Clear Sky Science · fr
Une approche d’apprentissage automatique basée sur kNN pour automatiser l’évaluation de la causalité des événements indésirables
Pourquoi cela compte pour les personnes qui prennent des médicaments
Lorsqu’un nouveau médicament arrive sur le marché, son histoire ne fait que commencer. Des millions de personnes l’utiliseront dans le monde réel, et certaines subiront des problèmes de santé qui peuvent ou non être causés par le médicament. Déterminer quelles réactions sont réellement liées au médicament est essentiel pour la sécurité des patients, mais aujourd’hui ce travail est lent, complexe et largement manuel. Cette étude explore comment une forme d’intelligence artificielle simple mais puissante peut aider les experts à examiner ces rapports de sécurité plus rapidement et de manière plus cohérente, sans remplacer le jugement humain qui protège finalement les patients.
Comment les récits de sécurité deviennent des données
Les industriels pharmaceutiques et les autorités s’appuient sur des rapports individuels de sécurité, qui sont des synthèses structurées des expériences réelles de patients avec des médicaments. Chaque rapport peut inclure ce qui s’est mal passé (par exemple, un mal de tête ou un problème hépatique), la gravité, les autres médicaments et maladies présents, et l’avis du réviseur initial sur le lien avec le médicament. Pour plus de 800 000 de ces rapports portant sur six médicaments commercialisés, les réviseurs médicaux de la société avaient déjà décidé si chaque événement indésirable était lié au médicament, non lié, ou impossible à juger en raison d’informations manquantes ou contradictoires. Les chercheurs ont utilisé cet riche historique comme matériau d’entraînement pour un modèle informatique qui apprendrait à imiter ces décisions humaines sur de nouveaux cas.

Apprendre à l’ordinateur à repérer les cas similaires
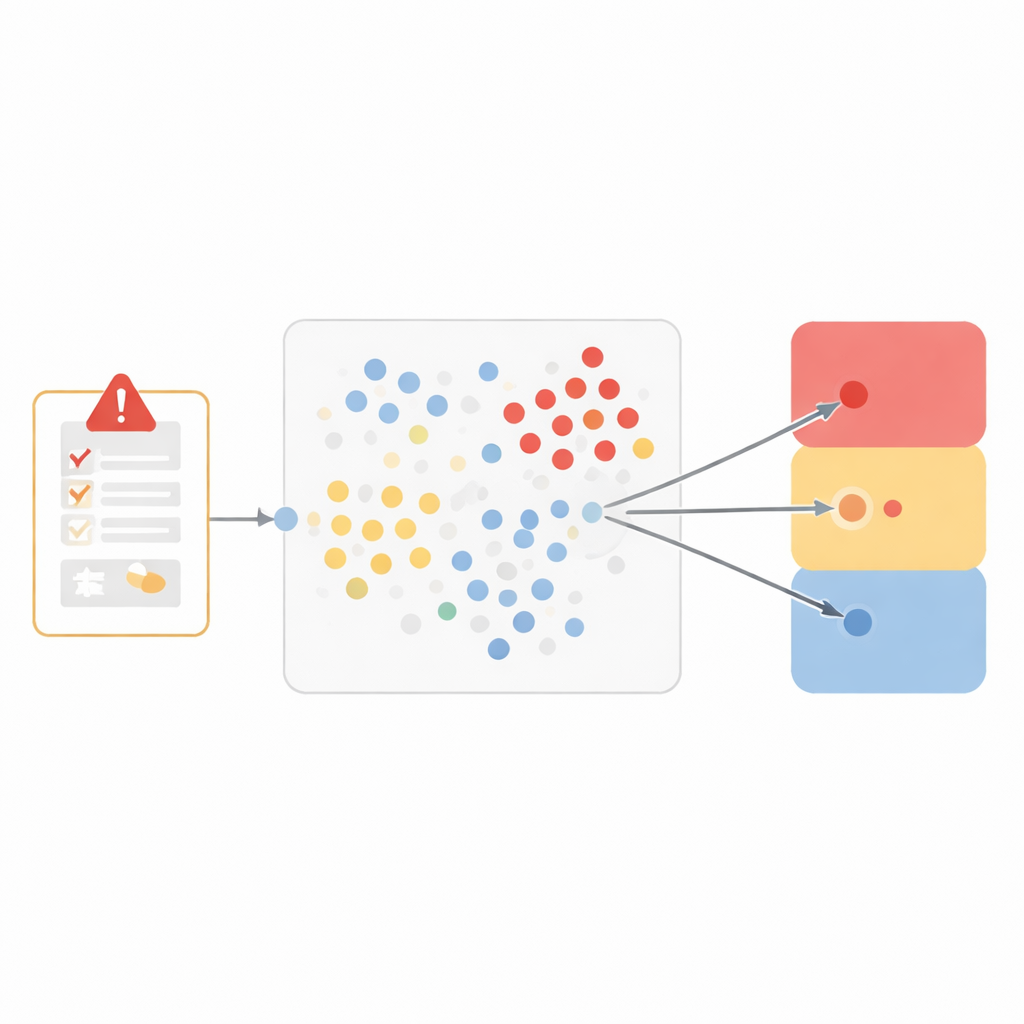
Plutôt que de construire un système boîte noire, l’équipe a choisi une méthode particulièrement transparente appelée « plus proches voisins ». L’idée est intuitive : si deux cas se ressemblent beaucoup, ils partagent probablement la même conclusion sur l’implication du médicament. Pour capter la similarité, les chercheurs ont représenté chaque événement indésirable par un profil en sept volets, incluant le terme médical de l’événement, ce qui s’est passé lors de l’arrêt et de la reprise du médicament, si l’événement était attendu pour ce médicament, l’opinion du déclarant, les autres médicaments pris, les antécédents médicaux et la gravité de l’événement. Ils ont ensuite mesuré la proximité entre deux cas dans cet espace à sept dimensions, en attribuant plus de poids aux caractéristiques les plus pertinentes pour la causalité, telles que l’événement exact et la réaction au changement de traitement.
De la proximité à une décision en trois volets
Quand un nouveau rapport arrive, le modèle remonte dans les données historiques pour trouver les dix cas les plus similaires. Il vérifie ensuite comment ces voisins avaient été classés et les laisse « voter » parmi trois issues larges : probablement lié au médicament, non lié ou improbable, et inévaluable. Ce découpage en trois catégories trouve un équilibre entre la nuance clinique et des performances fiables. Testé sur plus de 250 000 événements jusque-là non vus, le modèle correspondait étroitement aux réviseurs humains pour les événements considérés comme liés et pour ceux jugés inévaluables, avec de faibles taux d’erreur et de bons scores combinant précision et exhaustivité. Il a eu plus de difficulté avec le groupe plus restreint des événements clairement non liés, reflétant le défi pour les systèmes d’apprentissage automatique lorsque un type d’exemple est relativement rare.
Réduire le flou du « ne peut pas déterminer »
Un problème pratique en pharmacovigilance réelle est que l’étiquette « inévaluable » peut devenir une zone attrape-tout lorsque les informations sont rares ou ambiguës, ce qui rend plus difficile la détection de véritables signaux de sécurité. Les chercheurs ont ajouté un outil d’accord qui rend le modèle plus prudent pour attribuer cette étiquette. Plutôt que de choisir « inévaluable » chaque fois qu’elle obtient une simple majorité parmi les cas similaires, le modèle exige désormais un pourcentage plus élevé de voisins en faveur de ce choix. En augmentant ce seuil, l’équipe a pu réduire fortement la fréquence à laquelle le modèle qualifiait un cas d’inévaluable et améliorer les performances pour les deux autres catégories, au prix d’un accroissement de désaccord pour les événements les plus difficiles à juger. Un tableau de bord web permet aux réviseurs médicaux d’ajuster ce seuil par produit, de voir instantanément comment l’équilibre des issues évolue et de concentrer leur attention sur les cas où le modèle et les humains divergent.
Ce que cela signifie pour la sécurité des médicaments à l’avenir
Pour un échantillon de cas récents que les réviseurs humains avaient étiquetés inévaluables, le système a mis en évidence des centaines de cas où sa conclusion différait. Lorsque des réviseurs seniors ont réexaminé ces cas, ils ont été d’accord avec le modèle dans plus des deux tiers des cas, montrant que de tels outils peuvent mettre en évidence des schémas négligés et soutenir la supervision de la qualité sans remplacer les experts. Ce travail montre qu’une approche claire, basée sur la similarité, peut intégrer l’intelligence artificielle à la pharmacovigilance de manière explicable, ajustable et conforme à la pratique médicale. À mesure que les données s’accumulent et que les récits textuels sont ajoutés grâce aux technologies modernes du langage, des systèmes comme celui-ci pourraient aider à repérer plus tôt les risques émergents, tout en laissant aux cliniciens le dernier mot sur les jugements finaux.
Citation: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
Mots-clés: pharmacovigilance, événements indésirables médicamenteux, évaluation de la causalité, apprentissage automatique, k plus proches voisins