Clear Sky Science · fr
R-GAT : classification de documents sur le cancer exploitant un réseau résiduel basé sur un graphe pour des scénarios à données limitées
Pourquoi trier les articles sur le cancer importe
Chaque jour, des centaines de nouvelles études sur le cancer sont publiées, portant sur la détection précoce jusqu’aux médicaments prometteurs. La plupart de ces travaux paraissent d’abord sous forme de résumés appelés abstracts. Les cliniciens, chercheurs et décideurs ne peuvent pas tous les lire ; manquer un article important peut ralentir les progrès. Cette étude aborde une question simple mais puissante : peut-on concevoir un système informatique rapide et léger qui trie automatiquement les abstracts liés au cancer par type de cancer, même lorsque seules des quantités modestes de données annotées et de puissance de calcul sont disponibles ?
Une manière plus intelligente de lire la recherche sur le cancer
Les auteurs se concentrent sur quatre types d’abstracts issus de la base PubMed : ceux portant sur le cancer de la thyroïde, le cancer du côlon, le cancer du poumon et des sujets biomédicaux plus généraux. Ils ont constitué une collection soigneusement vérifiée de 1 875 abstracts récents, répartis de façon approximativement égale entre ces quatre groupes. Cet équilibre aide à éviter un biais en faveur d’un type de cancer particulier. Avant la modélisation, les textes ont été nettoyés : segmentation en tokens, correction orthographique, fusion des formes apparentées et suppression des termes non informatifs. Les abstracts nettoyés ont ensuite été convertis en formes numériques à l’aide de plusieurs méthodes standard pour permettre une comparaison équitable entre différents modèles.
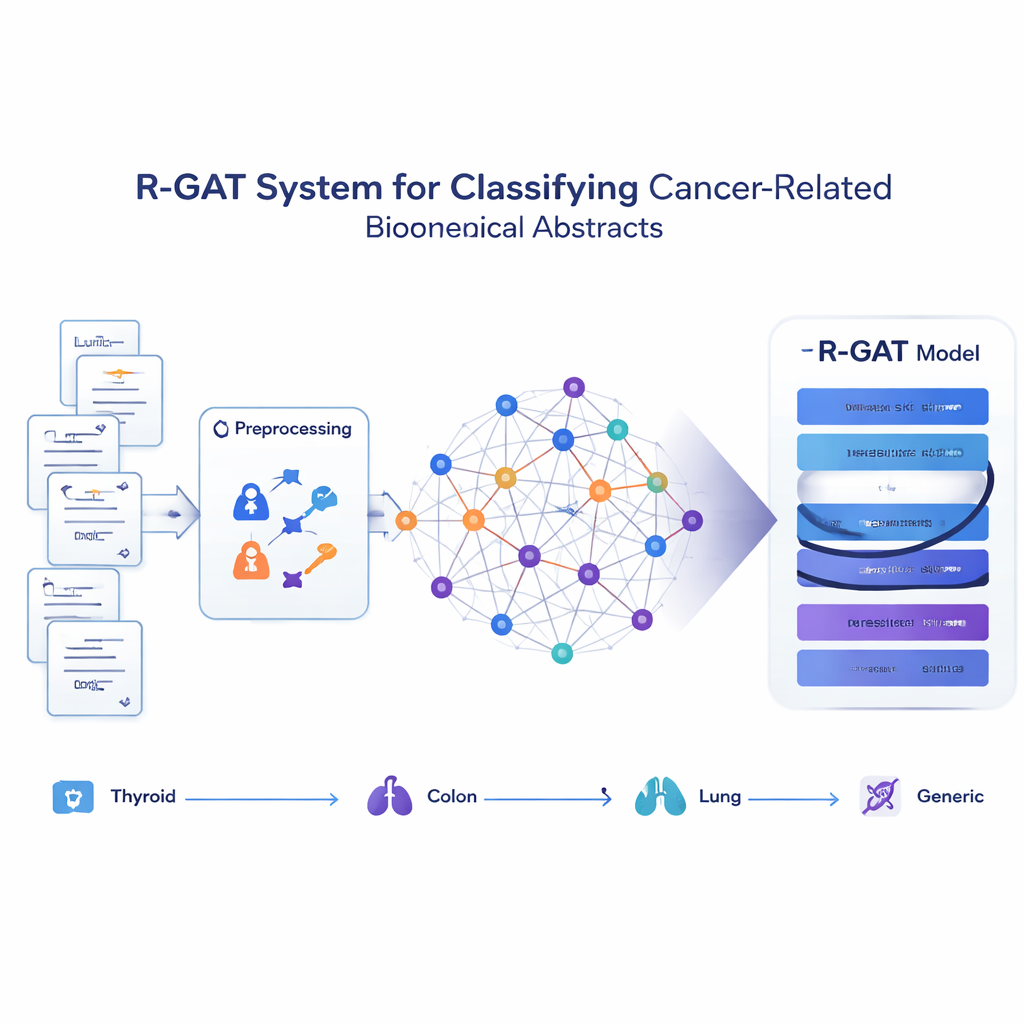
Transformer les articles en réseau d’idées
Plutôt que de traiter chaque abstract comme une chaîne de mots isolée, la méthode proposée, appelée R-GAT (Residual Graph Attention Network), considère l’ensemble de la collection comme un réseau. Dans ce réseau, chaque abstract est un nœud, et les connexions représentent la similarité de contenu entre deux abstracts. Si deux articles traitent de sujets étroitement liés, le lien entre eux est fort ; sinon il est faible ou absent. Cela permet au modèle d’examiner un abstract dans le contexte de ses voisins, imitant la façon dont un lecteur humain comprend mieux une étude en connaissant les travaux connexes.
Comment le nouveau modèle apprend de ses voisins
R-GAT s’appuie sur deux idées clés de l’intelligence artificielle moderne : l’attention et les connexions résiduelles. L’attention permet au modèle de se concentrer davantage sur les abstracts voisins les plus pertinents du réseau, plutôt que de traiter tous les voisins de la même façon. Plusieurs « têtes » d’attention recherchent en parallèle différents types de motifs. Les connexions résiduelles fonctionnent comme des raccourcis qui transmettent l’information à travers les couches profondes du réseau, aidant le modèle à ne pas perdre des signaux importants au fil de l’apprentissage. Après avoir traité le graphe par plusieurs couches d’attention et ces chemins de raccourci, le système condense l’information de tout le réseau en un résumé compact qui est transmis à un classificateur final prédisant laquelle des quatre catégories correspond à chaque abstract.
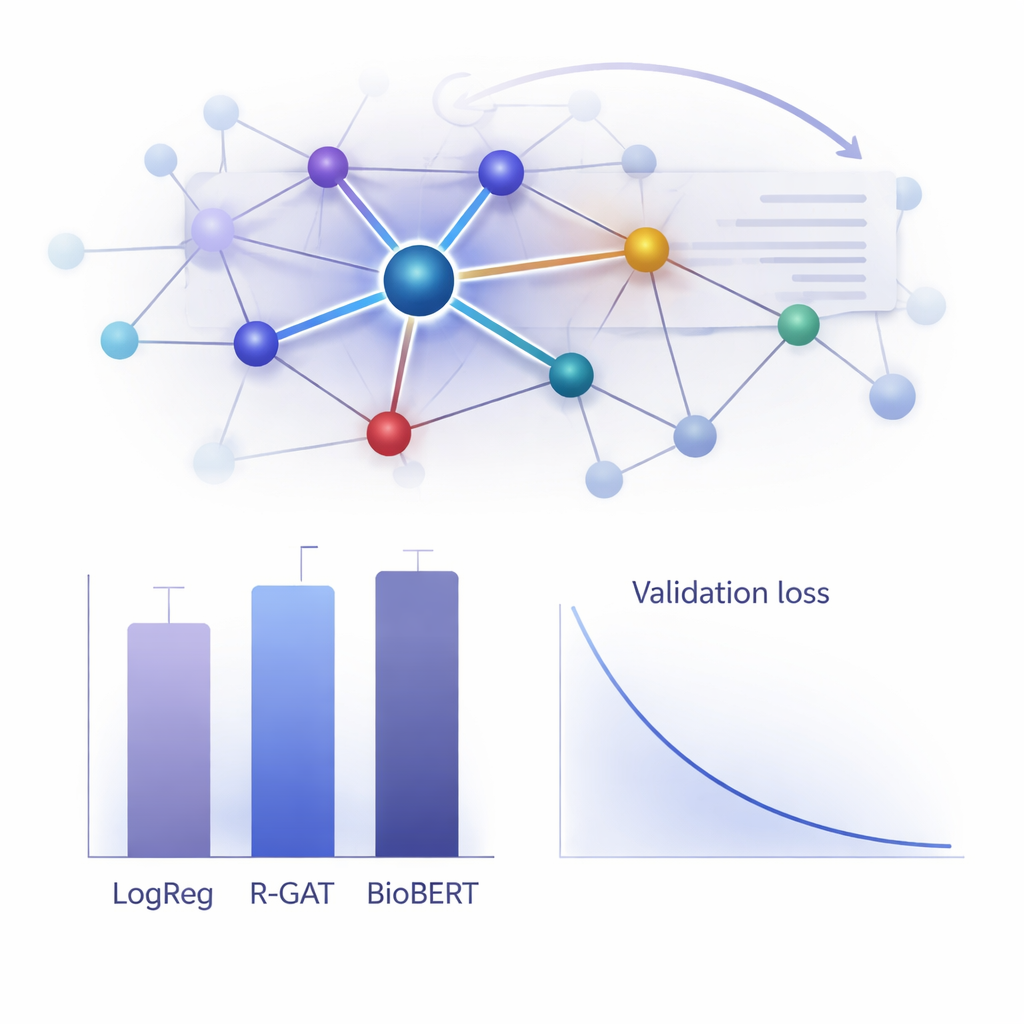
Quelle est son efficacité en pratique ?
Pour évaluer la valeur de R-GAT, les auteurs l’ont comparé à un large éventail d’alternatives, des modèles linéaires classiques aux systèmes transformeurs de pointe comme BioBERT, qui sont populaires mais gourmands en calcul. De manière surprenante, une simple régression logistique utilisant des caractéristiques de compte de mots a obtenu le meilleur score brut sur ce jeu de données particulier, et BioBERT a également très bien performé — mais ces approches présentent des inconvénients, notamment la dépendance à des choix de caractéristiques spécifiques ou le besoin de ressources de calcul importantes. R-GAT a atteint un score macro F1 d’environ 0,96, proche des meilleurs modèles, tout en montrant des résultats très stables sur différentes partitions entraînement–test. Des tests attentionnés où l’on supprimait l’attention ou les connexions résiduelles ont montré des baisses nettes de performance, confirmant que ces deux éléments sont cruciaux pour la robustesse du modèle lorsqu’on dispose de peu de données.
Ce que cela signifie pour la recherche future sur le cancer
Pour un non-spécialiste, la conclusion est simple : R-GAT est un outil pratique qui aide à trier les articles de recherche sur le cancer par type avec une précision élevée et cohérente, sans exiger des jeux de données gigantesques ni du matériel onéreux. Il ne remplace pas les modèles de langage les plus puissants du marché, mais il offre un compromis fiable — particulièrement utile pour les hôpitaux, groupes de recherche ou équipes de santé publique qui ont besoin de résultats reproductibles et robustes dans des conditions de données et de budgets contraints. En publiant à la fois leur modèle et leur jeu de données soigneusement constitué, les auteurs fournissent aussi un banc d’essai partagé que d’autres peuvent utiliser pour construire et tester des systèmes améliorés. À long terme, de tels outils pourraient faciliter la veille des experts sur la littérature relative au cancer et accélérer la traduction des nouvelles découvertes en meilleurs soins.
Citation: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Mots-clés: informatique du cancer, extraction de texte biomédical, classification de documents, réseaux de neurones graphiques, apprentissage avec peu de données