Clear Sky Science · fr
Évaluer les exigences de résolution pour la discrimination subtile de souches de Caenorhabditis elegans en utilisant des descripteurs classiques et des modèles CNN–Transformer
Pourquoi de tout petits vers et des images nettes importent
Les scientifiques utilisent souvent un ver microscopique appelé Caenorhabditis elegans pour étudier comment les gènes, le vieillissement et les médicaments affectent le système nerveux. De nombreuses souches de vers se ressemblent et se déplacent presque de la même façon à l'œil nu, pourtant ces minuscules différences peuvent révéler le fonctionnement de leurs muscles et de leur cerveau. Cette étude pose une question pratique : à quel point nos images doivent-elles réellement être nettes pour détecter ces changements subtils dans le mouvement, et à partir de quel niveau de résolution les outils d'intelligence artificielle modernes tirent-ils avantage d'images plus détaillées ?
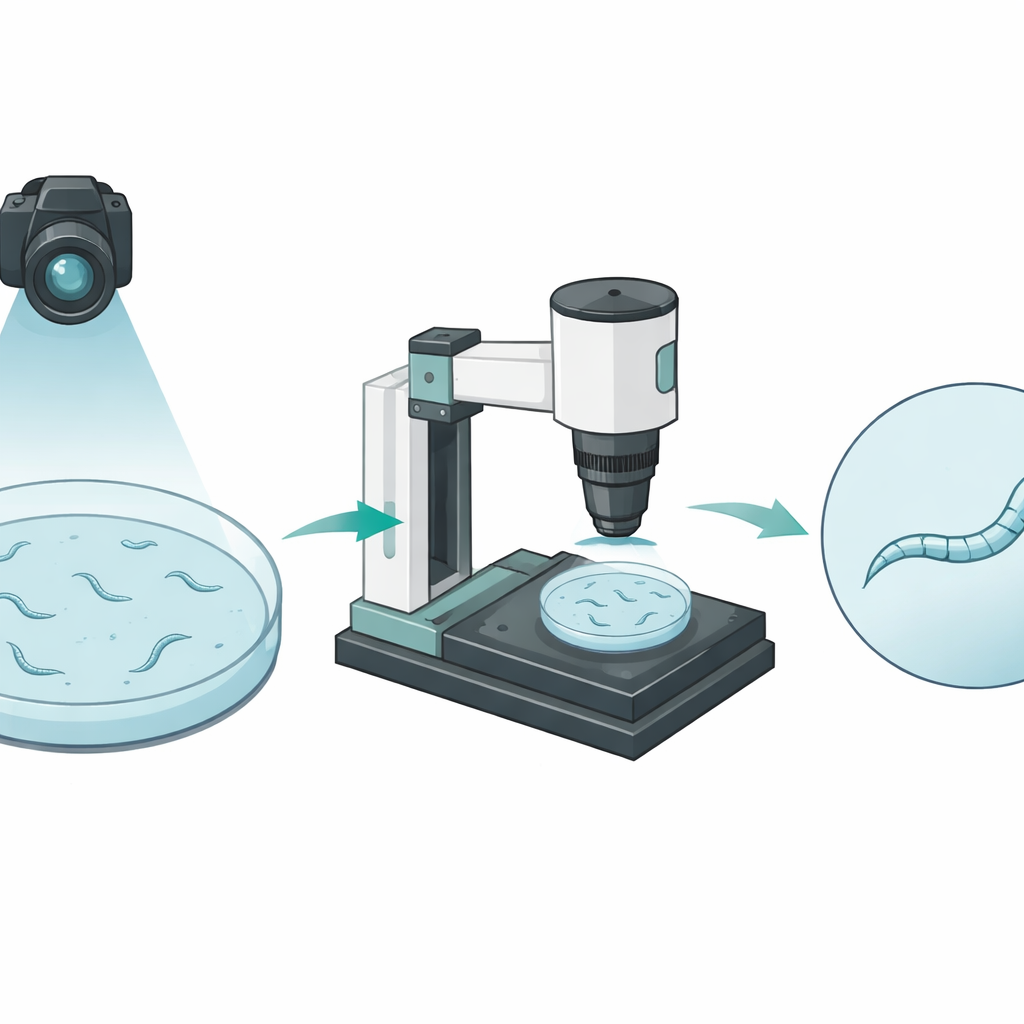
Observer les vers de loin et de près
Les chercheurs ont construit une plateforme d'imagerie automatisée qui observe les vers à deux échelles très différentes. Une paire de caméras filme d'abord une boîte de Pétri entière depuis le dessus, suivant de nombreux vers au fur et à mesure qu'ils rampent. Cette vue large capture la distance parcourue par chaque animal mais montre chaque ver avec seulement quelques pixels de largeur, comme un bonhomme allumette vu de loin. Un microscope motorisé séparé peut ensuite zoomer sur un ver choisi, le maintenant centré et net pendant une minute entière. Dans ces films en gros plan, le corps du ver occupe plusieurs dizaines de pixels en largeur, révélant des flexions et des variations de forme fines au cours du mouvement.
Les mesures simples butent contre une limite
Pour comparer ce que chaque vue pouvait révéler, l'équipe a enregistré trois types de vers. Le premier était la souche sauvage standard utilisée comme référence. Le second était un mutant présentant un mouvement extrêmement maladroit, facile à repérer. Le troisième était une souche spécialement conçue avec seulement de très légers problèmes moteurs, connue pour être difficile à distinguer de la souche de référence même à l'œil. À partir des enregistrements larges et en gros plan, les chercheurs ont extrait des mesures traditionnelles telles que la distance parcourue, la vitesse et l'évolution de la forme corporelle au fil du temps. Comme prévu, les deux vues ont clairement séparé le mutant très maladroit des deux autres souches. Cependant, aucune de ces mesures standards, prises isolément ou combinées, n'a permis de distinguer de manière fiable les vers légèrement altérés des vers normaux.
Laisser l'apprentissage profond lire le mouvement
Puis, les auteurs se sont tournés vers une approche plus flexible : un modèle d'apprentissage profond qui analyse la séquence d'images elle-même au lieu de mesures pré-sélectionnées. Chaque image a d'abord été traitée par un réseau de neurones convolutionnel qui a appris à encoder l'apparence du ver. Ces caractéristiques image par image ont ensuite été alimentées dans un module Transformer, qui a examiné l'évolution de la posture sur la séquence de 60 secondes. Lorsque ce modèle a été entraîné sur les vidéos basse-détail prises à l'échelle de la boîte, sa performance pour séparer la souche subtile de la référence n'a pas dépassé le hasard. Mais entraîné sur les enregistrements haute résolution du microscope, il a systématiquement classé les deux souches avec environ trois quarts de précision, révélant des motifs de mouvement trop faibles pour que les descripteurs classiques les captent.
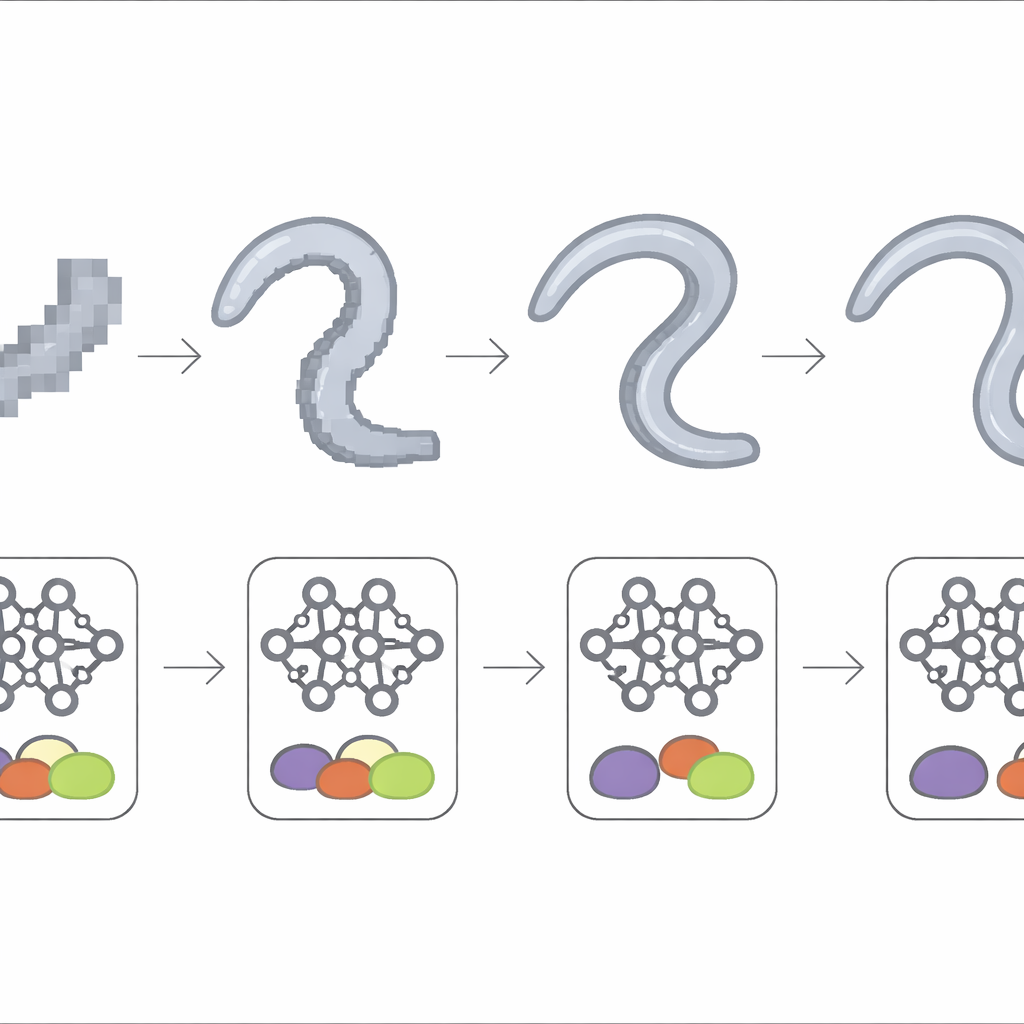
Combien de détail suffit ?
Pour préciser le rôle de la netteté d'image, l'équipe a progressivement dégradé les enregistrements du microscope en réduisant leur taille par des facteurs 2, 4, 8 et 16, réentraînant à chaque fois le même modèle profond. Les performances sont restées élevées tant que le corps du ver occupait encore quelques dizaines de pixels en largeur, ce qui signifie que le modèle tolère une perte modérée de détails. Une fois que le ver a été réduit à environ dix pixels de large ou moins, la précision a chuté brutalement et est devenue instable d'une expérience à l'autre. Aux échelles les plus grossières, les résultats se rapprochaient de ceux obtenus avec la vue large et des méthodes statistiques simples, indiquant que les signatures subtiles du léger défaut moteur avaient effectivement disparu des images.
Ce que cela implique pour les futures études sur les vers
Pour des expériences ne visant à distinguer que des défauts moteurs évidents, une vue large et basse résolution semble suffisante, et les mesures classiques de distance et de vitesse fonctionnent bien. Mais lorsque l'objectif est de détecter de faibles changements dans la façon dont les vers se plient et coordonnent leur corps — comme ceux induits par de légères altérations génétiques ou des effets subtils de médicaments — cette étude montre que l'imagerie haute résolution et les modèles d'apprentissage de séquences sont nécessaires. En termes simples, pour entendre les souffles discrets de la maladie ou des effets de traitement chez ces minuscules animaux, il faut non seulement regarder de près, mais aussi utiliser des outils assez intelligents pour lire les motifs subtils codés dans leur mouvement.
Citation: Peñaranda-Jara, JJ., Escobar-Benavides, S., Puchalt, JC. et al. Evaluating resolution requirements for subtle caenorhabditis elegans strain discrimination using classical descriptors and CNN–transformer models. Sci Rep 16, 8664 (2026). https://doi.org/10.1038/s41598-026-40784-0
Mots-clés: locomotion de C. elegans, classification phénotypique, résolution d'image, apprentissage profond, suivi comportemental