Clear Sky Science · fr
Un système de recherche multi-utilisateurs préservant la confidentialité pour l’intelligence artificielle multimodale
Pourquoi il est important de garder privées les recherches intelligentes
Beaucoup d’entre nous s’appuient désormais sur des intelligences artificielles hébergées dans le cloud pour trier nos photos, documents et même des images médicales. Ces systèmes sont puissants parce qu’ils comprennent à la fois les images et les mots, mais ils posent aussi une question difficile : comment profiter de cette commodité sans révéler la signification de nos données les plus sensibles à des serveurs distants ? Cet article présente PMIRS, un nouveau système qui vise à permettre à de nombreux utilisateurs de rechercher dans des collections mixtes image-et-texte tout en gardant leurs informations cachées aux machines cloud qui exécutent ces recherches.
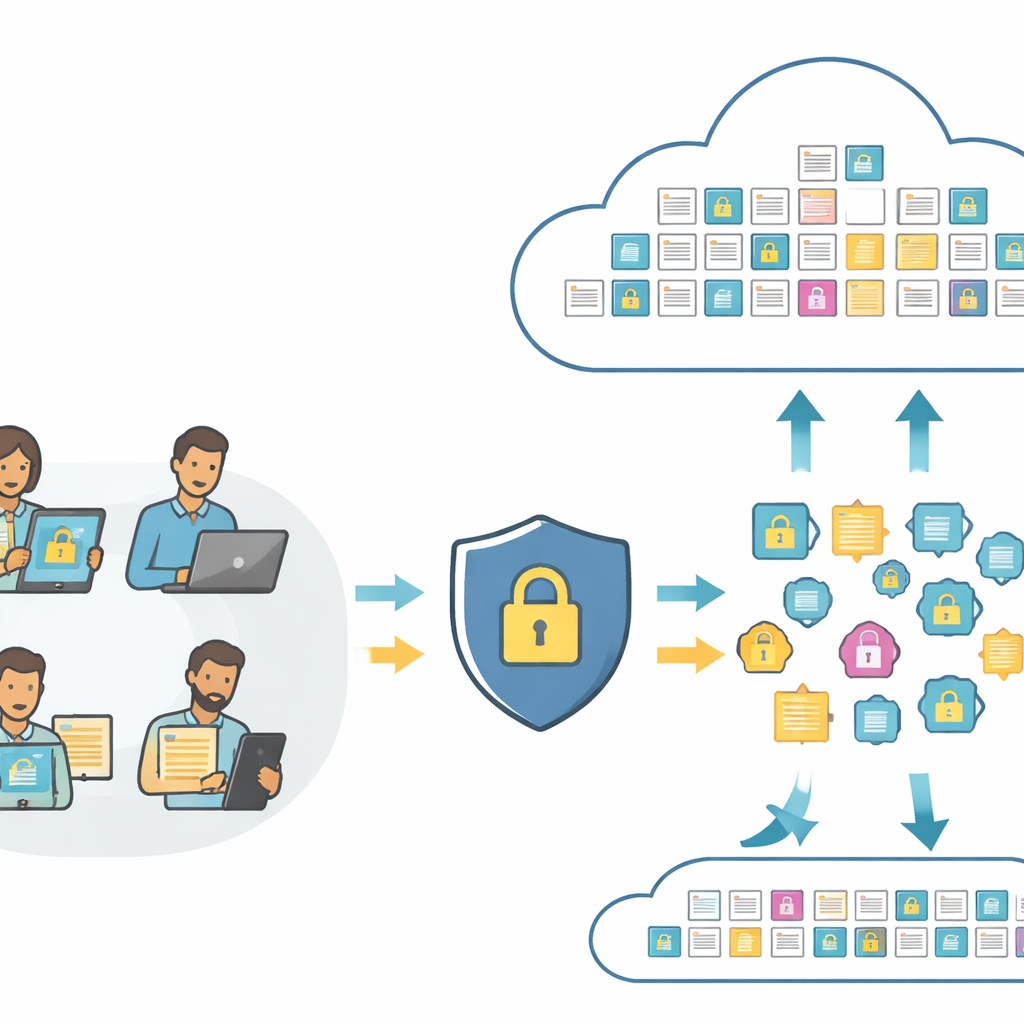
Rechercher des images et du texte sans en montrer le sens
Au cœur des outils de recherche modernes se trouvent les « embeddings » — des empreintes numériques qui capturent le contenu d’une photo ou d’une phrase afin qu’un ordinateur puisse les comparer. Les systèmes classiques envoient ces empreintes directement vers le cloud, où elles peuvent être analysées voire détournées. PMIRS réorganise cette chaîne de traitement. Les utilisateurs envoient d’abord leurs images et textes bruts vers une couche locale, qui les transforme en empreintes à l’aide d’un modèle compact vision-et-langage. Avant toute sortie côté utilisateur, les empreintes sont brouillées de manière contrôlée puis chiffrées. Le cloud ne voit jamais que ces empreintes protégées et des copies entièrement chiffrées des données stockées, et peut pourtant effectuer des appariements et renvoyer les meilleurs résultats.
Apprendre à partir de nombreux utilisateurs sans centraliser leurs données
Former un bon modèle image–texte nécessite normalement de rassembler d’énormes quantités d’exemples annotés en un seul endroit — un risque évident pour la vie privée. PMIRS utilise plutôt l’apprentissage fédéré. Dans cette configuration, le modèle sous-jacent, adapté de l’architecture bien connue CLIP, est envoyé à de nombreux appareils. Chacun s’entraîne localement sur ses propres paires image–texte privées et renvoie uniquement des poids de modèle mis à jour, eux-mêmes chiffrés. Un serveur central moyenne ces mises à jour pour améliorer un modèle partagé sans jamais voir les photos ou descriptions brutes des utilisateurs. Les auteurs réduisent et affinent en outre le modèle via un processus de « distillation » en plusieurs étapes qui élaguent les parties inutiles tout en préservant la précision, rendant le système suffisamment léger pour un déploiement pratique.
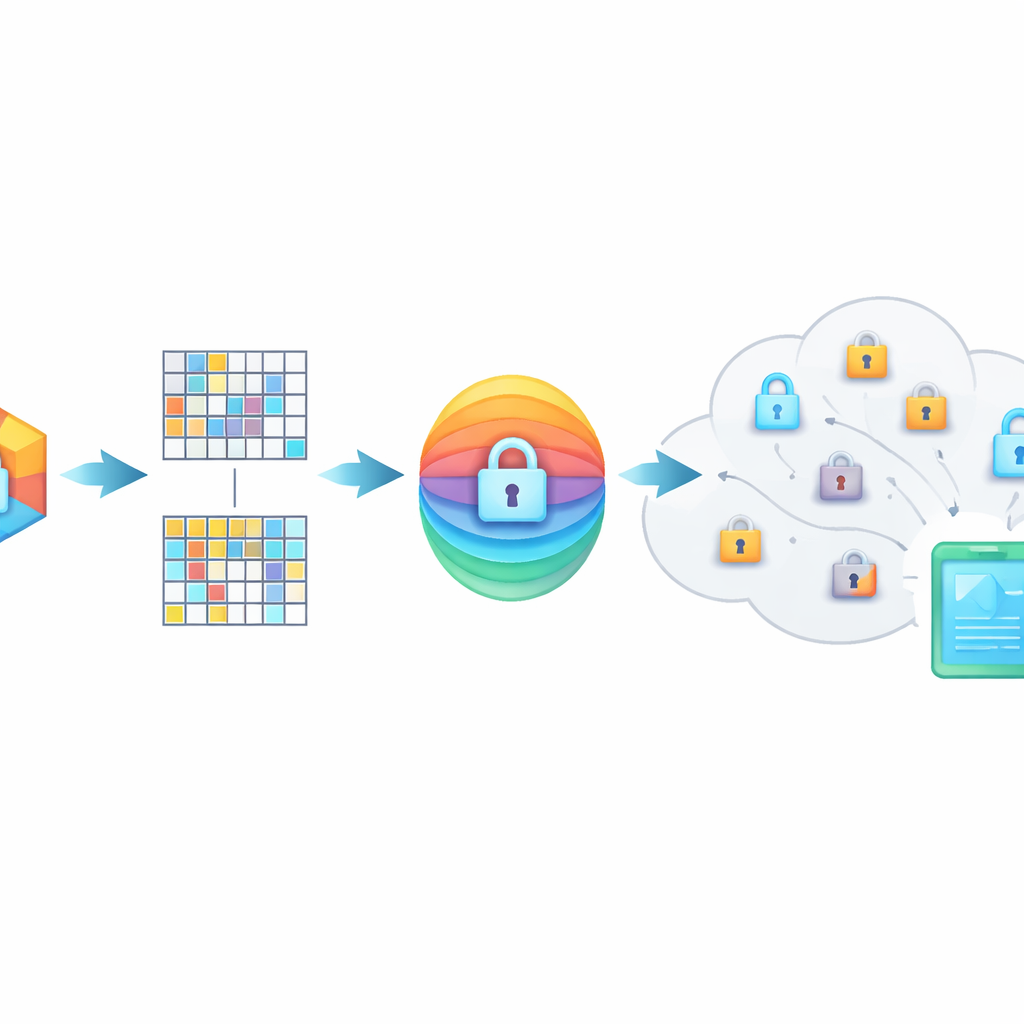
Cacher le sens à l’intérieur d’empreintes brouillées
PMIRS protège les requêtes par un bouclier à deux couches. D’abord, chaque empreinte est découpée en blocs et chaque bloc est transformé par une matrice secrète, enrichie d’un motif de bruit soigneusement conçu. Ce brouillage masque la structure originale des données mais est conçu de façon à ce que, lorsque deux éléments apparentés sont tous deux transformés, leur similarité reste inchangée. Ensuite, le résultat est chiffré en utilisant la méthode AES largement adoptée, avec des clés qui ne sont jamais envoyées en clair sur le réseau. Pour des situations où une personne doit rechercher dans les données d’une autre — par exemple un médecin consultant un spécialiste — le système utilise un protocole d’échange de clés Diffie–Hellman afin qu’ils puissent convenir de secrets partagés sans les exposer à des écouteurs.
Performances du système en pratique
Pour vérifier si ces protections entraînent un coût trop élevé, les chercheurs ont construit un benchmark qui associe des images de la vie courante à de courtes phrases en langage naturel — plus proches de la façon dont les gens décrivent réellement les choses que des étiquettes d’un seul mot. Ils ont comparé PMIRS à une recherche standard basée sur CLIP sur trois thèmes : scènes naturelles, objets manufacturés, et activités ou paysages. Sur de nombreuses tailles de référentiels, PMIRS a systématiquement trouvé un meilleur compromis entre le rappel (trouver tous les bons résultats) et la précision (éviter les correspondances erronées), aboutissant à un score F1 moyen — mesure combinée de précision — environ 7,7 % supérieur à la référence. De manière importante, les temps de réponse sont restés inférieurs à environ 180 millisecondes, assez rapides pour une utilisation interactive, et souvent légèrement meilleurs que la référence non sécurisée malgré les étapes de protection supplémentaires.
Ce que cela signifie pour les utilisateurs quotidiens
Concrètement, PMIRS montre qu’il est possible de construire des outils de recherche cloud qui comprennent bien les images et le texte, servent de nombreux utilisateurs simultanément, et gardent néanmoins la signification des données de chaque personne hors de la portée du fournisseur cloud. En combinant entraînement local, brouillage ingénieux des empreintes, chiffrement solide et échange de clés sécurisé, le système offre une chaîne de traitement bout en bout préservant la confidentialité plutôt que de ne protéger qu’une seule étape. Bien qu’il ne couvre pas encore toutes les attaques possibles et nécessitera des affinements et des essais en conditions réelles, ce travail ouvre la voie à des services futurs — comme la recherche d’images médicales, des assistants de support client ou des archives d’entreprise — où l’on peut bénéficier d’une recherche IA multimodale riche sans craindre autant que son contenu personnel soit révélé ou détourné.
Citation: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Mots-clés: IA préservant la confidentialité, recherche multimodale, apprentissage fédéré, recherche chiffrée, informatique sécurisée dans le cloud