Clear Sky Science · fr
Amélioration de la parcimonie des signaux sources basée sur l’algorithme local maximum synchroextracting pour l’estimation de matrices mixtes en UBSS
Démêler des signaux cachés
Beaucoup des technologies sur lesquelles nous comptons — réseaux sans fil, radars, appareils d’imagerie médicale et même microphones intelligents — doivent extraire des signaux faibles qui sont irrémédiablement mélangés. Imaginez essayer de suivre plusieurs conversations à la fois dans un café bondé avec seulement deux oreilles. Cet article présente une nouvelle méthode pour « démêler » de tels signaux qui se chevauchent lorsqu’il y a moins de capteurs que de sources, un cas notoirement difficile. En affinant la manière dont nous observons les signaux dans le temps et la fréquence, et en améliorant la façon dont les ordinateurs regroupent les données apparentées, les auteurs montrent qu’ils peuvent séparer les mélanges de façon plus précise et plus fiable, même dans des conditions bruitées du monde réel. 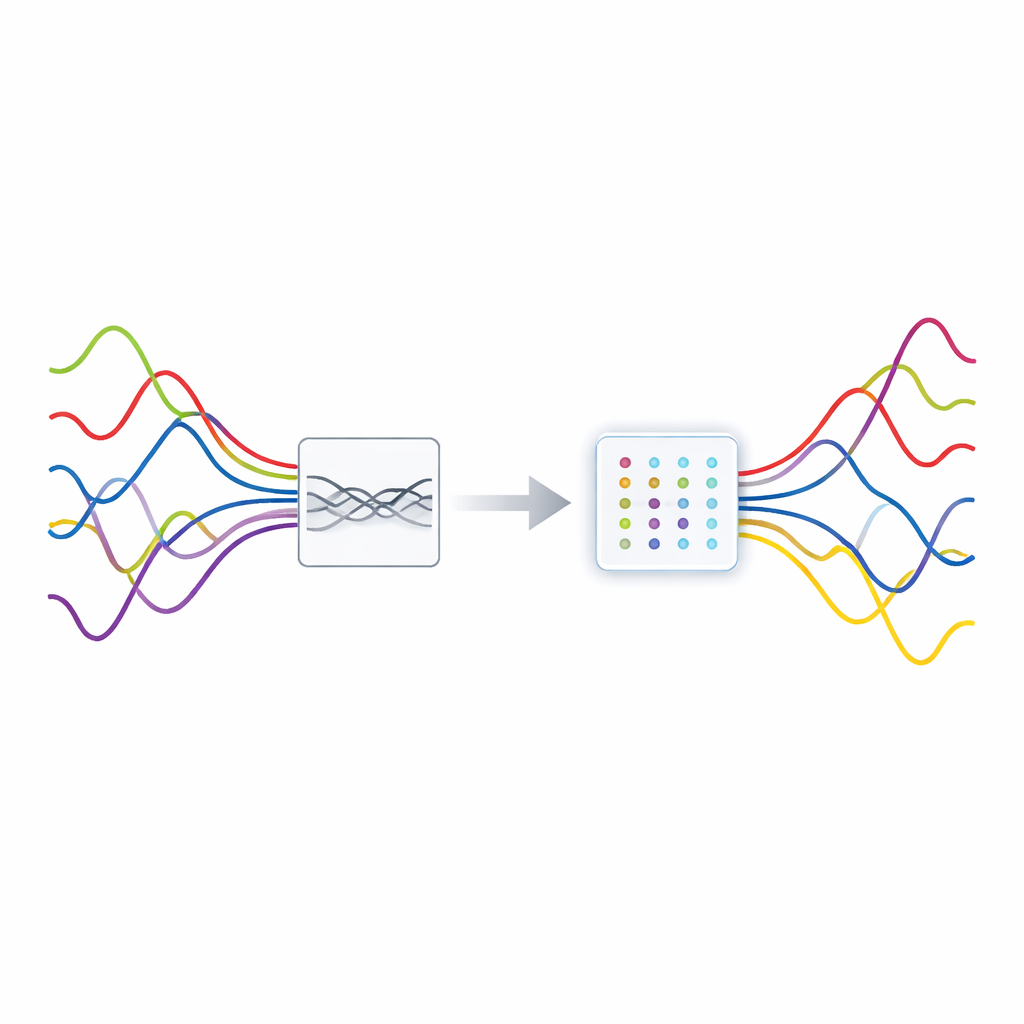
Pourquoi il est si difficile de séparer des signaux mixtes
Dans de nombreux systèmes, plusieurs signaux indépendants voyagent par le même canal et sont captés par un petit nombre de récepteurs. Cette situation, appelée séparation aveugle de sources sous-déterminée, signifie qu’il y a plus de sources inconnues que de mesures. Les méthodes classiques de séparation des signaux supposent généralement le contraire, elles échouent donc ici. Une astuce moderne essentielle consiste à exploiter la parcimonie : dans une représentation adaptée, chaque source n’est active que sur quelques instants ou fréquences. Si, à la plupart des instants, une seule source domine, l’ensemble des données observées forme naturellement des groupes dont les directions codent la façon dont chaque source s’est mélangée aux récepteurs. Trouver ces groupes avec précision dépend toutefois d’une représentation où l’énergie de chaque source est concentrée de façon nette plutôt que diffusée.
Affiner l’image d’un signal
Pour révéler la parcimonie, les ingénieurs transforment souvent les signaux en une représentation temps–fréquence qui montre quelles composantes fréquentielles sont présentes à quels instants. La transformée de Fourier à court terme simple procède en déplaçant une fenêtre le long du temps et en calculant de nombreux petits spectres, mais elle étale l’énergie et ne peut pas simultanément donner une grande précision temporelle et fréquentielle. Des variantes plus avancées comme le synchrosqueezing et le synchroextracting cherchent à attirer l’énergie étalée vers la crête qui suit la fréquence instantanée d’un signal. Ces méthodes améliorent la mise au point, mais elles restent vulnérables au bruit : quand des perturbations aléatoires se compressent le long des mêmes crêtes que le signal, le résultat peut être une bande brillante mais floue qui masque la structure fine.
Repérer les maxima locaux pour renforcer la parcimonie
S’appuyant sur ces idées, les auteurs introduisent la Transformée Local Maximum Synchroextracting, ou LMSET. Plutôt que de pousser toute l’énergie environnante vers une crête fréquentielle, LMSET scanne le plan temps–fréquence et, pour chaque instant, se fixe sur les maxima locaux le long de l’axe des fréquences. Seuls les coefficients autour de ces maxima locaux sont conservés et réaffectés, tandis que le reste est supprimé. Ce simple changement produit une représentation où l’énergie de chaque composante est concentrée en courbes fines et nettes avec beaucoup moins de points parasites. À travers des simulations sur des signaux tests multi-composantes, LMSET obtient la plus faible entropie de Rényi, une mesure standard de concentration, surpassant les méthodes conventionnelles et de pointe sur une large gamme de niveaux de bruit. En clair, LMSET donne une image plus nette de l’endroit où vit chaque signal dans le temps et la fréquence.
Regroupement plus intelligent pour apprendre le mélange caché
Une image plus nette n’est qu’une moitié du travail ; l’étape suivante consiste à regrouper les points obtenus pour estimer la matrice de mélange inconnue qui décrit comment chaque source contribue à chaque récepteur. De nombreuses approches s’appuient sur le fuzzy C-means, une méthode de regroupement populaire qui reste souvent bloquée sur de mauvaises solutions parce qu’elle est très sensible à l’initialisation et aux points aberrants. Pour surmonter ces faiblesses, les auteurs couplent LMSET à un nouveau schéma de regroupement plus robuste. Ils utilisent d’abord un algorithme de recherche basé sur PID, inspiré de la théorie du contrôle, pour explorer l’ensemble de l’espace des centres de clusters possibles et éviter de mauvaises positions initiales. Ils introduisent ensuite un mécanisme de poids booléen pour réduire l’influence des valeurs aberrantes et emploient une stratégie fondée sur l’entropie d’information qui diminue la sensibilité aux conditions initiales. Ensemble, ces étapes permettent au regroupement de s’ancrer plus systématiquement sur les véritables directions des sources cachées.
Ce que révèlent les tests
Les auteurs testent leur chaîne complète — LMSET plus le regroupement amélioré — sur des mélanges de signaux de communication modulés numériquement, incluant QAM, QPSK et FSK, en environnements calmes et bruités. Ils comparent les matrices de mélange estimées aux vraies en utilisant l’erreur angulaire et l’erreur quadratique moyenne normalisée. Dans tous les cas, l’utilisation de LMSET au lieu d’une transformée traditionnelle réduit les erreurs, car les points de données forment des groupes plus serrés et mieux distincts. Parmi les méthodes de regroupement, le fuzzy C-means robuste optimisé par PID proposé obtient les plus faibles écarts angulaires moyens et les meilleurs scores d’erreur. Globalement, la méthode combinée améliore l’exactitude de l’estimation de la matrice de mélange d’environ 20 % par rapport aux approches conventionnelles, tout en conservant de bonnes performances même à des niveaux de bruit élevés. 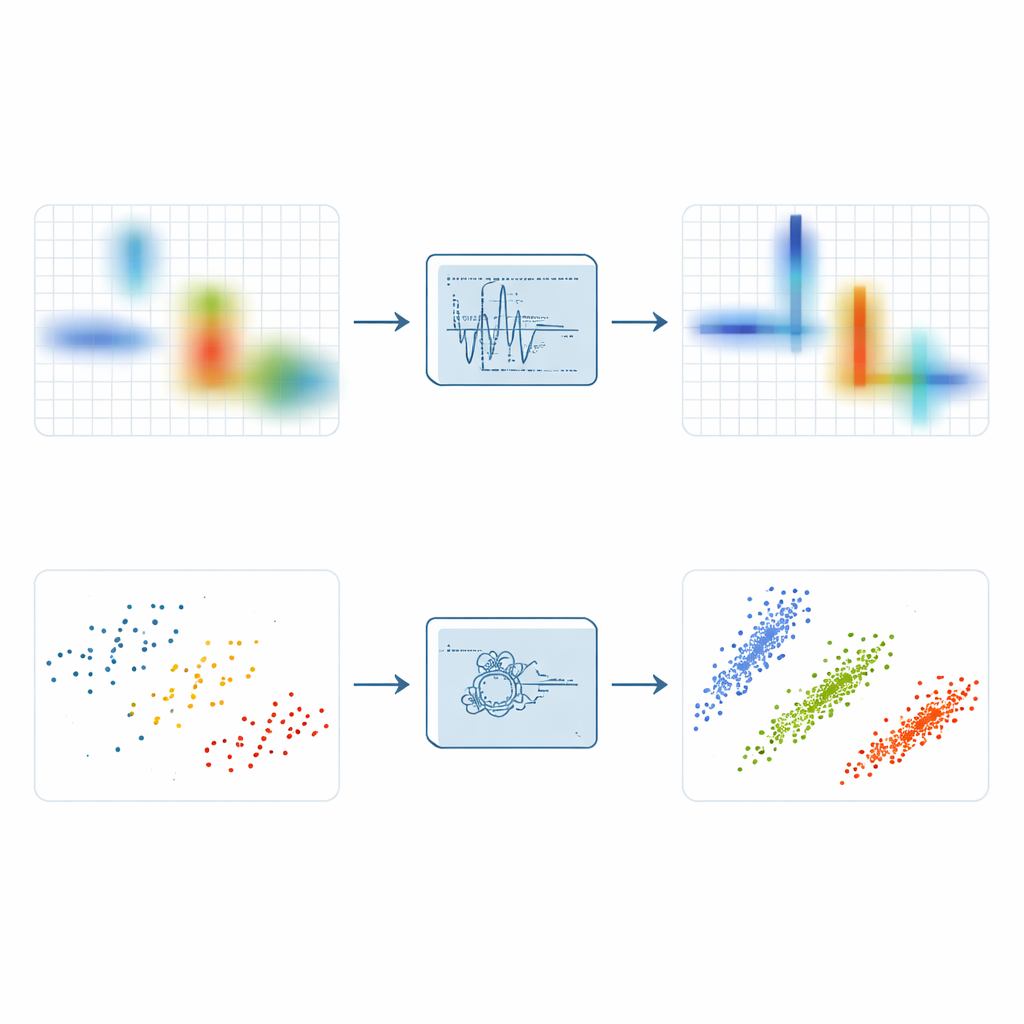
Pourquoi cela compte au-delà de la théorie
Pour les non-spécialistes, la conclusion principale est que les auteurs ont trouvé une meilleure façon d’observer et de regrouper des signaux emmêlés afin que chaque flux d’origine puisse être récupéré plus proprement. En se concentrant sur les maxima locaux dans le paysage temps–fréquence et en associant cette vue à une stratégie de regroupement plus soignée, leur méthode rend le problème du café impossible — de nombreuses voix et trop peu d’oreilles — un peu plus soluble. Cette avancée pourrait profiter à des applications allant des liaisons satellites qui doivent séparer des transmissions superposées, aux systèmes médicaux qui doivent isoler de faibles signaux biologiques enfouis dans le bruit, offrant une information plus claire à partir des mêmes mesures limitées.
Citation: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Mots-clés: séparation aveugle de sources, parcimonie du signal, analyse temps–fréquence, algorithmes de regroupement, communications sans fil