Clear Sky Science · fr
Modèle hybride clustering-plus-régression et analyse de performance pour la prédiction précoce des maladies cardiaques
Pourquoi il est important de détecter tôt les problèmes cardiaques
Les maladies cardiaques se développent souvent de manière silencieuse sur de nombreuses années, et lorsque des symptômes évidents apparaissent, des dommages peuvent déjà être présents. Cette étude examine comment des capteurs corporels quotidiens et une analyse intelligente des données peuvent s’associer pour repérer des signes avant-coureurs plus tôt, offrant ainsi aux médecins et aux patients davantage de temps pour agir. En combinant deux approches différentes de l’analyse des données de santé, les chercheurs visent à rendre les prédictions plus précises sans compliquer l’utilisation de la technologie en milieu clinique réel.
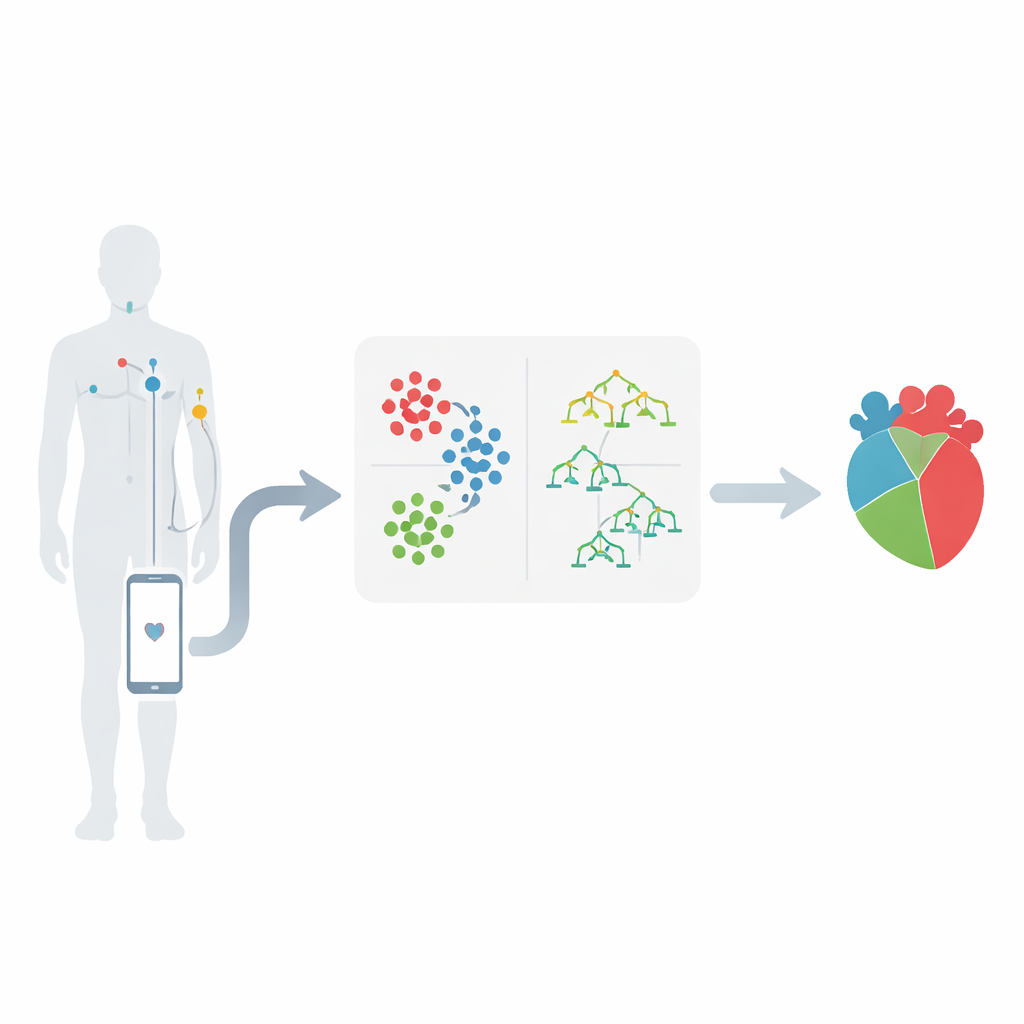
Des capteurs corporels aux alertes intelligentes
Le travail s’inscrit dans le domaine des réseaux corporels sans fil, où de petits capteurs placés sur la peau suivent des signaux tels que la fréquence cardiaque, la tension artérielle et l’activité électrique du cœur. Ces capteurs envoient des mesures à un dispositif mobile, qui les transmet à un centre médical pour analyse. L’idée clé est que ces flux de chiffres peuvent révéler des motifs suggérant des problèmes cardiaques en développement bien avant une crise. Les auteurs se concentrent sur un jeu de données sur les maladies cardiaques bien connu, en sélectionnant 12 caractéristiques importantes, y compris le type de douleur thoracique, la tension artérielle, le cholestérol, la glycémie, l’angine d’effort et les modifications observées à l’électrocardiogramme.
Identifier des groupes cachés dans les données des patients
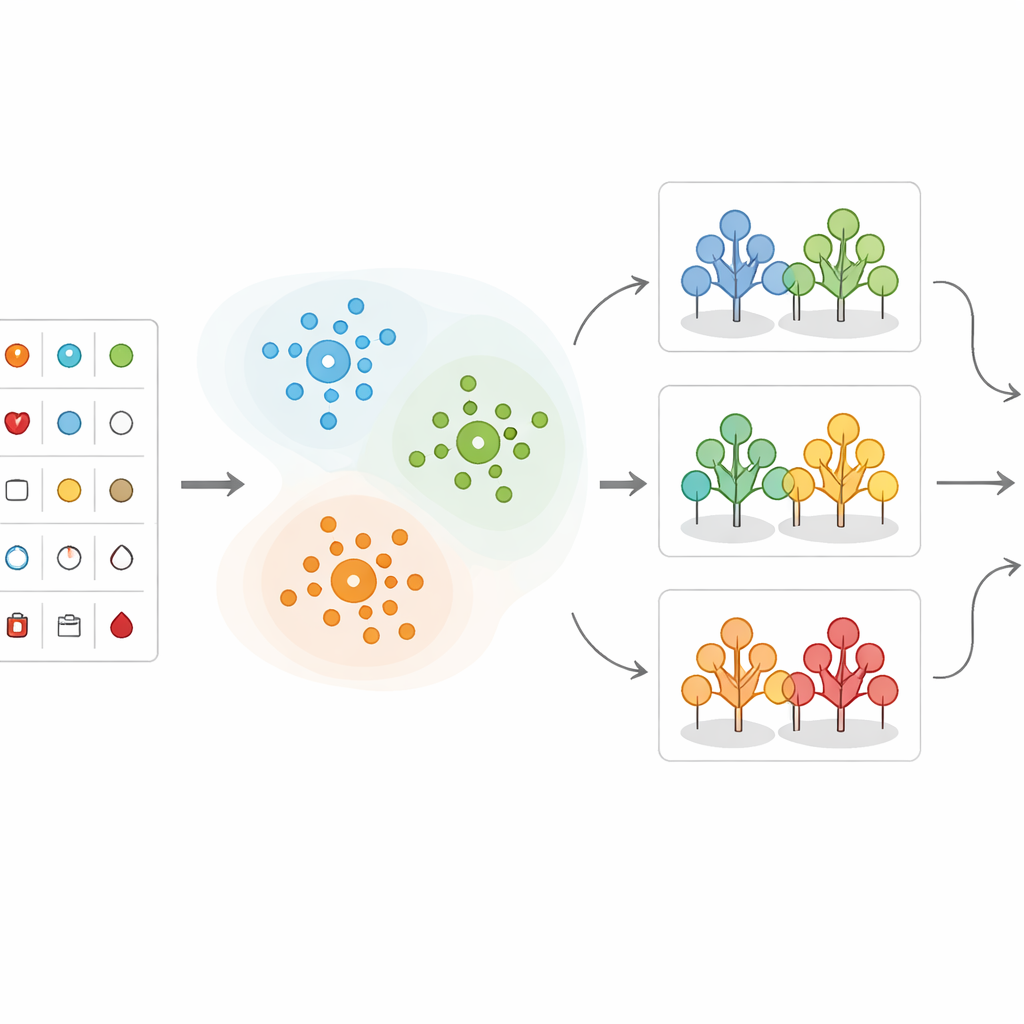
Plutôt que d’alimenter tous les dossiers patients directement dans une formule de prédiction unique, l’équipe regroupe d’abord les patients similaires. Ils utilisent une méthode appelée K-means clustering, qui classe les individus en grappes selon la similitude de leurs mesures, l’âge jouant un rôle central. Par exemple, les patients peuvent naturellement se répartir en groupes présentant une tension artérielle très élevée, un cholestérol élevé ou des schémas particuliers aux tests cardiaques. Cette étape de regroupement aide à mettre en évidence quelles combinaisons de mesures sont particulièrement préoccupantes. Elle révèle aussi que certaines plages—comme une tension artérielle au‑dessus de 150, un cholestérol au‑dessus de 300 ou des modifications particulières des tracés cardiaques—tendent à être associées à un risque beaucoup plus élevé.
Apprendre aux machines à évaluer le risque
Après le regroupement des données, les chercheurs appliquent plusieurs méthodes d’apprentissage automatique qui apprennent à partir de cas passés pour prédire si un nouveau patient est susceptible d’avoir une maladie cardiaque significative. Ils comparent différentes approches, notamment les arbres de décision, les k-plus proches voisins, les machines à vecteurs de support, la régression logistique, le Naïve Bayes et les forêts aléatoires. Dans leur conception hybride, chaque nouveau patient est d’abord affecté à la grappe la plus proche ; ensuite, un modèle de forêt aléatoire entraîné spécifiquement sur ce type de patients effectue la prédiction finale du risque. Les données sont soigneusement nettoyées, mises à l’échelle et séparées en ensembles d’entraînement et de test, et le déséquilibre des classes (plus de patients sains que malades) est géré afin d’éviter que les modèles ne deviennent biaisés en faveur du groupe majoritaire.
Performance du modèle hybride
Pour évaluer le succès, l’étude considère non seulement la précision globale mais aussi la fréquence à laquelle le modèle identifie correctement les patients malades (rappel), tranquillise à bon escient les patients sains (spécificité) et équilibre ces deux objectifs (score F1 et ROC–AUC). Les études antérieures utilisant des données similaires plafonnaient souvent autour de 85 % de précision et peinaient à améliorer ces mesures fines. Ici, l’approche combinant clustering et forêt aléatoire atteint environ 91 % de précision, avec un rappel solide et une très haute spécificité. Les intervalles de confiance pour ce modèle ne se chevauchent pas avec ceux des méthodes plus simples, ce qui suggère que l’amélioration est peu susceptible d’être due au hasard. Parallèlement, le temps de calcul reste dans une plage pratique—de l’ordre de millisecondes à secondes—adaptée aux systèmes de surveillance en temps réel ou quasi‑temps réel.
Ce que cela signifie pour les patients et les médecins
Concrètement, l’étude montre que laisser les ordinateurs trier d’abord les patients en groupes significatifs, puis appliquer des règles de prédiction adaptées, peut affiner la détection précoce des maladies cardiaques. La méthode est particulièrement prometteuse pour les dispositifs de surveillance continue, où des capteurs portables collectent discrètement des données en arrière‑plan. Bien que les résultats proviennent d’un jeu de données structuré de taille modeste plutôt que de dossiers cliniques complets, et que les auteurs mettent en garde contre d’éventuels biais, le message est clair : une utilisation plus intelligente des mesures existantes peut fournir aux médecins un système d’alerte précoce plus fiable. Avec des travaux supplémentaires et des jeux de données plus vastes et plus riches, ce type d’analyse hybride pourrait aider à transformer des relevés bruts de capteurs en alertes personnalisées et opportunes, prévenant infarctus et autres événements graves avant qu’ils ne surviennent.
Citation: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Mots-clés: prédiction des maladies cardiaques, capteurs de santé portables, apprentissage automatique, regroupement de données médicales, modèle forêt aléatoire