Clear Sky Science · fr
Apprentissage automatique pour prédire les stades de la MRC chez les patients atteints de polykystose rénale autosomique dominante : une cohorte nationale au Japon
Pourquoi cela compte pour la santé quotidienne
La maladie rénale progresse souvent de manière silencieuse, et lorsque les symptômes apparaissent, les lésions peuvent être difficiles à inverser. Pour les personnes nées avec une polykystose rénale autosomique dominante (ADPKD) — une affection où des cavités remplies de liquide remplacent progressivement le tissu rénal normal — connaître la vitesse à laquelle leurs reins peuvent décliner peut influencer des décisions de vie importantes. Cette étude examine si des techniques informatiques modernes, appelées apprentissage automatique, peuvent utiliser des données de bilans médicaux de routine pour prédire comment la fonction rénale d’une personne évoluera au cours des trois prochaines années, sans recourir à des tests génétiques coûteux ou à des examens d’imagerie avancés.
Une maladie fréquente aux trajectoires incertaines
L’ADPKD est l’un des troubles rénaux héréditaires les plus courants et une cause majeure de maladie rénale chronique (MRC). De nombreuses personnes affectées ont finalement besoin d’une dialyse ou d’une transplantation, mais la vitesse de déclin varie largement. Certains progressent lentement et conservent une fonction rénale raisonnable jusqu’à un âge avancé ; d’autres atteignent l’insuffisance rénale dans la quarantaine ou la cinquantaine. Les médecins souhaiteraient classer les patients par risque dès les premiers stades, afin d’adapter le traitement et la surveillance. Les outils de prédiction existants dépendent souvent d’analyses génétiques détaillées ou d’IRM complètes des reins, qui ne sont pas disponibles de façon systématique dans de nombreux systèmes de santé, y compris le régime d’assurance national japonais. Cette lacune a poussé les auteurs à rechercher une méthode plus simple et largement utilisable pour estimer le stade futur de la MRC.
Transformer un registre national en outil de prédiction
Les chercheurs se sont appuyés sur un registre national japonais qui enregistre les informations des personnes atteintes de maladies difficiles à traiter et bénéficiant d’un soutien gouvernemental. Ils ont inclus 2 737 adultes atteints d’ADPKD qui se sont inscrits pour la première fois entre 2015 et 2021. Pour chaque personne, l’équipe a rassemblé les données de la demande initiale — y compris les résultats des analyses de sang, les examens d’urine, des mesures corporelles de base, la tension artérielle et la taille rénale notée par le médecin — puis a examiné le stade de MRC de cette personne trois ans plus tard. Le stade de MRC, principalement basé sur la capacité des reins à filtrer le sang, sert à la fois d’indicateur de gravité de la maladie et de critère clé pour l’aide financière au Japon.
Comment les ordinateurs ont appris à partir des données patients
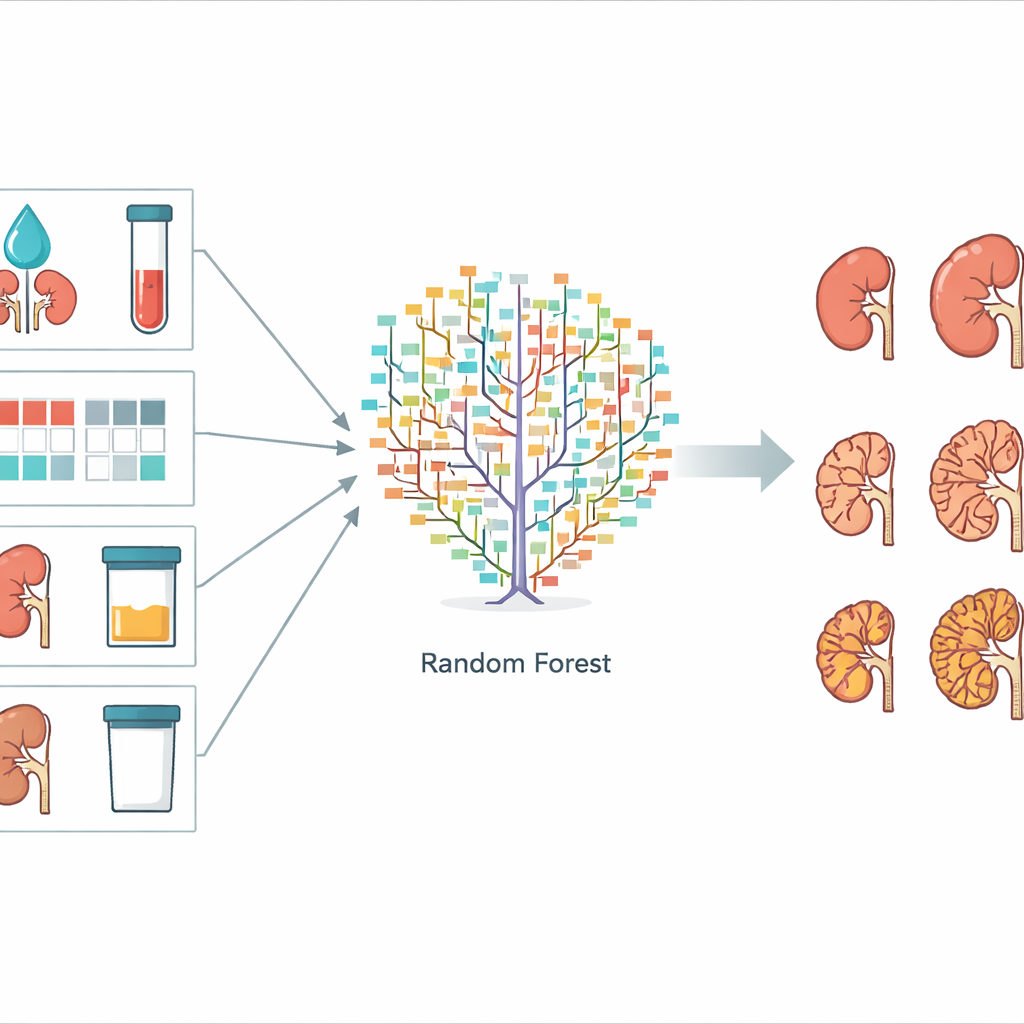
Pour construire leur système de prédiction, les scientifiques ont testé trois méthodes d’apprentissage automatique courantes : forêt aléatoire (random forest), machine à vecteurs de support (support vector machine) et naïve Bayes. Les trois apprennent à partir d’exemples plutôt que de formules fixes. Le jeu de données a été divisé en une partie d’entraînement, utilisée pour ajuster chaque modèle, et une partie de test, utilisée pour vérifier la performance des modèles sur des cas non vus. Les ordinateurs ont tenté de prédire lequel des différents stades de MRC chaque patient atteindrait après trois ans. La méthode de forêt aléatoire, qui combine de nombreux arbres de décision simples en un comité de vote, a montré la meilleure performance, prédisant correctement le stade chez environ 73 % des patients de test. La machine à vecteurs de support, qui suppose principalement des relations linéaires entre facteurs et résultat, a été moins performante, tandis que le modèle naïve Bayes simple se situait entre les deux.
Ce qui a le plus compté pour la prédiction
L’équipe a également cherché à savoir quelles informations étaient les plus utiles pour le modèle de forêt aléatoire. Ils l’ont mesuré en mélangeant (permuttant) un facteur à la fois et en observant dans quelle mesure les prédictions se dégradaient. Cinq caractéristiques se sont démarquées comme particulièrement importantes : le taux de filtration estimé des reins (eGFR), le taux de créatinine sanguine (un autre marqueur de la fonction rénale), une « carte thermique » codée par couleur de la MRC qui combine filtration et présence de protéines dans l’urine, la quantité de protéines dans les urines, et le volume total des deux reins. Ce sont toutes des mesures que l’on peut obtenir lors de consultations ordinaires, sans imagerie spécialisée ni séquençage génétique. D’autres éléments, comme le nombre exact de kystes observés sur les examens, ont peu contribué, ce qui suggère qu’ils ne sont pas essentiels pour un outil de prédiction pratique.
Ce que cela signifie pour les patients et les médecins
Pour les personnes vivant avec l’ADPKD, l’étude suggère qu’un modèle informatique bien entraîné alimenté par des tests de laboratoire standard et des résumés d’imagerie basiques peut fournir une prévision raisonnablement précise de l’état rénal dans trois ans. Parce que le modèle le plus performant peut saisir des relations complexes et non linéaires entre les facteurs, il peut être mieux adapté que les tableaux de risque traditionnels à cette maladie variable et chronique. Bien que le travail soit limité aux patients japonais et ne puisse établir de relations de cause à effet, il ouvre la voie à des outils compatibles avec la pratique clinique pour identifier qui risque de se détériorer rapidement et qui pourrait avoir une évolution plus lente. En termes simples, l’article conclut que l’apprentissage automatique — en particulier l’approche par forêt aléatoire — peut transformer des données médicales de tous les jours en aperçus individualisés de l’avenir rénal, soutenant une prise en charge plus personnalisée et une meilleure planification pour les patients atteints d’ADPKD.
Citation: Shimada, Y., Kataoka, H., Nishio, S. et al. Machine learning for predicting CKD stages in patients with autosomal dominant polycystic kidney disease: a nationwide cohort study in Japan. Sci Rep 16, 8771 (2026). https://doi.org/10.1038/s41598-026-39885-7
Mots-clés: maladie polykystique des reins, maladie rénale chronique, apprentissage automatique, prévision du risque, médecine personnalisée