Clear Sky Science · fr
Apprentissage fédéré préservant la confidentialité avec CNN améliorées par une attention légère pour la détection automatisée de la leucémie sur images médicales distribuées
Pourquoi partager le savoir sans révéler les secrets est important
La médecine moderne s’appuie de plus en plus sur des ordinateurs pour interpréter les images médicales, des radiographies aux lames de microscope. Mais entraîner ces systèmes implique généralement de rassembler des données sensibles de patients en un seul lieu, ce qui soulève d’importantes questions de confidentialité. Cette étude montre une méthode permettant aux hôpitaux de construire un système performant pour détecter la leucémie à partir d’images de sang sans jamais partager les données brutes des patients, conciliant protection de la vie privée et précision diagnostique proche du meilleur niveau.
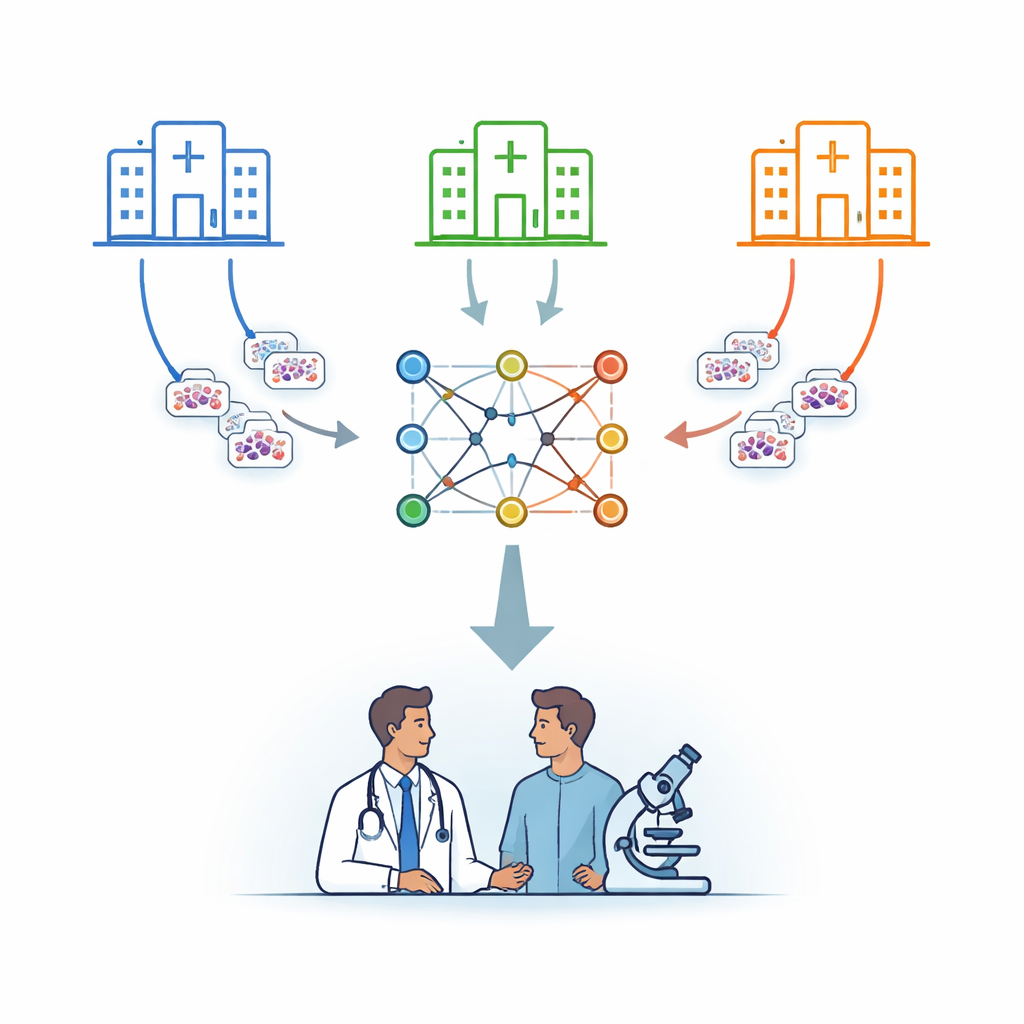
Beaucoup d’hôpitaux, un cerveau partagé
Les chercheurs se concentrent sur la leucémie, un cancer du sang diagnostiqué en partie en examinant des cellules au microscope. Plutôt que d’envoyer les images des patients vers un serveur central, ils utilisent une stratégie appelée apprentissage fédéré. Dans ce dispositif, plusieurs hôpitaux conservent chacun leurs images sur place et entraînent localement une copie du même modèle informatique. Périodiquement, seuls les paramètres appris du modèle sont envoyés à un serveur central sécurisé, qui les moyenne et renvoie un modèle combiné amélioré. Ainsi, les connaissances sont mutualisées tandis que les images sous-jacentes ne quittent jamais leur institution d’origine.
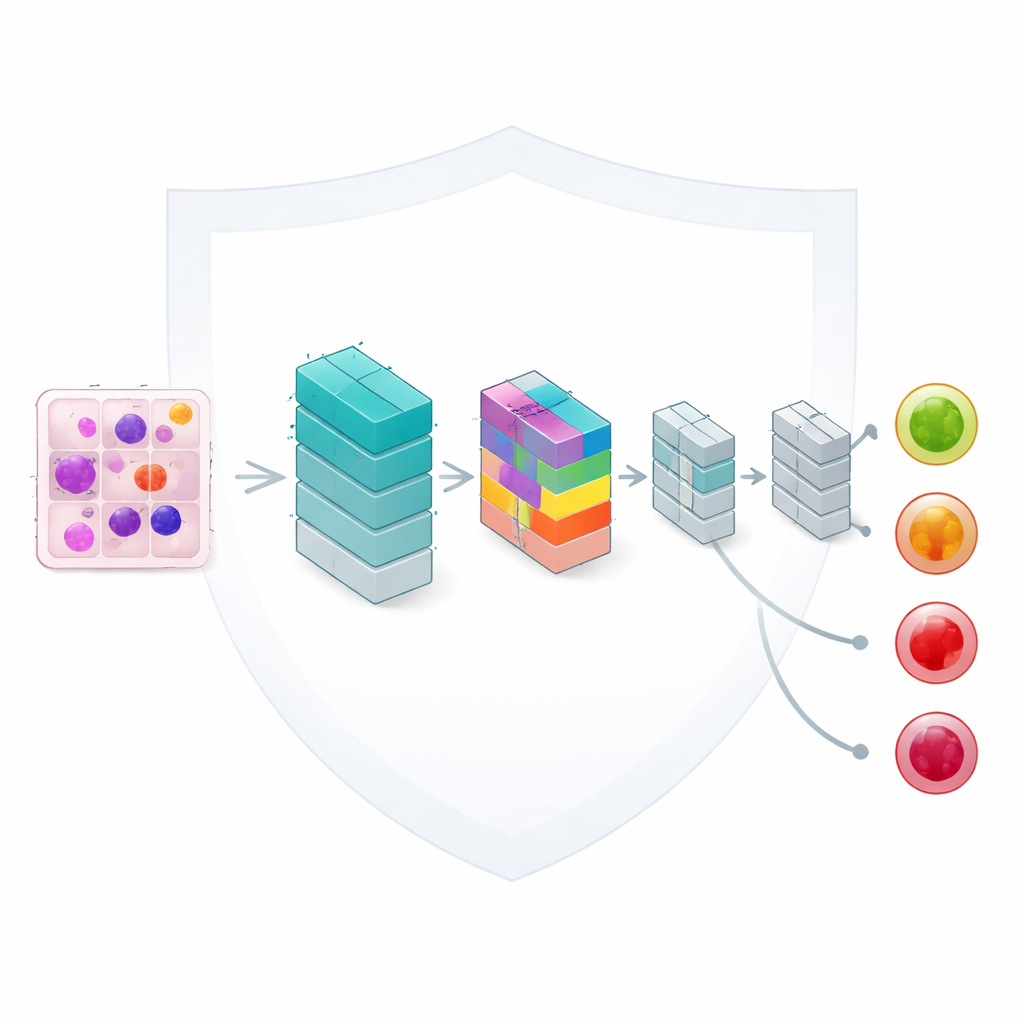
Apprendre à un petit réseau à mieux se concentrer
Au cœur du cadre se trouve un modèle d’analyse d’images léger basé sur des réseaux de neurones convolutionnels, un outil standard pour interpréter les images. Les auteurs l’enrichissent d’un mécanisme d’« attention » compact qui aide le réseau à se focaliser sur les parties les plus informatives de chaque cellule sanguine, comme la forme du noyau et la texture du milieu environnant. Bien que le modèle ne comporte qu’environ 33 000 paramètres ajustables — une fraction de la taille de nombreux réseaux modernes — il peut néanmoins distinguer quatre catégories cliniquement importantes : cellules bénignes, premiers changements, états pré-leucémiques et cellules pro-leucémiques pleinement développées. Une conception soignée maintient la rapidité de calcul nécessaire pour une utilisation réaliste en laboratoires de routine.
Apprentissage équitable à partir de données inégales et dispersées
Dans les systèmes de santé réels, les hôpitaux ne voient pas le même mélange de patients. Un centre peut observer surtout des maladies à un stade précoce, un autre des cas plus avancés. L’équipe reproduit délibérément ce déséquilibre du monde réel en répartissant un jeu de données de 3 256 images de frottis sanguins entre plusieurs hôpitaux simulés présentant des proportions différentes de chaque stade de leucémie. Ils analysent ensuite comment cette distribution inégale affecte l’apprentissage, en utilisant des mesures statistiques pour quantifier à quel point les données de chaque hôpital diffèrent et combien leurs performances finales se ressemblent. Un schéma de moyenne pondérée garantit que les sites disposant de plus de données ont une influence proportionnée tout en maintenant des différences de performance entre sites très faibles.
Une précision qui rivalise avec l’entraînement centralisé
Malgré la conservation des données fragmentées et leur répartition inégale, le modèle partagé apprend à classer les stades de la leucémie avec une habileté impressionnante. Avec trois hôpitaux simulés, le modèle global atteint environ 95,7 % de précision sur des images de test tenues à l’écart ; avec cinq hôpitaux et davantage de cycles d’entraînement, la précision monte à environ 96,6 %. Les catégories malignes — celles qui représentent des états pré-leucémiques et des maladies plus avancées — sont reconnues particulièrement bien, avec des scores quasi parfaits dans certains cas. La catégorie bénigne, plus difficile et sous-représentée, obtient des résultats légèrement inférieurs, ce qui souligne la nécessité d’un meilleur équilibrage ou de techniques ciblées pour les classes rares mais importantes. Néanmoins, le système fédéré approche la précision obtenue lorsque toutes les données sont centralisées, tout en conservant les avantages en matière de confidentialité liés au stockage local.
Rendre visible et digne de confiance le raisonnement de la machine
Pour inspirer confiance aux cliniciens, les auteurs vont au-delà de la simple précision et examinent comment le modèle prend ses décisions. Ils génèrent des superpositions visuelles qui mettent en évidence les parties de chaque image cellulaire ayant le plus influencé la décision. Ces cartes révèlent que le modèle se concentre sur des caractéristiques médicalement pertinentes, comme des formes nucléaires anormales dans les stades plus dangereux de la leucémie, et montre des motifs plus diffus pour les cellules bénignes. L’équipe étudie également la confiance du modèle dans ses prédictions et constate que les bonnes réponses sont souvent associées à une grande confiance, en particulier pour les stades malins, ce qui suggère une bonne correspondance entre la certitude du système et sa fiabilité.
Ce que cela signifie pour le diagnostic du cancer à venir
Pour un public non spécialiste, le message clé est qu’il est désormais possible pour les hôpitaux de collaborer à des diagnostics du cancer plus performants sans transmettre les images de leurs patients. Ce travail démontre qu’un modèle compact et soigneusement conçu, entraîné via l’apprentissage fédéré, peut approcher la précision des méthodes traditionnelles basées sur la mise en commun des données tout en respectant les règles de confidentialité et les contraintes pratiques de puissance de calcul et de trafic réseau. Avec des travaux complémentaires pour mieux gérer les types cellulaires sous-représentés et réduire les coûts de communication, des systèmes similaires préservant la confidentialité pourraient être étendus à d’autres cancers et examens d’imagerie, aidant les cliniciens du monde entier à bénéficier d’une expérience partagée sans exposer les patients individuellement.
Citation: Awan, M.Z., Khan, N.A., Strakos, P. et al. Privacy-preserving federated learning with light-weight attention improved CNNs for automated leukemia detection across distributed medical imaging. Sci Rep 16, 9768 (2026). https://doi.org/10.1038/s41598-026-40581-9
Mots-clés: apprentissage fédéré, imagerie de la leucémie, confidentialité IA médicale, CNN à attention, pathologie numérique