Clear Sky Science · fr
Une formation hybride évolutionnaire‑gradient améliore la prévision à long terme des séries temporelles
Pourquoi de meilleures prévisions à long terme comptent
De la demande électrique et du trafic autoroutier aux taux de change et au climat local, nos vies sont façonnées par des systèmes qui évoluent dans le temps. Prévoir avec précision ces variations plusieurs jours ou semaines à l’avance peut économiser de l’énergie, réduire les embouteillages et rendre les entreprises plus résilientes. Mais plus on regarde loin dans le futur, plus il devient difficile pour les outils d’intelligence artificielle actuels de faire face aux conditions changeantes, aux mesures bruitées et aux budgets de calcul limités. Cet article présente une nouvelle façon d’entraîner des modèles de prévision afin qu’ils restent précis et stables même lorsque le monde ne reste pas immobile.
Apprendre à partir de nombreux modèles plutôt qu’un seul
La plupart des prévisionnistes modernes de séries temporelles s’appuient sur un seul réseau neuronal profond entraîné par descente de gradient, la méthode standard qui ajuste progressivement les paramètres du modèle pour réduire l’erreur. Cela fonctionne bien lorsque les données se comportent de manière cohérente, mais peut échouer lorsque les conditions dérivent, que les mesures sont bruitées ou que le temps d’entraînement est limité. Plutôt que d’inventer une nouvelle architecture, les auteurs proposent Evolutionary‑Guided Module Fusion with Gradient Refinement (EGMF‑GR), un cadre d’entraînement qui peut s’adapter aux architectures existantes. L’idée clé est de maintenir une petite « population » de modèles qui partagent tous la même structure mais démarrent à partir d’initialisations aléatoires différentes. Pendant l’entraînement, ces modèles explorent différentes façons d’ajuster les données, et celui qui obtient les meilleures performances à un moment donné est utilisé pour guider les améliorations des autres.
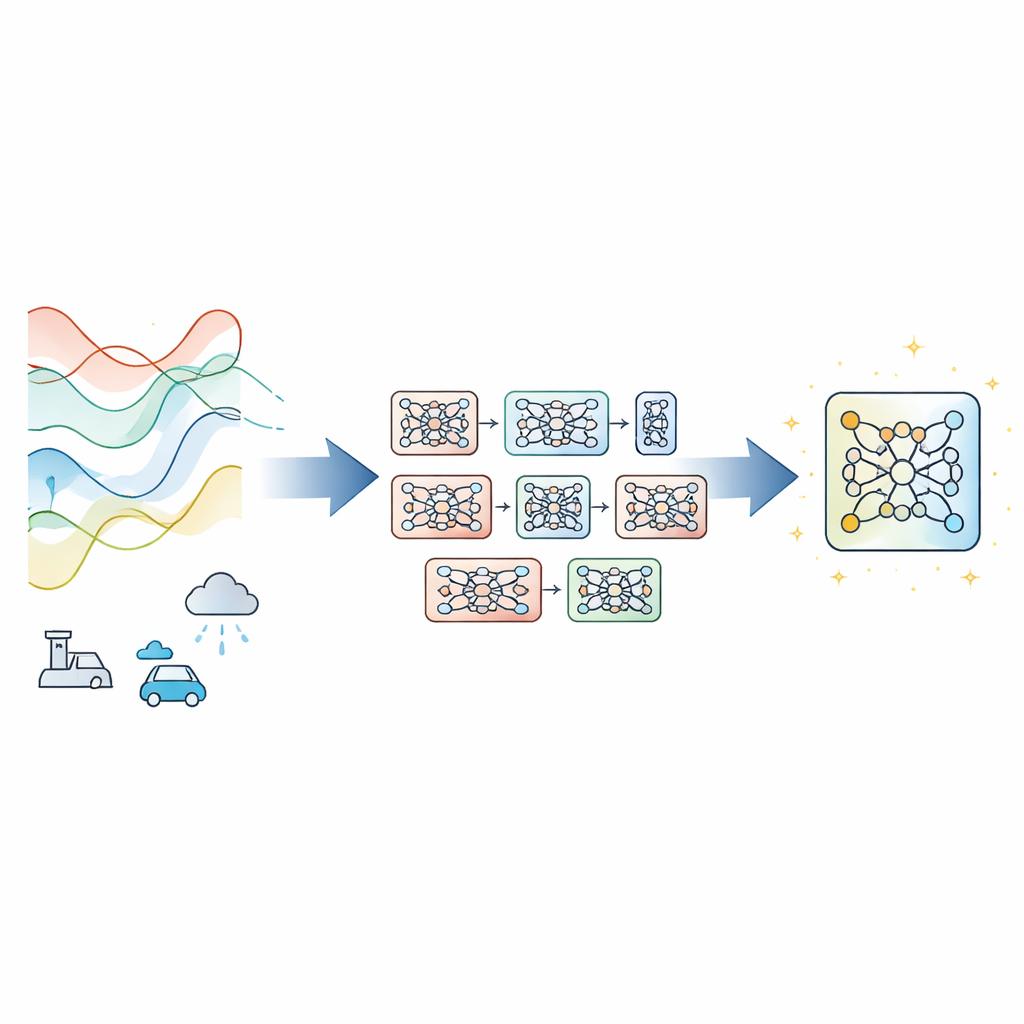
Emprunter les bonnes parties tout en préservant une diversité utile
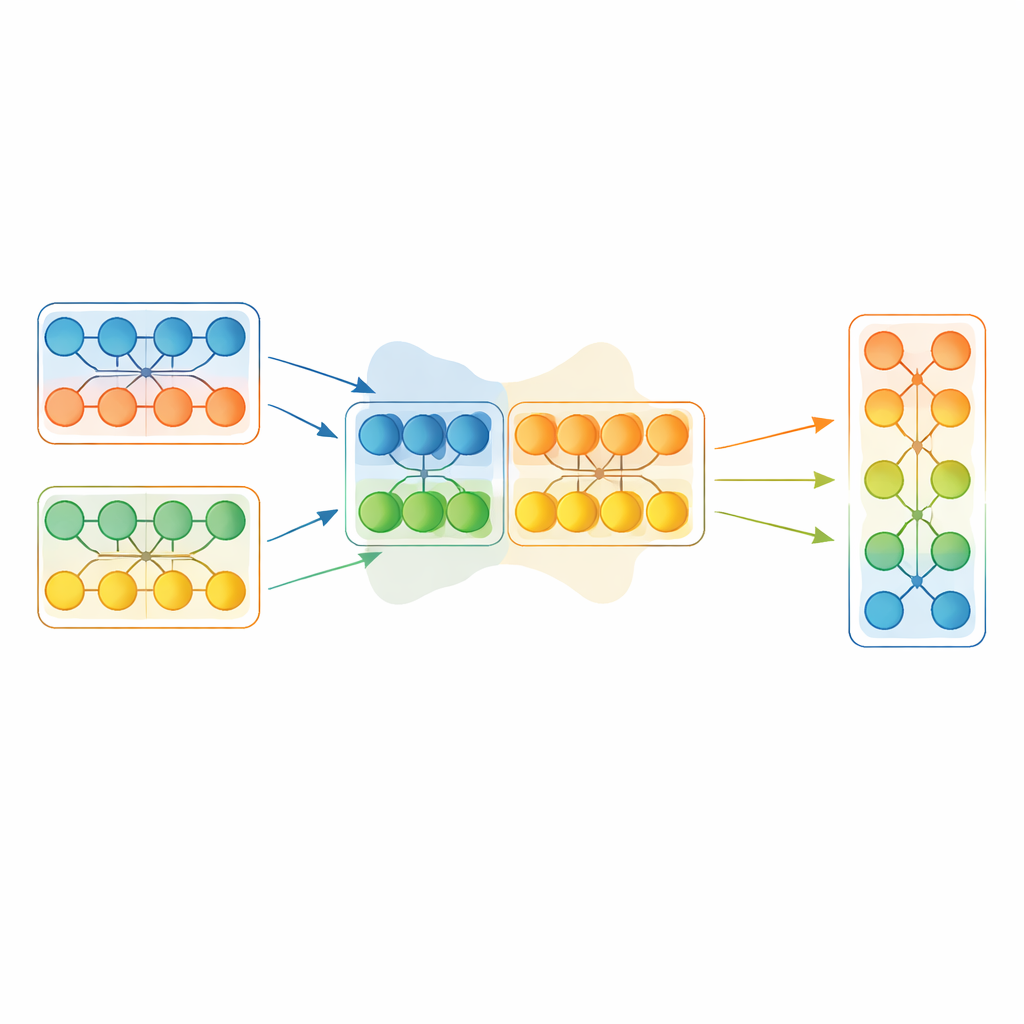
Plutôt que de copier intégralement un modèle gagnant, EGMF‑GR opère au niveau des modules — blocs répétés à l’intérieur d’un réseau, par exemple des empilements de couches. Pour chaque modèle de la population, le cadre aligne les modules correspondants avec ceux du modèle actuellement meilleur et compare leurs signaux internes lorsqu’ils traitent la même batch d’entrée. Il utilise plusieurs mesures simples de différence, capturant à la fois la forme des motifs d’activité et leur amplitude. Ces divergences au niveau des modules sont ensuite résumées, et seuls les modules dont le comportement ressemble à des valeurs aberrantes par rapport à leurs pairs sont envisagés pour une mise à jour. Lorsque cela se produit, le module en retard est rapproché du module correspondant du meilleur modèle via un mélange pondéré de leurs paramètres, auquel s’ajoute une petite perturbation aléatoire pour préserver la diversité.
Laisser les gradients régler les détails après les grands mouvements
Le mélange de parties provenant de réseaux différents peut introduire des changements brusques. Pour éviter de déstabiliser l’entraînement, chaque modèle fusionné subit ensuite une courte phase conventionnelle de descente de gradient sur les données d’entraînement. Cette étape de raffinement permet au réseau de se réadapter en douceur à sa nouvelle configuration interne tout en conservant les bénéfices des connaissances empruntées. La procédure globale alterne ainsi : sélectionner le modèle courant le meilleur sur une tranche de données tenue à l’écart, fusionner sélectivement ses modules dans le reste de la population, puis affiner brièvement chacun avec des gradients. De manière cruciale, la méthode synchronise aussi les états internes de gestion, tels que les moyennes mobiles utilisées par certaines couches, souvent ignorées dans des schémas de fusion plus simples mais pouvant fortement impacter la stabilité.
Démontrer les gains sur de nombreux signaux réels
Pour tester le cadre, les auteurs ont appliqué EGMF‑GR à plusieurs architectures de prévision populaires, y compris des modèles de type Transformer et une conception récente à base de convolutions, sans modifier leurs structures de base. Ils ont évalué les performances sur huit bancs d’essai publics couvrant la consommation d’énergie, le flux de trafic, les taux de change et la météo, et sur des horizons de prévision allant de quelques heures à plusieurs jours. Avec un budget strictement égal d’opérations coûteuses de rétropropagation, l’entraînement hybride a constamment réduit les erreurs de prédiction et assoupli le comportement d’entraînement pour la plupart des combinaisons modèle‑jeu de données, en particulier dans des contextes à haute dimensionnalité ou bruités. L’équipe a également comparé son approche à des astuces courantes sur un seul modèle, comme les moyennes mobiles exponentielles et l’averaging stochastique des poids, et a constaté que la fusion modulaire basée sur une population apportait des bénéfices supplémentaires au-delà d’un simple lissage des poids.
Rester fiable quand les conditions se dégradent
Les systèmes réels se comportent rarement comme des exemples pédagogiques propres, les auteurs ont donc aussi testé la robustesse dans des scénarios plus durs : entrées artificiellement corrompues, portions de données manquantes et périodes où la dynamique sous‑jacente change brusquement. EGMF‑GR a clairement aidé lorsque les entrées étaient bruitées ou partiellement manquantes, suggérant que l’emprunt d’un comportement modulaire stable au meilleur modèle courant peut compenser des anomalies locales. Lors de changements de régime soudains, l’avantage était plus réduit, laissant entendre qu’un alignement excessif peut parfois ralentir l’adaptation à de nouveaux motifs. Cela pointe vers des améliorations futures où l’intensité de la fusion serait atténuée lorsque l’environnement devient fortement volatile.
Ce que cela signifie pour les outils de prévision quotidiens
En termes simples, l’étude montre que former plusieurs versions coopérantes du même modèle de prévision, et leur permettre de partager uniquement les parties qui se distinguent réellement comme meilleures, peut rendre les prédictions à long terme plus précises et plus stables sans repenser les modèles eux‑mêmes. EGMF‑GR fonctionne comme un sport d’équipe discipliné : les membres adoptent occasionnellement les meilleures stratégies des autres, puis s’entraînent un peu individuellement pour s’ajuster au contexte actuel. Pour les praticiens, cela offre une stratégie d’entraînement plug‑in qui peut renforcer les systèmes de prévision existants en finance, énergie, transport et climat, en particulier lorsque les données sont désordonnées et que les budgets de calcul sont serrés.
Citation: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Mots-clés: prévision des séries temporelles, entraînement évolutionnaire, réseaux neuronaux, fusion de modèles, changement de distribution