Clear Sky Science · fr
KM-DBSCAN : un cadre amélioré de détection des frontières basé sur la densité et les centroïdes pour la réduction de données en vue d’une IA verte
Pourquoi rendre l’IA plus petite peut la rendre plus verte
L’intelligence artificielle a un coût caché : l’électricité. L’entraînement des modèles d’apprentissage automatique modernes consiste souvent à traiter des millions de points de données sur du matériel énergivore, ce qui génère des émissions de carbone. Cet article présente KM‑DBSCAN, une nouvelle méthode pour réduire les jeux de données avant l’entraînement sans jeter l’information réellement utile aux modèles. En ne conservant que les données les plus informatives, la méthode accélère l’apprentissage, réduit la consommation d’énergie et fournit toujours des prédictions précises pour des tâches allant de la reconnaissance de chiffres manuscrits à la détection précoce du cancer de la peau.
Trop de données, trop d’énergie
Depuis des années, la croyance dominante en IA est que davantage de données conduit presque toujours à de meilleurs modèles. Si cela peut améliorer la précision, cela implique aussi des temps d’entraînement plus longs, des machines plus puissantes et des factures d’électricité plus élevées. Les chercheurs ont commencé à distinguer la « Red AI », qui recherche la précision à tout prix, et la « Green AI », qui cherche à concilier performance et impact environnemental. Une voie prometteuse vers une IA plus verte est la réduction de données : au lieu d’alimenter un modèle avec chaque exemple disponible, identifier un ensemble beaucoup plus restreint d’exemples qui définissent néanmoins bien le problème, en particulier les cas limites difficiles qui déterminent les décisions d’un classifieur.
Mélanger deux idées simples pour créer un filtre intelligent
Le cadre KM‑DBSCAN combine deux techniques de clustering bien connues pour agir comme un filtre intelligent sur les données brutes. D’abord, une méthode rapide appelée K‑Means regroupe les points en clusters compacts et remplace chaque groupe par un centre représentant, ou centroïde. Cela réduit le problème de milliers ou millions de points à quelques centaines de représentants. Ensuite, une méthode basée sur la densité (DBSCAN) est appliquée à ces centroïdes pour identifier quelles régions se situent aux frontières entre clusters et quelles sont les intérieurs denses et homogènes ou le bruit isolé. En travaillant au niveau des centroïdes, DBSCAN devient beaucoup plus rapide et moins sensible aux choix fins de paramètres que lorsqu’il est appliqué directement à tous les points de données.

Ne conserver que les cas difficiles et informatifs
Une fois que KM‑DBSCAN a identifié où différents groupes se touchent ou se chevauchent, il conserve uniquement les points de données situés près de ces frontières et écarte à la fois les points d’intérieur profonds et les outliers évidents. Les points d’intérieur sont largement redondants : ils se ressemblent tous et envoient au modèle le même signal sur leur classe. Les points en bordure, au contraire, indiquent au modèle précisément où s’arrête une classe et où commence une autre. Sur des jeux de données synthétiques simples, cette stratégie reproduit les mêmes frontières de décision qu’un classifieur apprend à partir de l’ensemble complet, même lorsque la plupart des points sont éliminés. Sur des jeux de données réels tels que Banana, les chiffres USPS, le jeu de données des revenus Adult, les données de collisions de véhicules, les variétés de haricots secs et des images de peau pour le mélanome, les ensembles réduits préservent la structure clé du problème tout en étant d’un ordre de grandeur plus petits.
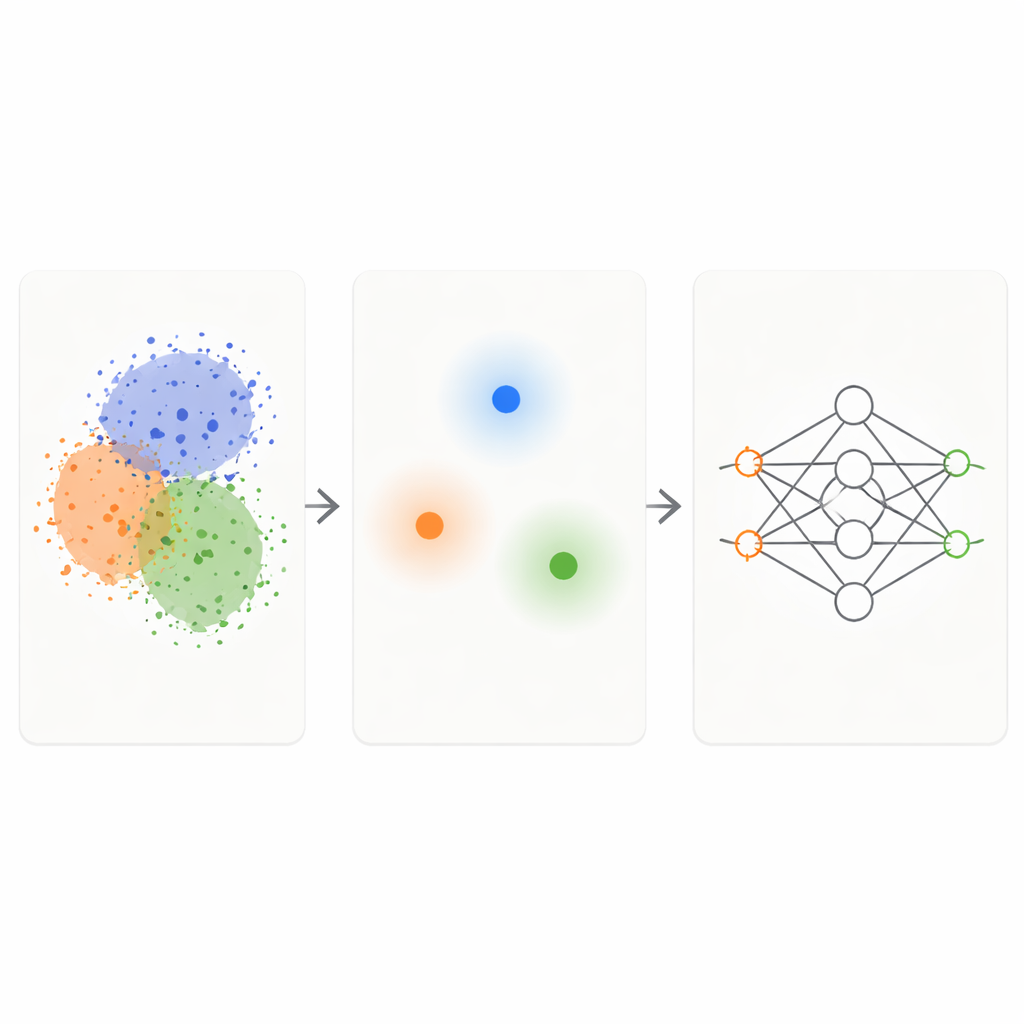
Vitesse, économies de carbone et applications réelles
Les auteurs ont testé KM‑DBSCAN comme prétraitement pour plusieurs modèles populaires, y compris les machines à vecteurs de support, les perceptrons multicouches et les réseaux de neurones convolutifs. Dans de nombreux cas, l’entraînement sur les données réduites a été des dizaines à des milliers de fois plus rapide tout en conservant presque la même précision — et parfois en l’améliorant légèrement. Par exemple, pour la reconnaissance de chiffres manuscrits, la méthode a réduit l’ensemble d’entraînement à seulement 1,4 % de sa taille originale tout en faisant légèrement augmenter la précision, et en rendant l’entraînement 284 fois plus rapide. Dans une tâche de prédiction de revenu avec des classes déséquilibrées, elle a obtenu un gain de vitesse de 6907 fois en n’utilisant qu’environ 3 % des données avec une perte minimale de précision. Dans une expérience de détection du mélanome, un réseau de neurones profond a atteint plus de 90 % de précision tout en s’entraînant sur moins d’un tiers du jeu d’images cutanées initial, avec des émissions de carbone réduites de plus de 70 %.
Ce que cela signifie pour l’IA au quotidien
Pour les non‑spécialistes, le message clé est qu’une sélection plus intelligente peut l’emporter sur la simple quantité. KM‑DBSCAN montre que choisir soigneusement les exemples qu’un modèle voit — en se concentrant sur les cas frontières les plus informatifs — peut réduire considérablement le temps de calcul et la consommation d’énergie tout en maintenant la fiabilité des prédictions. Cette approche s’inscrit parfaitement dans l’élan plus large de la Green AI, où la qualité des données et la conception réfléchie des pipelines d’entraînement comptent autant que la taille brute des modèles. Si elle était largement adoptée, une telle filtration consciente des données pourrait rendre plus durables des domaines allant de l’analyse d’images médicales aux systèmes de sécurité routière, et permettre à des organisations dépourvues de ressources informatiques massives d’accéder à des outils d’IA puissants.
Citation: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Mots-clés: IA verte, réduction de données, regroupement, efficacité de l’apprentissage automatique, détection du mélanome