Clear Sky Science · fr
Détection des échanges d’échantillons dans les enquêtes antidopage à l’aide de l’apprentissage automatique
Pourquoi il est important d’attraper les tricheurs ingénieux
Le sport de haut niveau repose sur la confiance : quand un athlète gagne, on souhaite croire que le résultat est propre. Les tests modernes de dépistage sont très sensibles, pourtant certains sportifs cherchent à les contourner en remplaçant secrètement des échantillons d’urine. Cette étude montre comment l’apprentissage automatique peut détecter quand un athlète réutilise un ancien échantillon « propre », une ruse extrêmement difficile à repérer avec les contrôles de routine actuels. Ce travail ouvre de nouvelles voies pour protéger l’équité en scannant discrètement d’immenses bases de données de tests à la recherche de preuves cachées de falsification.
Une faille cachée dans les tests actuels
Les laboratoires antidopage analysent généralement l’urine, car de nombreuses substances interdites et leurs métabolites y restent détectables longtemps. Les profils d’hormones stéroïdes naturelles des athlètes sont suivis sur plusieurs années dans le Passeport Biologique de l’Athlète, de sorte qu’une brusque variation de ces valeurs peut déclencher une enquête. Le remplacement par l’urine d’un tiers perturbe ce schéma à long terme et est souvent détectable. Le véritable point aveugle apparaît lorsque l’athlète réutilise en secret sa propre urine antérieure, exempte de substances : dans ce cas, le profil stéroïdien s’insère parfaitement dans son historique, et si l’échantillon est analysé dans un autre laboratoire ou bien longtemps après l’original, il n’existe actuellement aucun moyen automatique de remarquer que deux échantillons sont essentiellement identiques.
Transformer la chimie urinaire en motifs recherchables
Les auteurs ont abordé ce problème en se concentrant sur l’« empreinte » détaillée formée par un ensemble de stéroïdes naturels et leurs ratios dans l’urine. Ils ont rassemblé 67 651 profils stéroïdiens provenant d’un laboratoire accrédité par l’Agence mondiale antidopage (AMA) collectés entre 2021 et 2023, couvrant des athlètes masculins et féminins. Chaque profil contient des hormones clés comme la testostérone et plusieurs composés apparentés, ainsi que des ratios entre eux. Parce que les cas réels de réutilisation d’échantillons sont rares et confidentiels, l’équipe a combiné ces données du monde réel avec des paires synthétiques soigneusement construites : certaines paires ont été rendues « similaires » en ajoutant un petit bruit de mesure réaliste, d’autres ont été rendues « dissemblables » en associant au hasard des échantillons de différents athlètes. Cela a fourni du matériel d’entraînement équilibré pour qu’un modèle informatique apprenne à quoi ressemble en pratique un « quasi identique ».
Comment fonctionne le détecteur intelligent
Le cœur du système est un type de réseau neuronal artificiel connu sous le nom de réseau convolutionnel, largement utilisé en reconnaissance d’images. Ici, au lieu d’images, l’entrée est une paire de profils stéroïdiens disposés côte à côte. Le réseau balaie les caractéristiques pour saisir des relations locales subtiles, par exemple la façon dont deux hormones et leur ratio évoluent ensemble. Pour rendre les données plus maniables et interprétables, les chercheurs ont aussi utilisé une technique appelée analyse en composantes principales pour projeter tous les profils dans un espace tridimensionnel, où des mesures de distance simples peuvent mettre en évidence des correspondances proches. Lors de l’entraînement, le réseau apprend à fournir une probabilité que deux profils proviennent de la même urine sous-jacente, distinguant la vraie similarité des différences biologiques normales observées entre athlètes et au fil du temps.
Mettre la méthode à l’épreuve
L’équipe a évalué son approche sur plusieurs plans. D’abord, elle l’a testée sur des données mises de côté pour chaque année, en utilisant des profils qui n’avaient pas été vus pendant l’entraînement mais qui avaient été perturbés dans la fourchette d’incertitude de mesure attendue de 15 %. Le réseau convolutionnel a systématiquement atteint une très haute précision, identifiant correctement les paires similaires tout en maintenant un faible taux de fausses alertes, et il a surpassé des méthodes plus traditionnelles comme la régression logistique, les machines à vecteurs de support et les modèles basés sur des arbres. Ensuite, ils ont mis le système au défi avec plus de 800 échantillons de « confirmation » — de vrais spécimens d’urine que des laboratoires avaient réanalysés selon des procédures légèrement différentes. Ceux-ci constituent un substitut réaliste pour des échantillons répétés ou réutilisés. Là encore, le réseau a très bien performé tant pour les hommes que pour les femmes, avec une excellente sensibilité (détecter les vraies correspondances) et spécificité (éviter les correspondances erronées), ce qui suggère qu’il peut faire face au bruit réel de laboratoire et à la variation biologique.
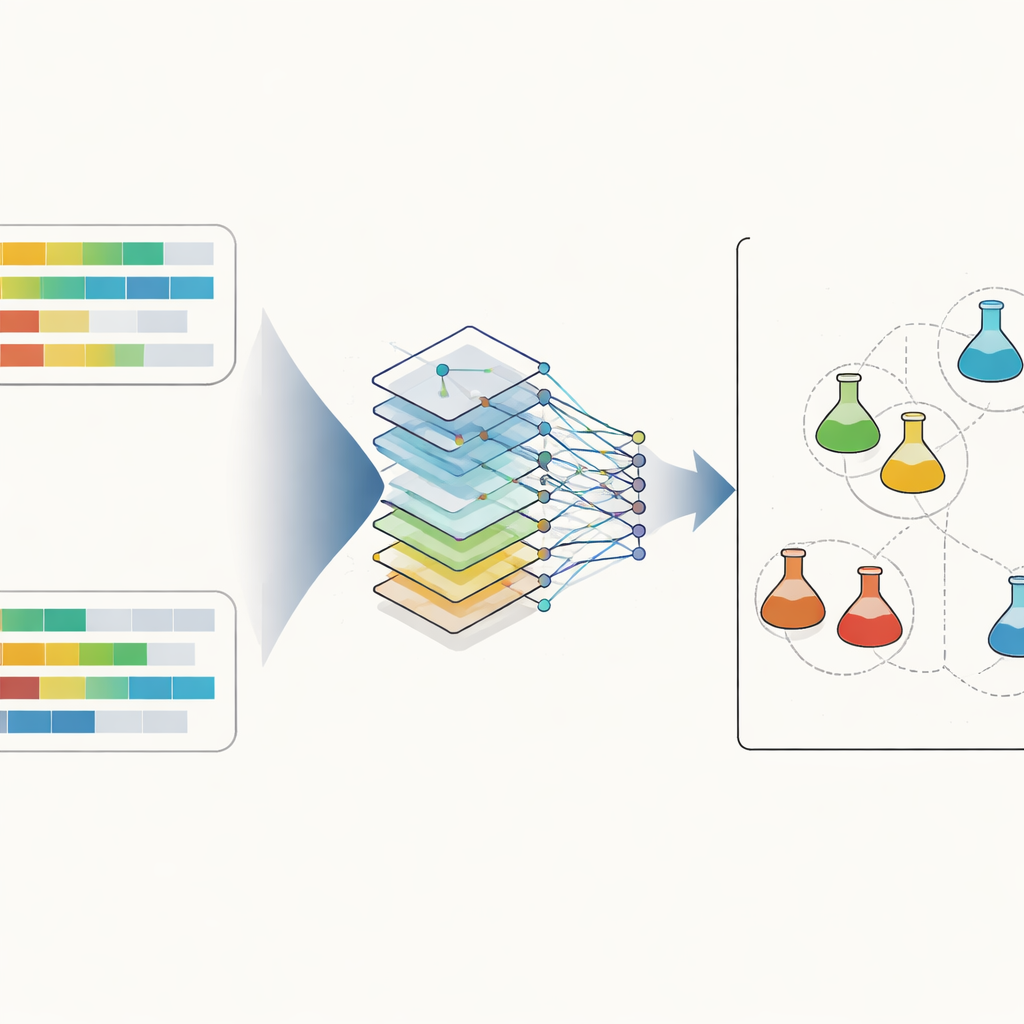
Ce que cela implique pour le sport propre
Pour les non-spécialistes, l’essentiel est qu’il devient désormais possible de scanner automatiquement d’immenses bases de données antidopage pour repérer des signes indiquant qu’un échantillon d’urine prétendument nouveau est en réalité une copie quasi parfaite d’un ancien. Le cadre d’apprentissage automatique proposé ne remplace pas les tests existants pour les substances interdites ; il ajoute une vérification de fond puissante qui peut signaler des échantillons suspectement similaires pour un examen médico-légal plus approfondi. Bien que la méthode repose en partie sur des données simulées et utilise des modèles complexes en « boîte noire » qui ne sont pas totalement transparents, elle offre néanmoins aux autorités sportives un nouvel outil pratique. S’il est intégré aux systèmes actuels du Passeport Biologique de l’Athlète, il pourrait rendre la ruse autrefois indétectable de réutiliser de l’urine propre beaucoup plus risquée, renforçant la confiance que les médailles sont gagnées au mérite plutôt qu’à la manipulation.
Citation: Rahman, M.R., Piper, T., Thevis, M. et al. Detection of sample swapping in anti-doping investigations using machine learning. Sci Rep 16, 9230 (2026). https://doi.org/10.1038/s41598-026-43502-y
Mots-clés: antidopage, profils urinaires de stéroïdes, échange d’échantillons, apprentissage automatique, intégrité du sport