Clear Sky Science · fr
CMT-Unet : tirer parti d’un cadre hybride par étapes pour une précision et une efficacité accrues en segmentation d’images médicales
Des vues plus nettes à l’intérieur du corps
La médecine moderne dépend fortement de scanners comme le scanner (CT) et l’IRM pour observer l’intérieur du corps, mais transformer ces images en niveaux de gris souvent floues en contours nets d’organes et de tissus reste un défi. Les médecins ont besoin de limites précises pour planifier des interventions chirurgicales, suivre le fonctionnement cardiaque ou mesurer la réponse d’une tumeur à un traitement. Cet article présente une nouvelle approche de vision par ordinateur, nommée CMT-Unet, conçue pour tracer ces contours de façon plus précise et plus efficace, rapprochant ainsi l’analyse d’images automatisée d’une utilisation clinique quotidienne.
Pourquoi les contours d’image sont importants
Avant une opération ou un traitement complexe, les cliniciens ont souvent besoin d’une carte au niveau du pixel des organes ou des structures présentes sur un examen — un processus appelé segmentation. Traditionnellement, des experts dessinaient ces régions à la main, une tâche longue et fatigante, sujette à la variabilité entre observateurs. Au cours de la dernière décennie, les méthodes d’apprentissage profond ont pris en charge une grande partie de ce travail, en particulier les modèles basés sur les réseaux convolutifs et les mécanismes d’attention de type Transformer. Les modèles convolutionnels excellent pour capter les détails locaux fins comme les bords, tandis que les Transformers sont particulièrement adaptés à la capture du contexte global à l’échelle de l’image. Cependant, chaque approche présente des compromis : les convolutions peuvent manquer les relations de longue portée, tandis que les Transformers exigent souvent des ressources de calcul et de mémoire importantes.
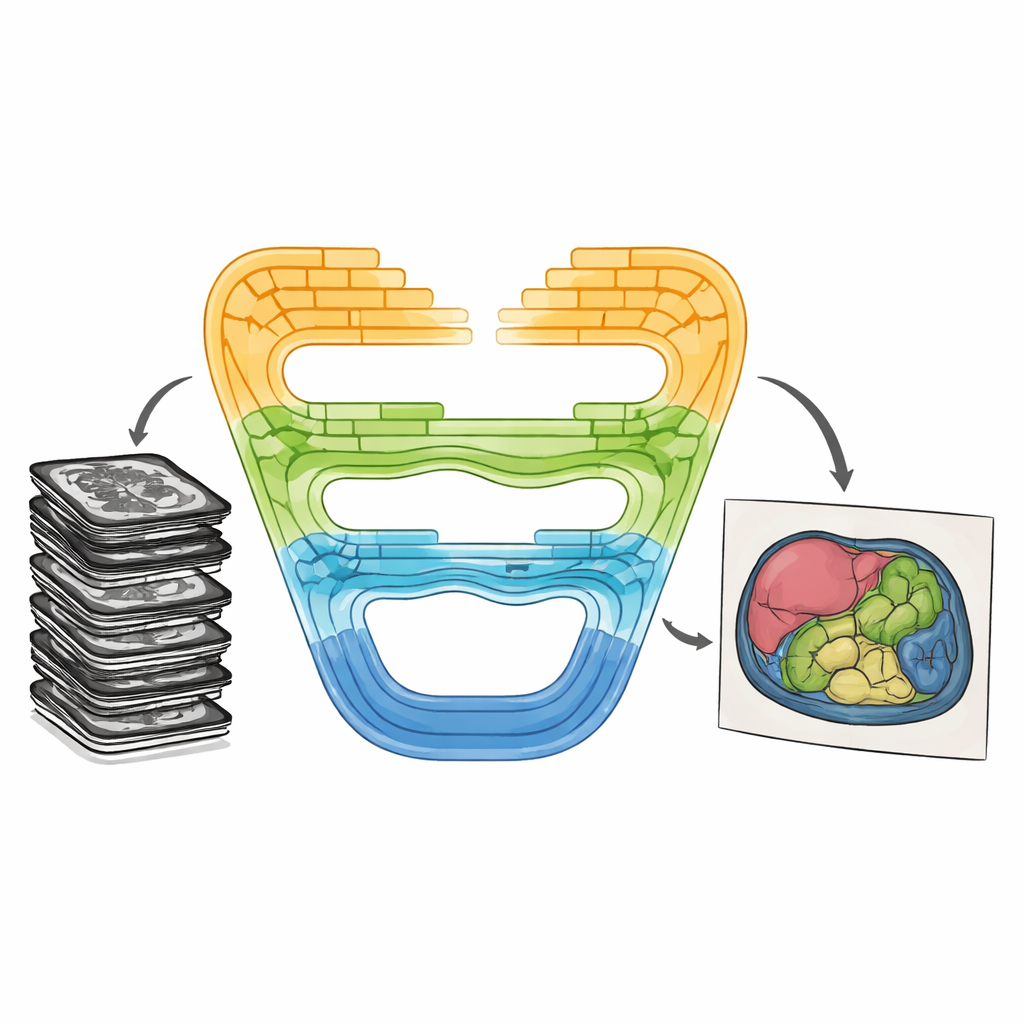
Combiner les forces d’une nouvelle manière
CMT-Unet aborde ces compromis en assemblant trois types de blocs de construction de manière progressive (par étapes), au lieu de s’appuyer sur un seul type de module sur l’ensemble du réseau. À l’avant du système, une unité convolutionnelle à résidu inversé apprend rapidement les motifs locaux — bords nets et textures qui aident à différencier les tissus voisins. Aux stades intermédiaires, un module basé sur des modèles d’espace d’état, adapté d’une architecture récente nommée Mamba, transmet l’information le long de séquences de caractéristiques d’image d’une manière à la fois sensible au contexte et peu coûteuse en calcul. Plus profondément dans le réseau, des blocs Transformer enrichis par l’attention HiLo divisent l’information en composantes haute fréquence et basse fréquence, permettant au modèle de saisir à la fois les très fins détails et les formes organiques larges avant de les recombiner. Cette conception en couches reflète la progression naturelle des pixels bruts vers une représentation plus abstraite au fur et à mesure du traitement des images.
Comment le nouveau modèle fonctionne sous le capot
En pratique, CMT-Unet suit la disposition en U familière et populaire en imagerie médicale : un encodeur qui compresse l’information en caractéristiques plus riches, un décodeur qui reconstruit une prédiction à taille complète, et des connexions de saut qui transmettent les détails spatiaux. La différence clé réside dans les modules employés à chaque profondeur. L’unité convolutionnelle initiale gère la structure fine que les composants Mamba et Transformer risqueraient d’estomper. Le bloc MambaVision modifié améliore ensuite le contexte de portée moyenne en mélangeant l’information spatiale via des opérations bidimensionnelles spécialement conçues, évitant le coût élevé d’une attention complète tout en conservant la vision au-delà des patchs locaux. L’attention HiLo dans l’étape Transformer sépare explicitement les bords nets des motifs d’arrière-plan lisses, les combinant d’une manière qui préserve les frontières. Enfin, un module de suréchantillonnage double dans le décodeur aide à reconstruire des contours propres et continus tout en réduisant des artefacts courants tels que les motifs en damier.
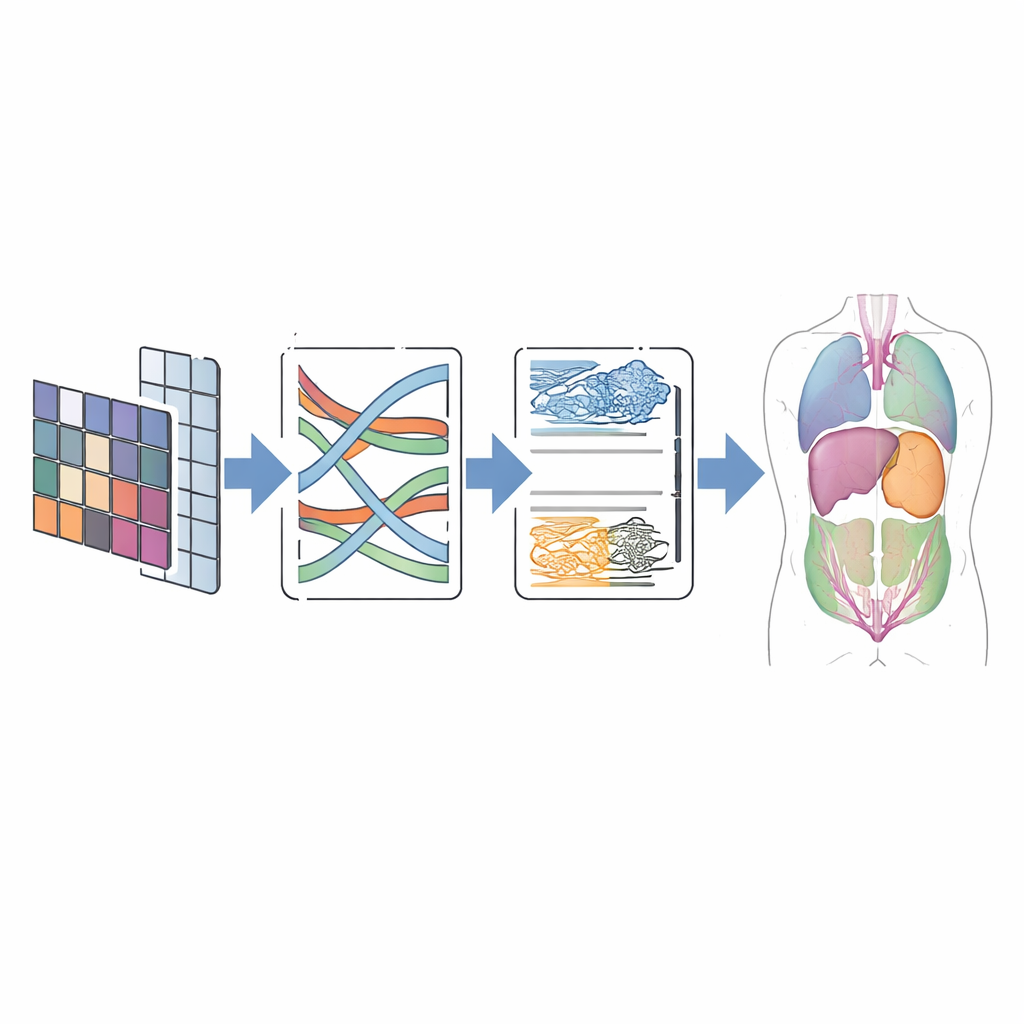
Tests sur des scans du monde réel
Pour vérifier si cette conception porte ses fruits, les auteurs ont testé CMT-Unet sur deux jeux de données publics largement utilisés. Le premier, appelé Synapse, contient des scans CT abdominaux avec huit organes étiquetés, dont le foie, les reins et l’estomac. Le second, ACDC, comprend des images IRM cardiaques avec des annotations pour les ventricules et la paroi musculaire du cœur. Sur ces benchmarks, CMT-Unet a obtenu des scores de segmentation comparables ou supérieurs à ceux des modèles convolutionnels, Transformer et hybrides de pointe, tout en utilisant un nombre modéré de paramètres et une quantité de calcul raisonnable. Les comparaisons visuelles ont montré des limites plus lisses et plus cohérentes sur le plan anatomique, en particulier autour de régions difficiles comme les cavités cardiaques, cruciales pour mesurer la fonction et planifier les interventions.
Ce que cela signifie pour les patients et les cliniques
Pour un public non spécialiste, la conclusion principale est que CMT-Unet offre une manière plus intelligente de tracer les structures dans les images médicales en adaptant soigneusement l’outil à chaque étape du traitement. En équilibrant détails locaux et contexte global, le modèle peut produire des contours d’organes précis et nets sans exiger des ressources de type supercalculateur. Si les travaux actuels se concentrent sur des coupes bidimensionnelles et un ensemble limité de jeux de données publics, l’approche est prometteuse pour des extensions futures en imagerie tridimensionnelle et dans des contextes cliniques plus larges. Si elle est validée davantage, ce type de segmentation légère mais précise pourrait accélérer les diagnostics, fiabiliser la planification des traitements et offrir une assistance en temps réel dans des environnements hospitaliers chargés.
Citation: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Mots-clés: segmentation d’images médicales, apprentissage profond, réseaux neuronaux hybrides, modèles d’espace d’état, imagerie médicale