Clear Sky Science · fr
Collisions de caractéristiques exactes dans les réseaux neuronaux
Quand des images différentes trompent une machine intelligente
Les systèmes d’intelligence artificielle modernes peuvent reconnaître des visages, lire des scans médicaux et guider des voitures autonomes. Nous savons déjà qu’on peut les tromper par de petites modifications soigneusement conçues d’une image. Cet article montre quelque chose d’encore plus surprenant : ces mêmes réseaux peuvent être aveugles à des changements énormes et évidents, traitant des images très différentes comme si elles étaient identiques. Comprendre comment et pourquoi cela se produit est crucial si nous voulons des systèmes d’IA en qui nous puissions réellement avoir confiance.
Des minuscules retouches aux grands angles morts
Les réseaux neuronaux profonds alimentent les avancées actuelles en vision, en langage et dans bien d’autres domaines. Les recherches antérieures sur les exemples adverses ont révélé qu’un changement à peine visible d’une image peut amener un réseau à la classer à tort avec une grande confiance. Des travaux plus récents ont mis au jour le problème inverse : certains réseaux réagissent à peine à des modifications grandes et évidentes, tout en produisant des prédictions presque identiques. Dans ces cas, les caractéristiques internes extraites de deux images très différentes « entrent en collision », ce qui signifie que le réseau les représente de façon quasiment identique. Cette étude pousse l’idée beaucoup plus loin en démontrant que les réseaux courants n’ont pas seulement des collisions approximatives mais peuvent présenter des collisions de caractéristiques exactes, où deux entrées distinctes sont mappées précisément sur les mêmes signaux internes.
Comment les collisions apparaissent à l’intérieur d’un réseau
Pour expliquer ces collisions, les auteurs regardent sous le capot des réseaux neuronaux et se concentrent sur leurs matrices de poids, les valeurs entraînées qui relient une couche à la suivante. Une collision de caractéristiques se produit lorsque deux entrées différentes produisent la même sortie à une couche ; une fois que cela arrive, toutes les couches suivantes observent la même chose et ne peuvent donc pas distinguer les entrées. Mathématiquement, cela se produit lorsque la différence entre deux entrées appartient à l’« espace nul » des poids d’une couche : des directions dans l’espace d’entrée que la couche ignore complètement. Les auteurs montrent que chaque fois qu’une matrice de poids a une valeur propre nulle ou effectue une projection d’un espace de dimension supérieure vers un espace de dimension inférieure, de telles directions ignorées doivent exister. Comme la plupart des architectures utilisées en pratique, y compris les modèles populaires pour la classification, la segmentation et la détection d’objets, comportent de nombreuses couches de ce type, les collisions ne sont pas des cas marginaux rares mais une propriété presque inévitable de ces réseaux.
Une nouvelle méthode pour construire des entrées en collision
S’appuyant sur ce constat, l’article introduit une recette pratique appelée la recherche dans l’espace nul. Plutôt que de s’appuyer sur l’essai-erreur ou des astuces basées sur le gradient, cette méthode utilise directement l’espace nul de la première matrice de poids. À partir de n’importe quelle image, les auteurs calculent un vecteur que la première couche ignore, puis ajoutent une version mise à l’échelle de ce vecteur à l’image. Parce que cette direction est invisible pour la couche, les caractéristiques internes du réseau — et la prédiction finale — restent exactement les mêmes, même si l’image elle‑même paraît fortement déformée à un observateur humain. La même idée s’étend aux couches convolutionnelles et, en principe, aux couches ultérieures également. Les auteurs examinent de nombreux modèles standards et constatent que la plupart possèdent de nombreuses directions ainsi ignorées, ce qui signifie qu’on peut générer en grand nombre des images en collision pour une large gamme de tâches.
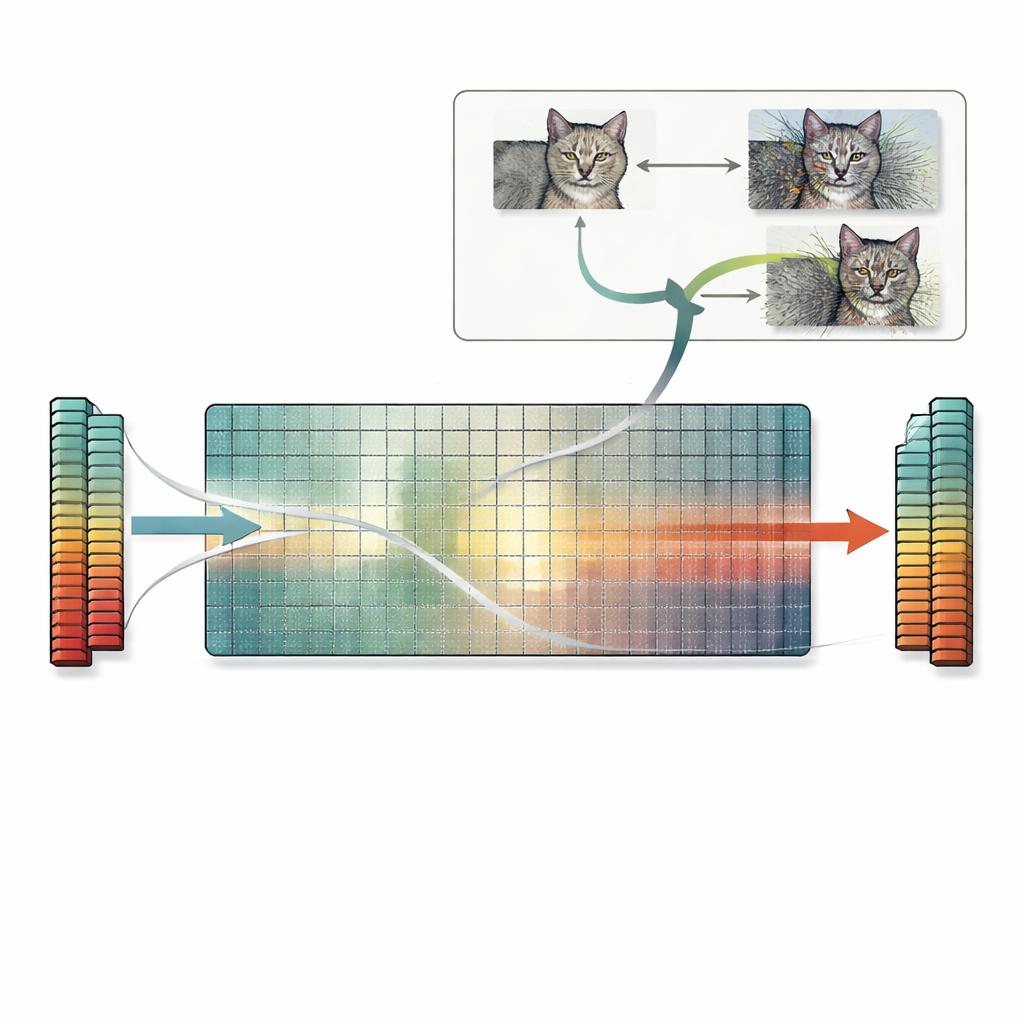
Risques cachés pour la similarité, les explications et la sécurité
Ces collisions de caractéristiques exactes ont des conséquences importantes. Deux images aux caractéristiques en collision ne partageront pas seulement la même prédiction : elles partageront souvent aussi les mêmes cartes d’explication produites par les outils d’interprétabilité populaires. Cela peut faire paraître une image méconnaissable et fortement perturbée aussi bien étayée qu’une image propre, sapant la confiance dans les méthodes d’explication. Le problème touche également les mesures de similarité basées sur les caractéristiques issues des réseaux neuronaux : de tels métriques peuvent juger une image fortement corrompue « identique » à l’original parce que les caractéristiques correspondent exactement, alors que de simples scores basés sur les pixels signaleraient correctement de grandes différences. Enfin, la recherche dans l’espace nul peut être combinée avec des attaques adverses classiques, produisant de nombreuses images adverses différentes qui donnent toutes la même mauvaise prédiction et restent dans les limites de perturbation usuelles, aggravant les préoccupations de sécurité existantes.
Ce que cela signifie pour la construction d’une IA plus sûre
En termes simples, ce travail montre que les réseaux neuronaux actuels jettent souvent de l’information de façon prévisible, laissant des directions entières dans l’espace d’entrée qui n’affectent pas leurs décisions. Des attaquants peuvent exploiter ces angles morts pour créer des images bizarres ou adverses que le réseau considère comme identiques à des images normales. Les auteurs suggèrent d’utiliser de simples comptes de ces directions ignorées comme moyen d’évaluer la vulnérabilité d’un modèle, et soutiennent que des réseaux plus maigres et mieux régularisés, avec des espaces nuls plus petits, pourraient être plus robustes. Bien que beaucoup reste à tester en pratique, le message central est clair : si nous voulons une IA fiable, nous devons prêter attention non seulement à ce à quoi les réseaux réagissent, mais aussi à ce qu’ils ignorent.
Citation: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Mots-clés: réseaux neuronaux, exemples adverses, collisions de caractéristiques, robustesse des modèles, recherche dans l'espace nul