Clear Sky Science · fr
Détection précoce de la maladie rénale chronique basée sur un modèle d’apprentissage automatique enrichi par SURD
Pourquoi il est important de détecter tôt les problèmes rénaux
La maladie rénale chronique progresse souvent silencieusement, montrant peu de signes avant-coureurs jusqu’à ce que les reins soient gravement endommagés. Pourtant, de simples tests sanguins et urinaires peuvent révéler des anomalies des années plus tôt, quand un traitement peut ralentir ou même prévenir une détérioration sévère. Cette étude explore une nouvelle manière d’analyser ces résultats de routine à l’aide de modèles informatiques avancés mais interprétables, afin de détecter plus tôt les personnes à haut risque et de permettre aux médecins de comprendre pourquoi.
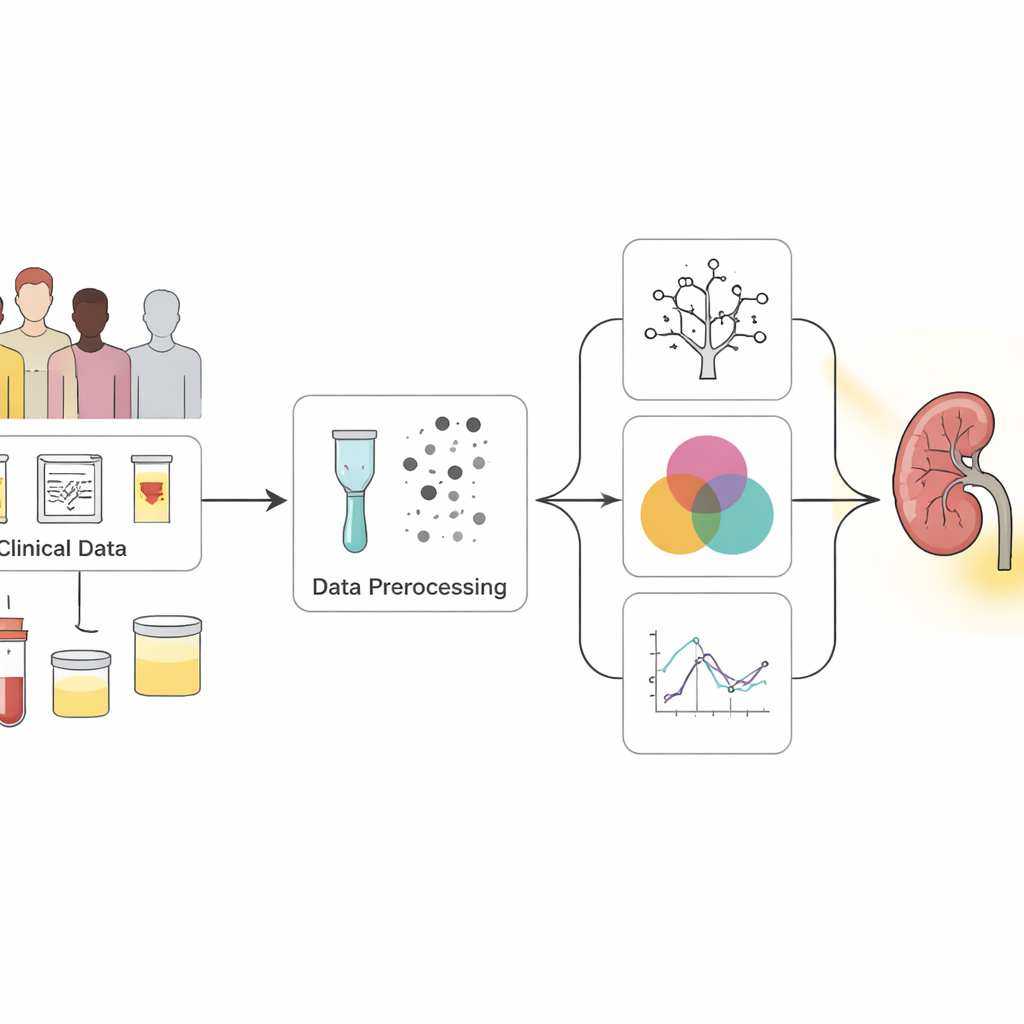
Transformer des données de bilan désordonnées en signaux clairs
Les chercheurs ont commencé avec un jeu de données public largement utilisé comportant 400 personnes, dont la plupart avaient déjà été diagnostiquées avec une maladie rénale chronique. Chaque personne disposait de 25 mesures, allant de la pression artérielle et des hémogrammes aux résultats urinaires et à des antécédents médicaux comme le diabète et l’hypertension. De nombreuses entrées étaient incomplètes, si bien que l’équipe a employé des techniques statistiques soigneuses pour imputer les valeurs manquantes plutôt que d’écarter simplement des patients. Ils ont aussi équilibré les données pour que les cas sains et malades soient mieux représentés, ce qui aide les modèles informatiques à apprendre à reconnaître les deux groupes de façon équitable.
Aller au-delà des simples corrélations
La plupart des outils de prédiction médicale traitent chaque résultat de test séparément : ils examinent à quel point une mesure, comme la glycémie, est liée à la maladie. Mais dans l’organisme, les facteurs de risque agissent rarement seuls. Certains tests apportent une information presque redondante, tandis que d’autres ne deviennent informatifs qu’en combinaison. Pour capturer cela, les auteurs ont utilisé un cadre appelé SURD qui décompose la contribution de chaque caractéristique en trois parties : l’information partagée avec d’autres tests, l’information unique, et l’information n’apparaissant que lorsque les caractéristiques agissent ensemble. Cela leur a permis de grouper les valeurs de laboratoire et les données cliniques en ensembles « uniques », « redondants » et « synergiques » avant de les transmettre aux modèles de prédiction.
Entraîner plusieurs modèles et choisir les plus fiables
Avec ces groupes de caractéristiques basés sur SURD en main, l’équipe a entraîné dix modèles d’apprentissage automatique différents, des arbres de décision simples à des approches plus complexes comme les forêts aléatoires et les réseaux de neurones. Ils ont comparé les performances lorsque les modèles utilisaient toutes les caractéristiques disponibles versus seulement un ensemble combiné de caractéristiques uniques et synergiques. Pour presque tous les types de modèles, cet ensemble réduit guidé par SURD a donné des performances équivalentes ou supérieures à la collection complète des 25 variables, améliorant souvent l’équilibre entre l’identification correcte des patients malades et l’évitement des fausses alertes. En particulier, les modèles basés sur des arbres, comme les forêts aléatoires et les arbres boostés, ont atteint des scores quasi parfaits sur le jeu de données original.
Tester la méthode sur des données hospitalières du monde réel
Une excellente performance sur un petit jeu de référence peut être trompeuse si un modèle échoue face à des patients plus variés. Pour s’en prémunir, les auteurs ont validé leur approche en utilisant une base de données hospitalière beaucoup plus large, contenant plus de 27 000 patients en soins intensifs. Là, le modèle de forêt aléatoire construit sur les caractéristiques sélectionnées par SURD a encore distingué avec une très grande précision les patients avec et sans maladie rénale. Sa performance dépassait clairement celle d’un arbre de décision plus simple, ce qui indique que la méthode peut se généraliser au-delà d’un jeu de données de recherche soigneusement curaté vers des dossiers du monde réel plus bruts.
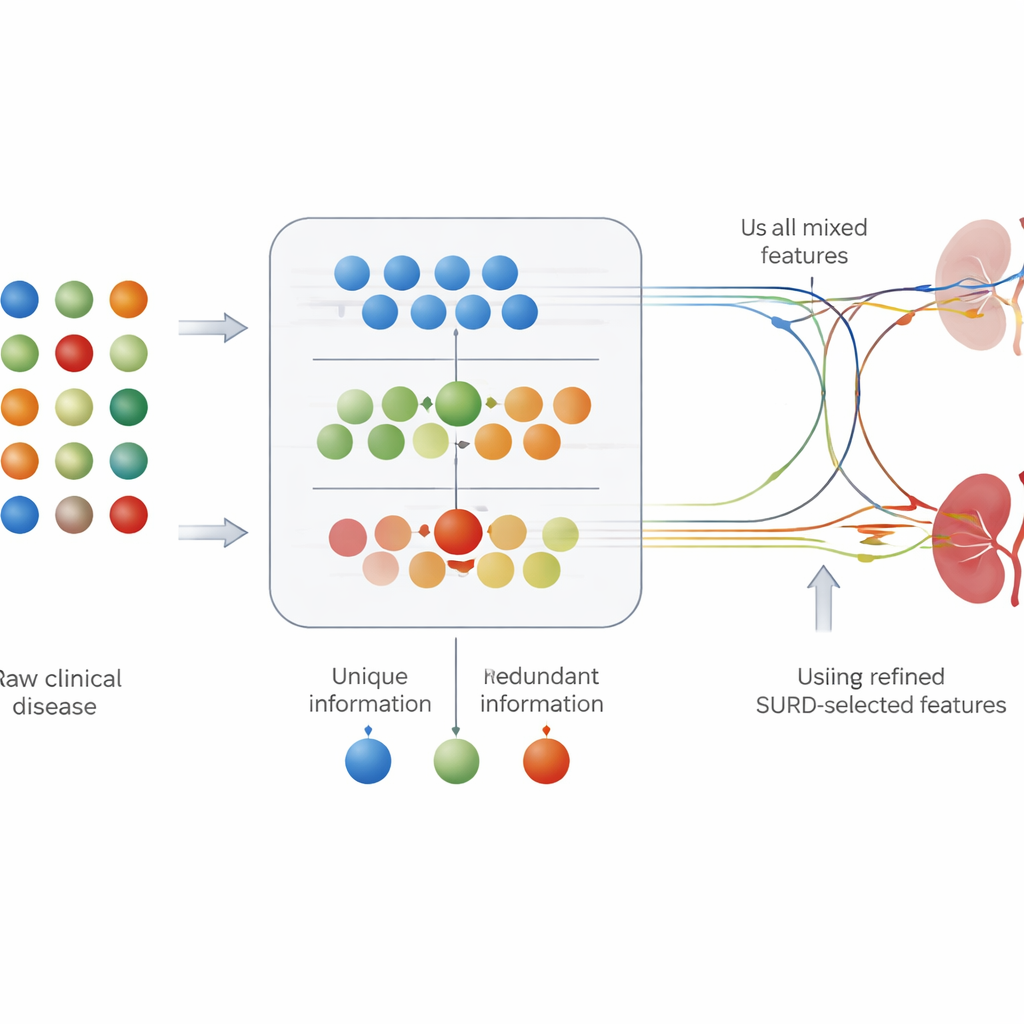
Voir quels tests comptent et comment
La précision seule ne suffit pas pour une utilisation clinique ; les médecins doivent aussi savoir quels résultats de tests motivent une prédiction. L’étude a combiné SURD avec des outils d’explicabilité modernes qui attribuent à chaque caractéristique une contribution à la décision du modèle pour un patient donné. Cette analyse a mis en évidence des marqueurs de risque familiers, comme la créatinine sérique (un indicateur direct de la fonction rénale), le taux d’hémoglobine, la concentration urinaire et la présence de diabète ou d’hypertension. Fait intéressant, SURD a montré que certains de ces facteurs agissent principalement en concert avec d’autres, tandis que la créatinine se distingue comme un signal fortement informatif à elle seule. Ensemble, ces techniques offrent à la fois une vue globale des tests sur lesquels le modèle s’appuie et des décompositions au niveau du patient expliquant pourquoi une personne particulière est prédite à haut risque.
Ce que cela signifie pour les soins quotidiens
En termes simples, l’étude montre qu’il est possible de construire un calculateur de risque de maladie rénale à la fois très précis et raisonnablement transparent. En séparant l’information redondante de l’information véritablement unique dans les données de laboratoire et d’antécédents de routine, les modèles guidés par SURD produisent des prédictions plus nettes sans devenir une boîte noire mystérieuse. Bien que des travaux supplémentaires soient nécessaires sur des populations de patients plus larges et plus diverses, cette approche pourrait, à terme, aider les cliniciens à détecter plus tôt les problèmes rénaux, concentrer l’attention sur les tests les plus informatifs et expliquer aux patients, en termes simples, quels aspects de leur santé mettent leurs reins en danger.
Citation: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
Mots-clés: maladie rénale chronique, prévision du risque rénal, apprentissage automatique médical, IA explicable, dossiers médicaux électroniques