Clear Sky Science · fr
Repensez l’ingénierie du contexte avec une architecture basée sur l’attention
Pourquoi des assistants logiciels plus intelligents comptent
Chaque clic que vous effectuez dans une application professionnelle — connexion, téléchargement d’un fichier, lancement d’un rapport — laisse une trace. Si le logiciel pouvait prédire de manière fiable votre prochaine action, il pourrait précharger des données, suggérer des raccourcis et réagir presque instantanément. Cet article explore une nouvelle façon d’apprendre aux ordinateurs à comprendre ces suites d’actions si bien que des assistants numériques peuvent anticiper ce que vous ferez ensuite, ce que vous cherchez à accomplir et quand vous êtes sur le point de vous déconnecter.
Des chaînes simples à des motifs riches
Beaucoup de systèmes existants qui devinent l’étape suivante d’un utilisateur s’appuient sur des chaînes de Markov, un outil mathématique classique qui ne regarde que l’action la plus récente pour prédire la suivante. Rapide et pratique, cette approche à « mémoire d’un pas » montre ses limites dans des environnements de travail réels, où des tâches comme construire une pipeline de machine learning ou préparer un tableau de bord se déroulent sur de nombreuses étapes et impliquent différents outils. Les auteurs soutiennent que de tels modèles simples manquent la structure à long terme, ne gèrent qu’un seul objectif de prédiction à la fois et sont difficiles à comparer entre études parce qu’ils dépendent souvent de journaux privés et de choix opaques de nettoyage des données.
Un nouveau schéma d’apprentissage multitâche
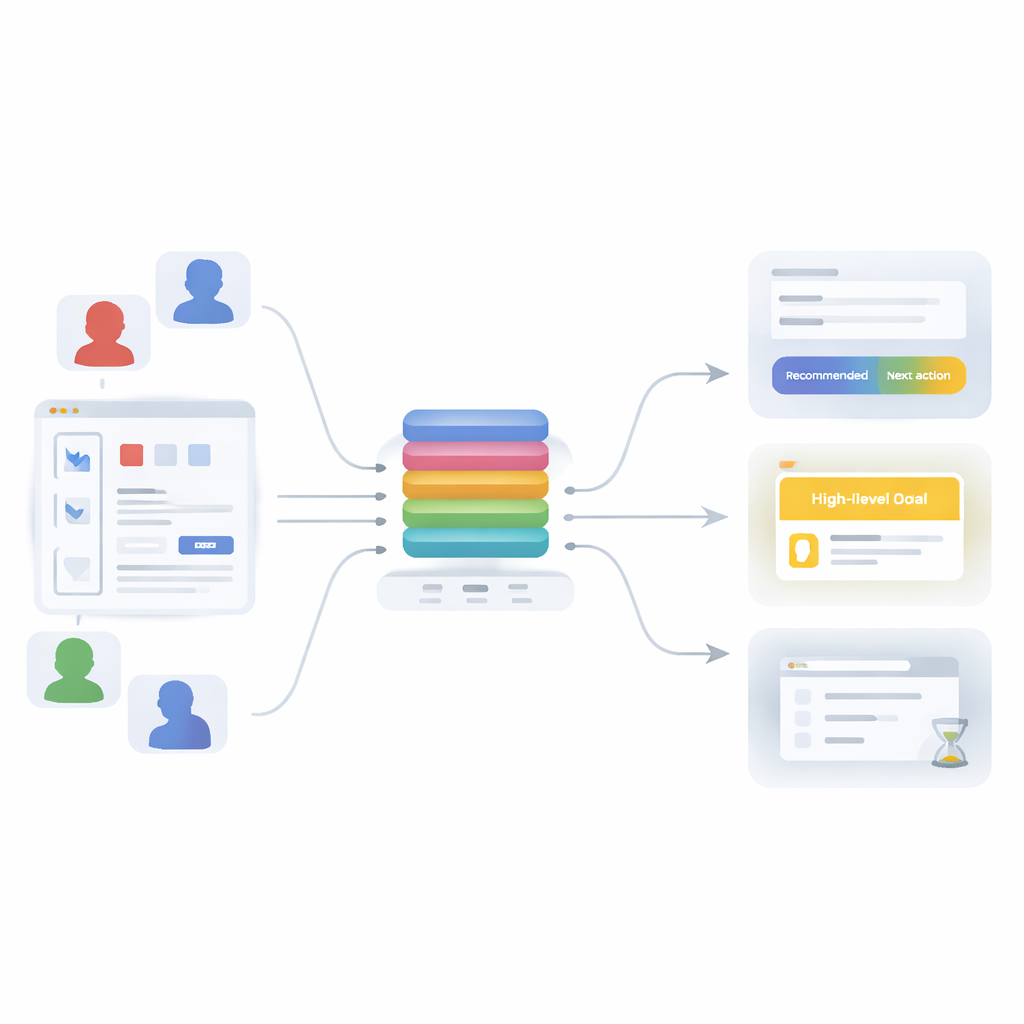
Pour dépasser ces limites, l’article présente un modèle transformer basé sur l’attention — la même famille de techniques qui sous-tend les outils modernes de traitement du langage — réimaginé pour le comportement utilisateur. Plutôt que d’apprendre une seule chose, le modèle est entraîné à résoudre trois tâches connexes simultanément : prédire l’action suivante (quelle API l’utilisateur appellera), inférer l’objectif général de la session (par exemple exécuter un workflow de machine learning, faire de l’analyse de données, gérer des utilisateurs ou créer des visualisations rapides) et décider si l’étape en cours est susceptible d’être la dernière de la session. Les trois tâches partagent un « backbone » commun qui transforme un court historique des actions récentes en une représentation riche et unique de la situation, ensuite fournie à trois petits modules de prédiction.
Construction d’un banc d’essai réaliste in silico
Parce que les journaux d’activité réels des entreprises sont souvent sensibles et difficiles à partager, les auteurs construisent un environnement simulé sophistiqué qui imite l’usage d’une grande plateforme interne par des professionnels des données. Ils définissent 100 API distinctes regroupées en 10 domaines fonctionnels, incluant authentification, saisie de données, traitement, entraînement de modèles, visualisation, exportation et administration. Quatre personas d’utilisateurs — data scientists, analystes métier, développeurs et utilisateurs avancés — suivent des workflows caractéristiques mais imparfaits, avec des probabilités reflétant à la fois un comportement routinier et des détours occasionnels. Le jeu de données résultant contient 2 000 sessions utilisateur et 20 000 appels d’API, avec des objectifs de session tels que « pipeline de machine learning » et « visualisation rapide » produisant des parcours reconnaissables comme se connecter, charger des données, les traiter, créer un graphique et exporter le résultat.
Quelle maîtrise le modèle montre pour anticiper
Entraîné sur cet environnement structuré mais varié, le modèle transformer montre que l’apprentissage par attention peut capturer beaucoup mieux les régularités cachées du comportement utilisateur que les méthodes plus anciennes. Pour la tâche principale — deviner l’appel d’API suivant parmi 100 choix — il obtient la bonne réponse presque 80 % du temps, et place le choix correct dans ses cinq meilleures suggestions plus de 99,9 % du temps, soit une progression de plus de quatre fois par rapport à une chaîne de Markov basique. Parallèlement, il identifie correctement l’objectif global de la session dans environ 82 % des cas et détecte presque parfaitement quand une session est sur le point de se terminer. Les auteurs soulignent aussi que le modèle est relativement compact et efficace, rendant son usage en temps réel faisable pour des assistants live qui doivent répondre sans latence perceptible.
Outils pour que d’autres réutilisent et étendent
Pour que leur approche dépasse l’expérimentation ponctuelle, les auteurs publient un paquet logiciel open-source, appelé context-engineer, ainsi que l’intégralité du jeu de données simulé. Avec ces ressources, d’autres chercheurs et praticiens peuvent reproduire les résultats rapportés, tester des modèles alternatifs sur une référence commune ou connecter leurs propres journaux internes en mappant actions et étiquettes de session dans un format numérique simple. Cette ouverture répond à un obstacle majeur dans le domaine, où de nombreux systèmes passés ne pouvaient pas être comparés équitablement ou réutilisés parce que leurs données et leur code n’étaient pas disponibles.
Ce que cela signifie pour les utilisateurs quotidiens
Pour un non-spécialiste, l’essentiel est que l’article propose une recette pratique pour faire en sorte que les outils numériques donnent l’impression d’être « un pas en avance ». En apprenant conjointement ce que les gens essaient de faire, ce qu’ils vont probablement cliquer ensuite et quand ils terminent, le système proposé basé sur le transformer transforme les historiques d’utilisation en une forme de conscience contextuelle. Dans les applications réelles, cela pourrait signifier des chatbots qui préparent le rapport suivant avant même que vous le demandiez, des plateformes d’analyse qui suggèrent des actions de suivi pertinentes et des tableaux de bord d’entreprise qui réduisent discrètement les temps d’attente. Bien que l’étude actuelle soit fondée sur des données simulées et doive être testée sur des journaux réels, elle pose une base claire et reproductible pour construire des assistants logiciels plus intelligents et plus anticipatifs sur de nombreux types de plateformes numériques.
Citation: Yin, Y. Rethink context engineering using an attention-based architecture. Sci Rep 16, 8851 (2026). https://doi.org/10.1038/s41598-026-43111-9
Mots-clés: prédiction du comportement utilisateur, recommandation séquentielle, transformer basé sur l’attention, assistants numériques proactifs, ingénierie du contexte