Clear Sky Science · fr
Approche d’apprentissage automatique dynamique pour la prédiction de la charge de travail dans les environnements cloud
Pourquoi la prédiction intelligente du trafic compte
Chaque fois que vous lancez une vidéo en streaming, suivez un grand événement sportif en ligne ou faites des achats lors d’une vente flash, des milliers d’autres personnes peuvent cliquer simultanément. En coulisses, les centres de données cloud s’efforcent de maintenir la rapidité des sites sans dépenser inutilement pour des machines inactives. Cet article aborde une question simple au fort impact pratique : comment les systèmes cloud peuvent-ils anticiper des vagues soudaines de trafic web suffisamment tôt pour allumer et éteindre des serveurs à temps, au lieu de deviner et de payer trop cher ?
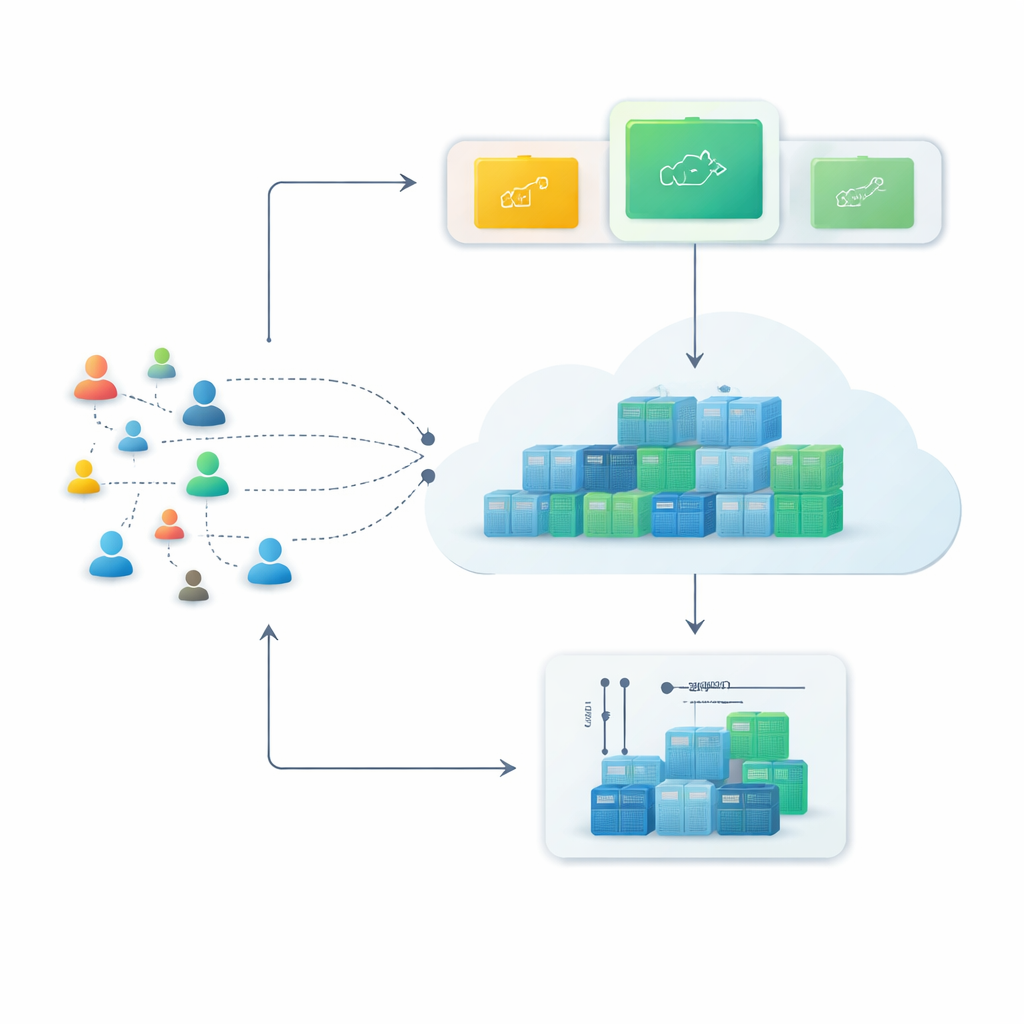
Des serveurs rigides aux conteneurs flexibles
Les plateformes cloud modernes s’appuient de plus en plus sur les conteneurs, de petits paquets logiciels qui peuvent être démarrés ou arrêtés en quelques secondes. Par rapport aux machines virtuelles traditionnelles, les conteneurs sont plus légers et peuvent être densément empaquetés, ce qui les rend idéaux pour les services qui doivent croître rapidement pendant les périodes de forte activité puis diminuer ensuite. Pourtant, cette souplesse n’est rentable que si le système peut anticiper les problèmes — s’il peut prédire combien de requêtes web arriveront dans les prochaines minutes et préparer à l’avance le nombre approprié de conteneurs.
Pourquoi la prédiction universelle échoue
Des travaux antérieurs ont testé de nombreuses approches pour prévoir le trafic web, des statistiques classiques aux réseaux neuronaux profonds. Certaines fonctionnent bien lorsque la demande varie de façon régulière au cours de la journée ; d’autres sont plus adaptées lorsque le trafic saute de manière imprévisible, comme lors d’un match de la Coupe du monde. Le problème est qu’aucune méthode unique n’est optimale en toutes circonstances. Si les opérateurs choisissent un modèle favori et s’y tiennent, la précision peut chuter brutalement dès que le comportement des utilisateurs change, conduisant soit à des sites lents, soit à des rangées de machines sous-utilisées qui gaspillent discrètement argent et énergie.
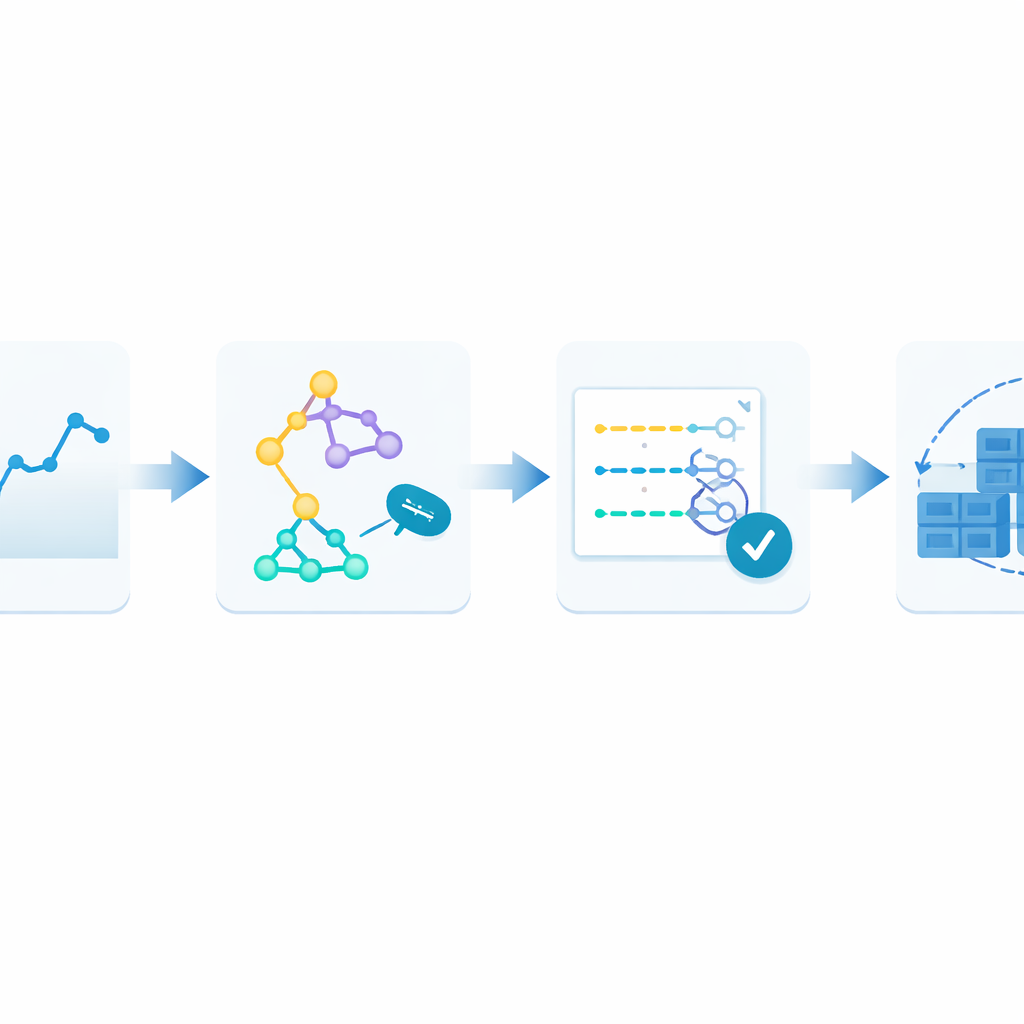
Une boucle d’apprentissage qui n’arrête jamais de s’adapter
Pour surmonter cela, les auteurs proposent un cadre en boucle fermée qu’ils appellent Monitor–Train–Test–Deploy (Surveiller–Entraîner–Tester–Déployer). L’idée est de traiter la prédiction elle-même comme un processus vivant. D’abord, le système enregistre en continu les requêtes web entrantes dans un historique horodaté. Ensuite, il entraîne en parallèle plusieurs méthodes de prévision différentes, chacune tentant d’apprendre les motifs dans cet historique récent. Puis il teste ces modèles candidats sur les données les plus récentes et les note en fonction de l’écart entre leurs estimations et la réalité. Seul le modèle le mieux classé est chargé de produire les prédictions en temps réel, qui guident le nombre de conteneurs à exécuter. À mesure que de nouvelles données arrivent, la boucle se répète : si les erreurs de prédiction dépassent un niveau toléré pendant deux cycles consécutifs, le système réentraîne automatiquement et peut confier le contrôle à un modèle différent.
Évaluer le cadre
Les chercheurs ont évalué cette approche en utilisant à la fois des séries synthétiques et des traces réelles d’activité web. Ils ont généré plusieurs motifs idéalisés — courbes en cloche lisses, charges en hausse régulière à différentes vitesses et trafics très erratiques — et ont également utilisé les archives des sites officiels de la Coupe du monde de 1998 et 2018, où l’intérêt monte brusquement. Pour chaque cas, ils ont comparé trois ou quatre outils de prédiction familiers, notamment une méthode statistique, un modèle à vecteurs de support, un ensemble d’arbres de décision et, dans des expériences ultérieures, un type populaire de réseau neuronal récurrent. Le résultat clé est que le “vainqueur” change selon la situation : les modèles statistiques simples excellent lorsque la demande est stable, tandis que les méthodes basées sur l’apprentissage sont nettement supérieures lorsque le trafic devient sauvage et éclaté.
Gains en précision et en efficacité
En basculant en continu vers le modèle le mieux adapté au comportement observé, le cadre a réduit les erreurs de prédiction d’environ 15 % par rapport au fait de rester avec un modèle fixe. Autre point important : cela se fait sans exécuter tous les modèles en permanence. Un seul prédicteur est actif en opération en direct ; les autres sont réentraînés et vérifiés périodiquement, ce qui maintient la charge de calcul modeste. Les auteurs introduisent aussi un seuil de réentraînement qui se resserre progressivement, de sorte que le système devient moins tolérant aux fautes répétées, réduisant le risque de longues périodes de prévisions médiocres.
Ce que cela signifie pour les utilisateurs quotidiens du cloud
Concrètement, l’étude montre que les plateformes cloud peuvent être gérées plus intelligemment en laissant les modèles de prévision entrer en compétition et en adaptant le choix au fil du temps. Pour les utilisateurs, cela peut se traduire par des expériences en ligne plus fluides lors de grands événements et moins de ralentissements quand des foules apparaissent de façon inattendue. Pour les fournisseurs, c’est la promesse d’une utilisation plus frugale des ressources informatiques, de coûts d’exploitation réduits et d’une moindre consommation d’énergie. Plutôt que de parier sur un algorithme unique et ingénieux, ce travail plaide pour une boucle de contrôle flexible qui continue d’apprendre, de tester et de réviser la façon dont elle anticipe la demande dans un monde numérique de plus en plus imprévisible.
Citation: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Mots-clés: prédiction de charge cloud, autoscaling, conteneurs, apprentissage automatique, séries temporelles