Clear Sky Science · fr
Intelligence humaine versus intelligence artificielle dans le diagnostic en pathologie buccale : étude comparative de ChatGPT, Grok et MANUS
Pourquoi cela compte pour votre prochaine visite chez le dentiste
Lorsque le dentiste découvre une zone suspecte dans votre bouche, le verdict final sur sa nature bénigne ou dangereuse provient généralement d’un spécialiste qui examine le tissu au microscope. Ce travail est minutieux, chronophage, et dans de nombreuses régions du monde il y a un manque d’experts. Cette étude pose une question d’actualité : les systèmes d’intelligence artificielle modernes peuvent‑ils aider à lire ces images microscopiques des tissus buccaux avec une précision proche de celle des spécialistes humains, rendant le diagnostic plus rapide, plus cohérent et plus largement accessible ?
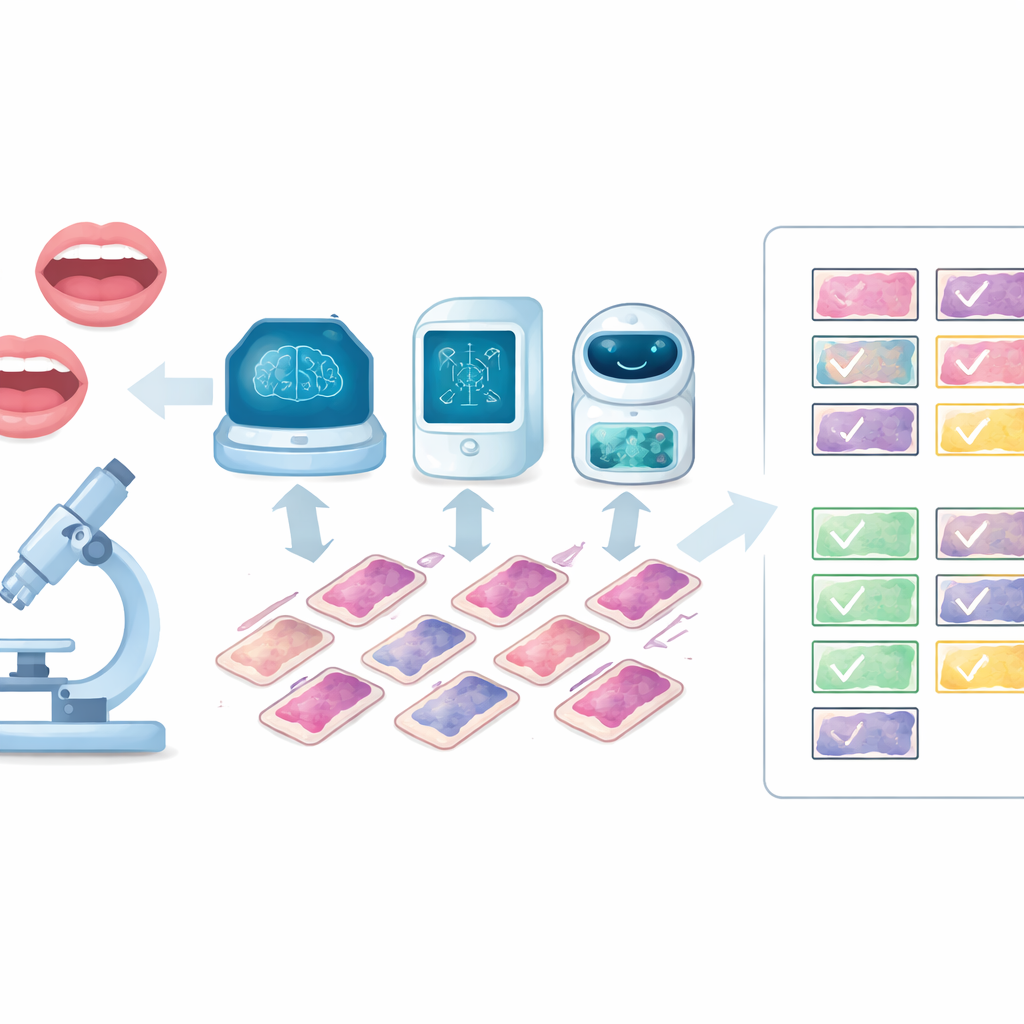
Ce que les chercheurs ont voulu tester
L’équipe s’est concentrée sur trois programmes informatiques avancés connus pour leur compréhension à la fois des images et du langage : ChatGPT, Grok et un système médical appelé MANUS. Plutôt que d’utiliser des données patients réelles, ils ont utilisé 100 images microscopiques claires et de haute qualité tirées d’un manuel standard de pathologies buccales. Chaque image montrait un type de lésion différent, allant des modifications précancéreuses précoces aux tumeurs, kystes et proliférations réactionnelles. Deux pathologistes buccaux expérimentés ont d’abord convenu du diagnostic correct pour chaque lame, créant une référence humaine solide contre laquelle comparer les machines.
Comment la comparaison directe a été menée
Chacune des 100 lames a été présentée aux trois systèmes d’IA à l’aide du même message court décrivant le cas et de la même image numérique. On a demandé aux modèles de nommer le diagnostic le plus probable, comme le ferait un spécialiste lorsqu’il rédige un rapport. Pour vérifier la stabilité des réponses au fil du temps, les chercheurs ont répété l’ensemble du processus deux semaines plus tard avec les mêmes lames et instructions. Parallèlement, les deux pathologistes ont lu indépendamment les lames sans voir les sorties des IA, puis ont discuté des différences jusqu’à parvenir à un accord final. Ces décisions d’experts ont été considérées comme la meilleure référence disponible.
Performance des machines et des humains
Les trois outils d’IA ont obtenu des résultats remarquables. Lors de la deuxième série de tests, Grok a correctement identifié 97 cas sur 100, MANUS 96 et ChatGPT 94. Le duo de spécialistes humains a obtenu un score légèrement supérieur, classant correctement 98 lames. ChatGPT s’est distingué par des réponses quasiment identiques entre les deux sessions, montrant une très forte cohérence interne, tandis que MANUS et Grok ont également affiché des performances solides et stables. Lors de comparaisons entre systèmes, ils se sont mis d’accord sur la grande majorité des cas, ce qui suggère que des architectures d’IA différentes peuvent aboutir à des jugements très similaires lorsqu’on leur fournit des images de haute qualité.
À quel point l’IA se rapproche de la réflexion des experts
Trouver la bonne réponse n’est qu’une partie de l’histoire ; il importe aussi de savoir si les ordinateurs suivent des raisonnements comparables à ceux des humains. Sur ce point, MANUS a montré l’alignement le plus étroit avec les décisions des pathologistes, même lorsqu’il n’a pas dépassé Grok en précision brute. Grok, bien qu’un peu plus précis globalement, a parfois proposé des choix différents de ceux des experts dans les quelques cas difficiles. La plupart des erreurs pour les trois systèmes survenaient sur des lames visuellement trompeuses même pour des yeux entraînés, là où les modifications tissulaires se chevauchaient ou semblaient limites entre deux conditions. Néanmoins, il n’y avait pas d’écarts de performance majeurs entre les modèles, et les trois ont montré des niveaux d’accord avec les humains que les auteurs décrivent comme modérés à substantiels.
Ce que cela pourrait signifier pour les soins futurs
L’étude suggère que les systèmes d’IA multimodaux actuels sont déjà capables de servir d’aides fiables au diagnostic microscopique des maladies buccales. Ils ne remplacent pas les pathologistes, qui conservent la meilleure précision globale et apportent un jugement clinique essentiel, mais ils pourraient jouer le rôle de seconds lecteurs rapides, soutenir la formation de nouveaux spécialistes ou offrir une assistance de niveau expert dans les régions où l’accès aux services de pathologie dentaire est limité. Comme la recherche a utilisé des images de manuel soigneusement choisies plutôt que des échantillons cliniques désordonnés du monde réel, les auteurs insistent sur la nécessité d’essais complémentaires sur des collections cliniques plus larges et plus variées et avec des informations patient supplémentaires. Si ces vérifications confirment les premiers résultats prometteurs, l’IA pourrait rendre le diagnostic des affections buccales plus précis, plus cohérent et plus accessible pour les patients partout.
Citation: Alshammari, A.F., Madfa, A.A. & Anazi, B.A. Human versus artificial intelligence in oral pathology diagnosis: a comparative study of ChatGPT, Grok, and MANUS. Sci Rep 16, 11057 (2026). https://doi.org/10.1038/s41598-026-40792-0
Mots-clés: pathologie buccale, pathologie numérique, intelligence artificielle, grands modèles de langage, diagnostic histopathologique