. Comme un véritable jeu de données partagé peut ne pas exister, le système utilise un modèle génératif appelé autoencodeur variationnel conditionnel pour créer un jeu de données synthétique « pseudo-public » qui correspond approximativement à la distribution globale des étiquettes sans exposer d'enregistrements originaux. Les participants s'entraînent sur leurs propres données, effectuent des prédictions sur ce jeu de données synthétique, puis affinent leurs modèles à l'aide d'un signal agrégé dérivé des connaissances combinées de tous.
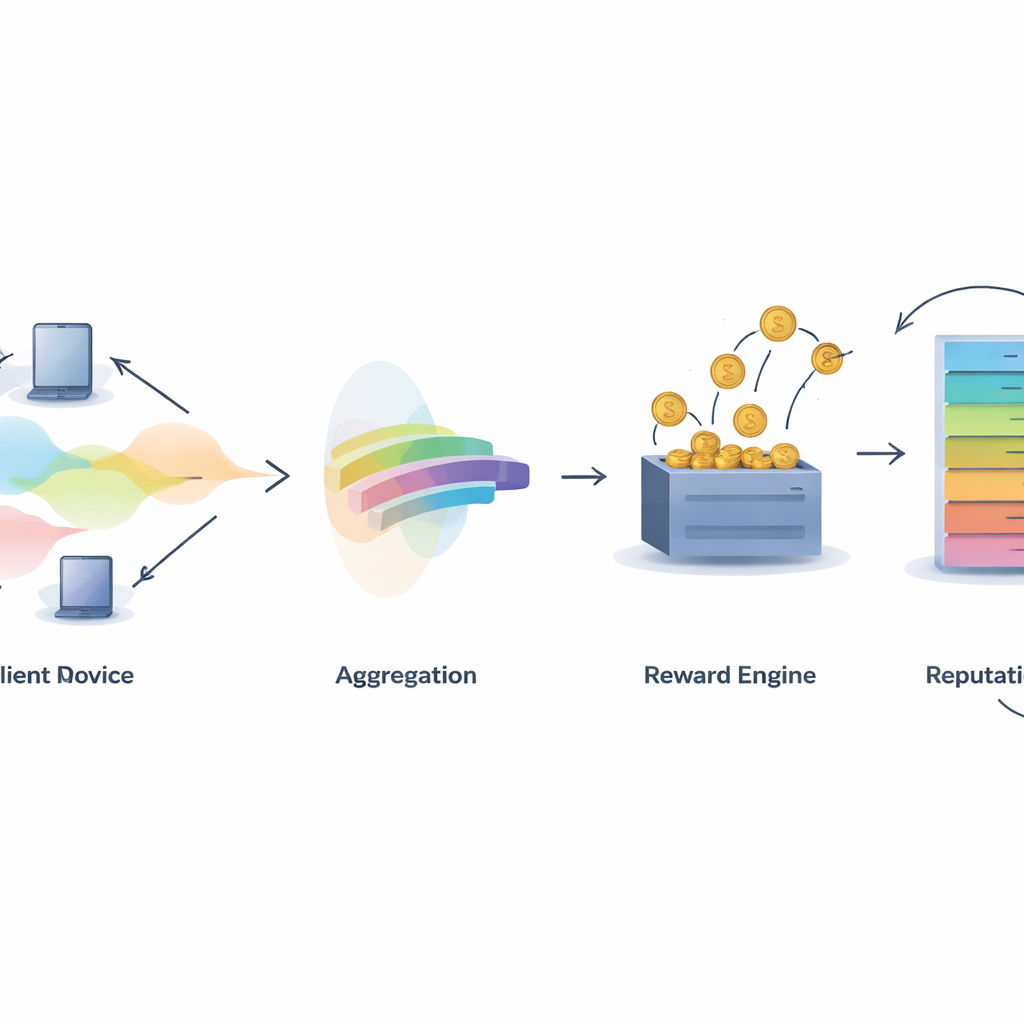
Mesurer qui aide réellement
Un défi central dans tout système collaboratif est de décider qui mérite du crédit. IMFLKD aborde cela avec une méthode d'évaluation des contributions en deux phases basée sur l'agrégation des étiquettes. D'abord, un algorithme bayésien léger examine les prédictions de tous les participants et infère à la fois l'étiquette la plus probable pour chaque échantillon et un score de qualité pour chaque modèle, en mettant à jour ces scores à mesure que de nouvelles tâches arrivent. Cette approche fonctionne en ligne, sans stocker les données passées, et gère les contributeurs bruyants ou malveillants en sous-pondérant les modèles qui sont souvent en désaccord avec le consensus émergent. Les expériences montrent que cette agrégation d'étiquettes améliore l'exactitude d'environ 10 pour cent comparée au vote majoritaire simple, tout en restant suffisamment rapide pour des environnements à grande échelle et à ressources limitées.
Transformer la qualité en récompenses et en réputation
Une fois la qualité de contribution connue, IMFLKD utilise un schéma d'incitation appelé sérum de vérité pondéré par les pairs pour la convertir en récompenses. Les participants sont comparés à un consensus entre pairs pondéré par la qualité : ceux dont les prédictions s'alignent avec des pairs de haute qualité gagnent davantage, tandis que ceux qui dévient ou sont souvent en désaccord sont pénalisés. Cela rend la déclaration honnête la stratégie la plus rentable à long terme, même face à la collusion. En complément, le système construit un score de réputation multidimensionnel pour chaque participant, combinant la qualité des données, le niveau d'activité et la stabilité comportementale, et ajustant les comportements plus anciens par un facteur de décroissance temporelle. La réputation alimente ensuite les tours suivants en influençant le poids des prédictions d'un participant et son éventuelle sélection pour des tâches futures.
Instaurer la confiance dans l'intelligence collective
Dans l'ensemble, le cadre IMFLKD montre qu'il est possible de coordonner l'apprentissage entre de nombreux appareils indépendants de façon efficace, respectueuse de la vie privée et résistante aux profiteurs et aux attaquants. En mélangeant génération de données synthétiques, évaluation rigoureuse des contributions, récompenses issues de la théorie des jeux et suivi dynamique de la réputation sur une blockchain, le système encourage les participants à se comporter honnêtement et de manière cohérente sur de nombreux cycles d'entraînement. Pour un non-spécialiste, la conclusion est que nous pouvons exploiter la puissance collective des données distribuées — comme des dossiers médicaux, des relevés de capteurs ou des appareils personnels — sans tout confier à une seule entreprise ou à un seul serveur, tout en veillant à ce que ceux qui fournissent les informations les plus utiles soient ceux qui en bénéficient le plus.
Citation: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Mots-clés: apprentissage fédéré, blockchain, distillation des connaissances, mécanismes d'incitation, systèmes de réputation