Clear Sky Science · fr
Résoudre le problème du déséquilibre des données dans la modélisation par apprentissage automatique des pannes rares et perturbatrices
Pourquoi de meilleures prévisions de tempête comptent pour vous
Lorsqu’une tempête majeure provoque une panne de courant, nous le vivons de façon très personnelle : pas de lumière, pas de chauffage, nourriture avariée et communications coupées. Les services publics tentent de prédire ces pannes à l’avance pour pouvoir dépêcher des équipes de réparation et protéger les personnes. Mais les pires tempêtes sont rares, ce qui signifie qu’il existe étonnamment peu de données à leur sujet. Cet article montre comment un nouveau type d’intelligence artificielle peut « imaginer » des tempêtes rares réalistes, combler les lacunes des archives et rendre les prévisions de pannes plus précises quand cela compte le plus.
Le défi d’apprendre à partir de catastrophes rares
La plupart des pannes de courant sont causées par la météo, en particulier les ouragans, les nor’easters, les tempêtes de neige et de verglas, et les orages violents. Ces événements deviennent plus intenses avec le réchauffement climatique, mettant une pression supplémentaire sur des réseaux électriques vieillissants. Pourtant, les tempêtes les plus destructrices sont, par définition, peu fréquentes. Les outils statistiques traditionnels et les modèles d’apprentissage automatique apprennent en général mieux à partir des nombreuses tempêtes faibles et modérées, et peinent sur la poignée de cas véritablement extrêmes. Ce déséquilibre des données entraîne des sous-estimations des dégâts précisément quand les services publics ont le plus besoin d’orientations fiables.
Apprendre aux ordinateurs à créer de nouvelles tempêtes
Pour surmonter ce déséquilibre, les auteurs construisent un système qui génère des tempêtes synthétiques — c’est-à-dire des événements créés par ordinateur qui ressemblent et se comportent comme de vraies tempêtes sans être des copies d’un événement passé unique. Ils se concentrent sur le Connecticut, représentant chaque tempête comme une grille de 815 cellules avec 19 types d’informations par cellule, notamment le vent, la pluie, la pression, la turbulence, la végétation et l’agencement des lignes électriques. D’abord, ils regroupent 294 tempêtes historiques en 12 clusters selon le nombre et l’emplacement des « points problématiques » — lieux de dégâts que les équipes doivent réparer. Les tempêtes rares et à fort impact se retrouvent dans quatre petits clusters qui nécessitent un renforcement.
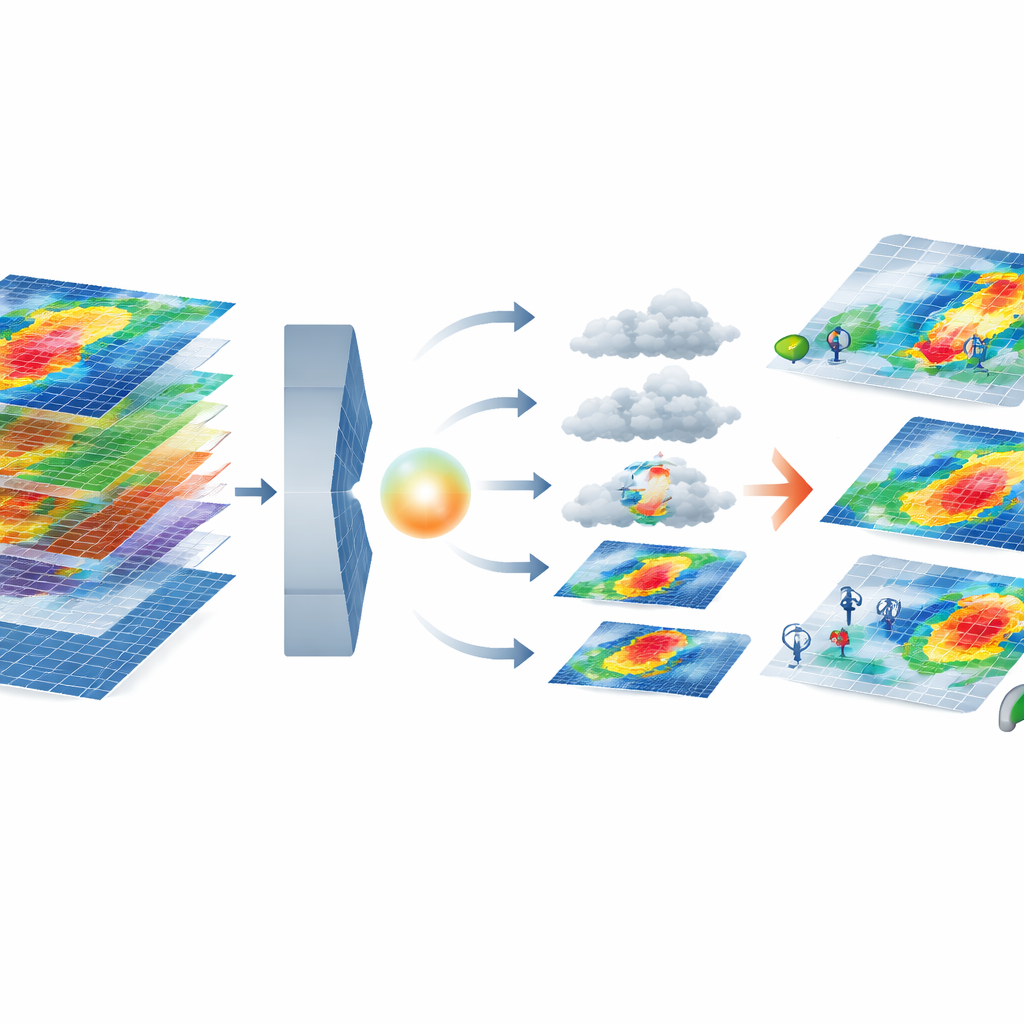
Comment le nouveau modèle d’IA construit des extrêmes réalistes
Le cœur du cadre combine deux outils d’IA modernes. Un autoencodeur variationnel compresse chaque carte de tempête multi-couche en une représentation « latente » de plus faible dimension qui préserve néanmoins des motifs importants, comme des vents plus forts près de la côte. Dans cet espace compressé, un modèle de diffusion apprend à partir d’un bruit aléatoire et à l’affiner progressivement en une tempête réaliste, conditionné par le cluster de sévérité des pannes demandé. Le système filtre ensuite les tempêtes générées à l’aide d’un ensemble de métriques qui comparent leurs statistiques à celles des événements réels — vérifiant non seulement des caractéristiques individuelles comme la vitesse du vent, mais aussi la façon dont les caractéristiques évoluent ensemble, capturée par des motifs de corrélation. Seules les tempêtes synthétiques qui correspondent étroitement au comportement physique et statistique des tempêtes réelles d’un cluster donné sont conservées.
Mettre les tempêtes synthétiques à l’épreuve
Les auteurs posent ensuite la question cruciale : ces tempêtes synthétiques aident-elles réellement à prédire les pannes ? Ils entraînent un modèle de prédiction des pannes existant deux fois : d’abord uniquement sur des tempêtes réelles, puis sur les mêmes données enrichies d’événements synthétiques soigneusement filtrés pour les clusters rares et à fort impact. Ils évaluent les performances avec un test strict leave-one-storm-out, qui imite la prévision d’événements nouveaux et jamais vus. Avec l’enrichissement synthétique, l’erreur structurelle du modèle diminue fortement et l’ajustement global s’améliore. Pour les tempêtes rares et les plus perturbatrices, l’erreur quadratique moyenne centrale baisse d’environ 45 %, et des mesures synthétiques de compétence comme l’efficacité de Nash–Sutcliffe passent d’un niveau inférieur au référentiel à une performance clairement utile. Une comparaison avec une augmentation « aléatoire », qui ajoute des tempêtes synthétiques sans filtrage de qualité, montre des gains beaucoup plus faibles voire négatifs, soulignant l’importance d’un filtrage rigoureux.
Ce que cela signifie pour les tempêtes à venir
En termes simples, cette étude montre que laisser l’IA inventer des tempêtes extrêmes physiquement cohérentes — et être sélectif quant aux tempêtes inventées auxquelles on accorde sa confiance — peut rendre les prévisions de pannes plus fiables pour les événements qui causent le plus de dégâts. En enrichissant des données clairsemées sur des phénomènes rares mais dévastateurs, l’approche aide les services publics à mieux anticiper combien de lieux endommagés ils auront à traiter et où. Bien que démontrée pour un État et un type de danger, la même stratégie pourrait être étendue aux feux de forêt, aux inondations et à d’autres menaces naturelles, offrant une nouvelle façon de renforcer la planification des infrastructures dans un monde de plus en plus soumis à des extrêmes climatiques.
Citation: Azizi, M., Zhang, X., Yasenpoor, T. et al. Addressing the data imbalance issue in machine learning modeling of rare and disruptive outage events. Sci Rep 16, 8876 (2026). https://doi.org/10.1038/s41598-026-41838-z
Mots-clés: données de tempête synthétiques, prévision des pannes d'électricité, modèles de diffusion, météo extrême, déséquilibre des données