Clear Sky Science · fr
Propriétés et inférence de la distribution Pareto–Lomax avec applications à des données réelles
Pourquoi des courbes de risque flexibles sont importantes
Lorsque les médecins suivent la durée de rémission des patients atteints de cancer, ou que les ingénieurs mesurent la durée de vie des matériaux avant rupture, ils s'appuient sur des courbes statistiques pour résumer le risque au fil du temps. Beaucoup de ces courbes supposent que le risque augmente ou diminue de façon monotone. Mais la réalité est plus complexe : le danger peut culminer tôt, se stabiliser, ou remonter tardivement. Cet article présente un nouvel outil mathématique — la distribution odd Pareto–Lomax (OPLx) — conçu pour reproduire ces schémas complexes de manière plus fidèle, aidant les chercheurs à décrire les événements extrêmes et les temps de défaillance en médecine, en ingénierie, en finance et dans d'autres domaines riches en données.
Une nouvelle façon de capter les événements peu probables
Au cœur de l'étude se trouve un modèle classique appelé distribution de Lomax, utilisé depuis longtemps pour représenter des données à queues lourdes où des issues rares mais très grandes — comme d'énormes pertes d'assurance ou des temps de survie très longs — sont plus fréquentes que ne le prédisent des modèles simples. Les auteurs étendent ce socle en intégrant une famille plus large de courbes connue sous le nom de famille odd Pareto–G. Cette combinaison ajoute deux paramètres supplémentaires de « forme » au modèle Lomax d'origine, donnant la distribution OPLx à quatre paramètres. Avec ces degrés de liberté additionnels, le nouveau modèle peut représenter une grande variété de profils de courbes, incluant un risque décroissant régulier, un risque croissant régulier, des profils unimodaux à pic unique, et même des comportements en J ou en J inversé souvent observés dans les données de durée de vie réelles. 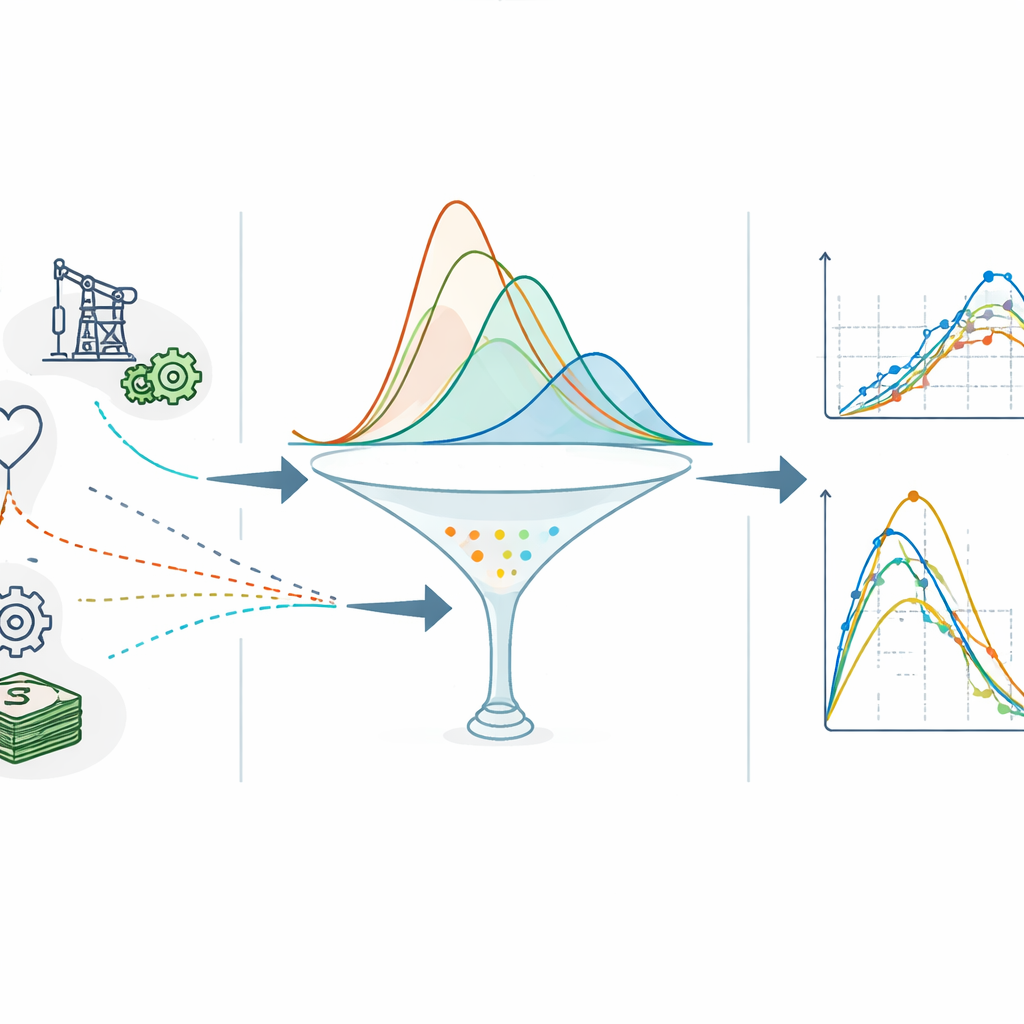
Un aperçu sous le capot mathématique
L'article examine en profondeur le comportement de cette nouvelle distribution. Les auteurs établissent des formules décrivant sa fonction de probabilité, la probabilité qu'une durée de vie soit inférieure à un temps donné, et le taux de risque — le risque instantané de défaillance. Ils montrent que la courbe OPLx peut s'écrire comme une mixture de courbes Lomax plus simples, ce qui leur permet de réutiliser de nombreux résultats mathématiques connus. Ils calculent des résumés numériques tels que l'espérance de vie moyenne, sa variabilité, et des mesures d'asymétrie et d'aplatissement (« peakedness »). Ces calculs révèlent que la distribution OPLx est particulièrement adaptée pour représenter des données fortement asymétriques à droite, où la majorité des observations sont faibles mais quelques valeurs très élevées allongent la queue.
Comparer les méthodes d'estimation de la courbe
Pour passer de la théorie à la pratique, il faut estimer les quatre paramètres de l'OPLx à partir de données réelles. Les auteurs comparent systématiquement huit stratégies d'estimation différentes, allant de la méthode du maximum de vraisemblance largement utilisée à des approches basées sur les moindres carrés, les espacements entre points de données, et des mesures d'ajustement qui donnent un poids supplémentaire à la région centrale ou aux queues. À l'aide de simulations informatiques étendues avec des milliers de jeux de données synthétiques sous de nombreux réglages de paramètres et tailles d'échantillon, ils suivent l'écart des estimations par rapport aux valeurs véritables et leur variabilité. Les résultats montrent que toutes les méthodes s'améliorent avec l'augmentation de la quantité de données, mais que les méthodes qui mettent l'accent sur la queue droite — en particulier l'approche Anderson–Darling orientée queue droite (RADE) — tendent à être plus précises et stables, surtout lorsque les jeux de données sont de taille modeste. 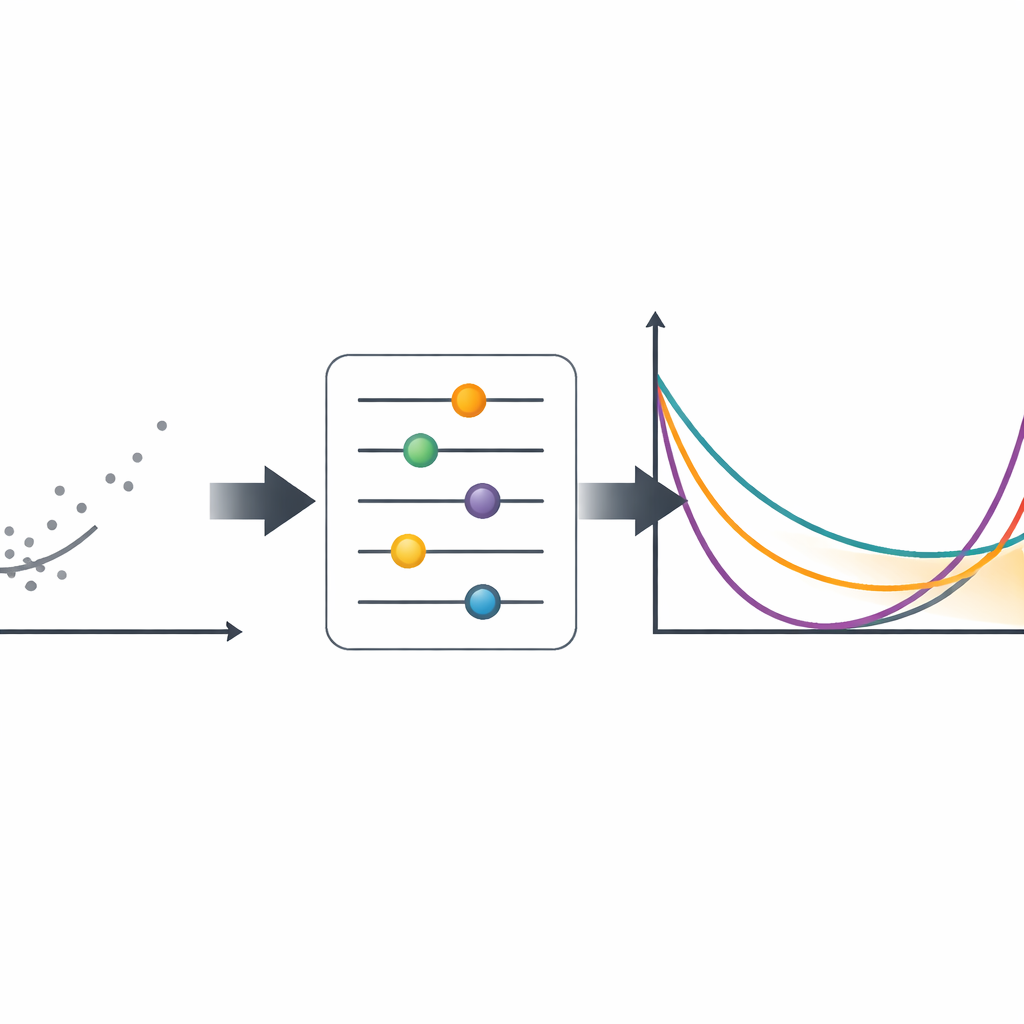
Mettre le modèle à l'épreuve sur des cas réels
Les auteurs testent ensuite la distribution OPLx sur trois jeux de données très différents : les temps de rémission de patients atteints d'un cancer de la vessie, les temps de survie de cobayes infectés par la tuberculose, et la durée de fatigue d'un matériau composite soumis à de fortes contraintes. Pour chaque jeu de données, ils confrontent l'OPLx à une batterie de modèles concurrents, incluant de nombreuses variantes raffinées de la distribution Lomax ainsi que des modèles classiques comme les lois de Weibull et gamma. En utilisant une série d'outils diagnostiques — critères d'information qui pénalisent les modèles trop complexes, mesures de distance qui comparent les courbes ajustées aux données, et tests de Kolmogorov–Smirnov — le modèle OPLx arrive systématiquement en tête. Il ajuste à la fois le corps des données et le comportement extrême de la queue mieux que ses rivaux, conclusion renforcée par des vérifications visuelles telles que les courbes ajustées et les diagrammes quantile–quantile.
Ce que cela change pour les décisions courantes
En termes simples, ce travail offre une lentille plus flexible et plus précise pour apprécier les risques qui se déroulent dans le temps, en particulier lorsque des événements rares mais d'impact comptent. En autorisant la courbe de risque à adopter de nombreuses formes et en se focalisant sur les extrêmes, la distribution odd Pareto–Lomax peut améliorer les études de fiabilité des matériaux, les analyses de survie en médecine, les évaluations des pertes financières, et même des tâches d'apprentissage automatique qui doivent tenir compte des valeurs aberrantes, comme la détection de fraude ou le diagnostic précoce de pannes. Les auteurs montrent que non seulement cette nouvelle courbe décrit mieux les données réelles que de nombreuses options existantes, mais qu'il existe aussi des méthodes pratiques et performantes pour l'estimer. Ainsi, la distribution OPLx se présente comme un ajout puissant à la boîte à outils statistique pour comprendre comment et quand les choses tombent en panne.
Citation: Afify, A.Z., Mahran, H.A., Alqawba, M. et al. Properties and inference of the Pareto Lomax distribution with applications to real data. Sci Rep 16, 9082 (2026). https://doi.org/10.1038/s41598-026-43273-6
Mots-clés: données à fortes queues, modélisation de la durée de vie, risque et fiabilité, analyse de survie, événements extrêmes