Clear Sky Science · fr
Un schéma basé sur l’apprentissage automatique pour améliorer la détection des attaques de falsification de position dans les réseaux véhiculaires ad hoc
Des voitures plus intelligentes qui repèrent les tricheurs
Les voitures modernes commencent à communiquer entre elles, avertissant d’un freinage brusque, d’un accident à proximité ou d’une voie obstruée. Ces échanges sans fil peuvent rendre les routes plus sûres, mais uniquement si les informations partagées sont honnêtes. Cette étude aborde un problème sérieux : que se passe-t‑il lorsqu’une voiture ment sur sa position ? Les auteurs montrent comment une forme adaptée d’apprentissage automatique peut repérer les véhicules qui falsifient leur position, rendant les réseaux de voitures connectées plus fiables et susceptible de prévenir des accidents déclenchés par des données erronées.
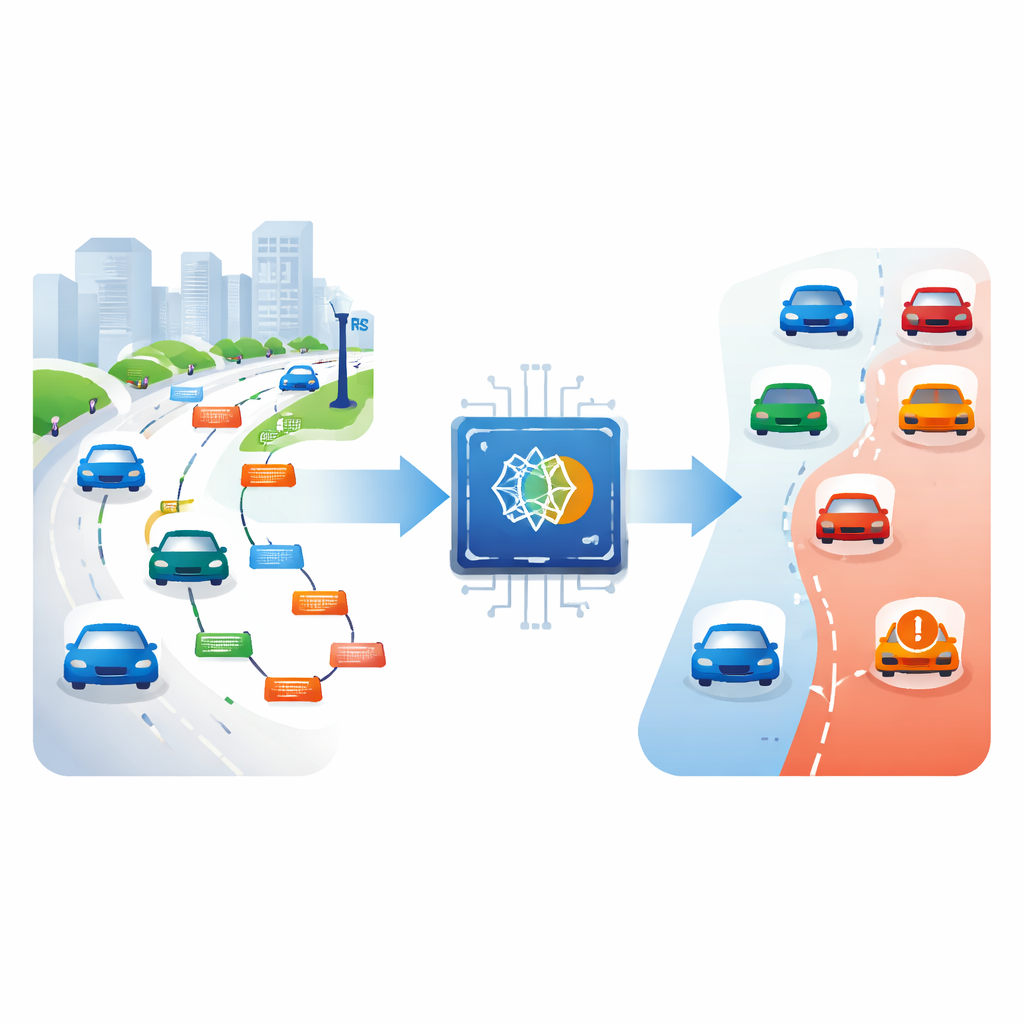
Pourquoi les voitures qui mentent sont si dangereuses
Les véhicules dans les réseaux véhiculaires ad hoc diffusent en permanence de courts messages de sécurité contenant leur position, leur vitesse et leur direction. Les voitures et unités routières voisines utilisent ce flux d’informations pour décider quand avertir les conducteurs ou déclencher des réactions automatiques. Si un véhicule malveillant signale une position falsifiée, il peut induire les autres en erreur : ralentir, changer de voie ou prendre un itinéraire inutile. Dans le pire des cas, il peut empêcher qu’un avertissement de collision soit émis à temps. Comme les véhicules se déplacent vite et que les connexions évoluent en permanence, détecter de tels comportements malveillants est difficile, et les méthodes existantes ratent encore trop d’attaques pour être rassurantes.
Transformer les signaux radio en indice de confiance
L’idée centrale de l’article est de recouper ce qu’un véhicule affirme avec ce que le signal radio révèle discrètement. Chaque message sans fil arrive avec une intensité de signal mesurable. En général, les signaux s’affaiblissent avec la distance, bien que les rues réelles ajoutent du bruit via les réflexions, les bâtiments et la circulation. Plutôt que de convertir naïvement l’intensité en une distance exacte, les auteurs étudient d’abord de nombreux messages honnêtes pour apprendre quelle intensité est attendue à différentes plages. Pour chaque intervalle de distance, ils calculent trois zones emboîtées de valeurs de signal plausibles : une plage de confiance étroite, moyenne et large. Lorsqu’un nouveau message arrive, le système vérifie si son signal se situe dans l’une de ces plages pour la distance déclarée et attribue un score de confiance simple en conséquence, allant de clairement plausible à fortement suspect.
Apprendre à une forêt numérique à repérer les faux
L’intensité du signal seule ne suffit pas, aussi les auteurs combinent ce score de confiance avec d’autres informations simples issues des messages de sécurité — telles que la position et la vitesse déclarées du véhicule, leur évolution dans le temps, et la distance réelle entre l’émetteur et le récepteur. À partir de ces éléments, ils construisent trois jeux alternatifs de caractéristiques (features) et entraînent plusieurs algorithmes d’apprentissage automatique courants sur un jeu de données public qui simule un trafic réaliste et cinq styles de falsification de position. Parmi les modèles testés, une technique appelée forêt aléatoire — essentiellement un comité de vote composé de nombreux arbres de décision simples — associée à un jeu de caractéristiques particulier offrait le meilleur compromis entre précision et rapidité. Elle a identifié correctement presque tous les messages de position falsifiée pour tous les types d’attaque tout en maintenant une charge de calcul suffisamment faible pour une utilisation embarquée dans des véhicules en mouvement.
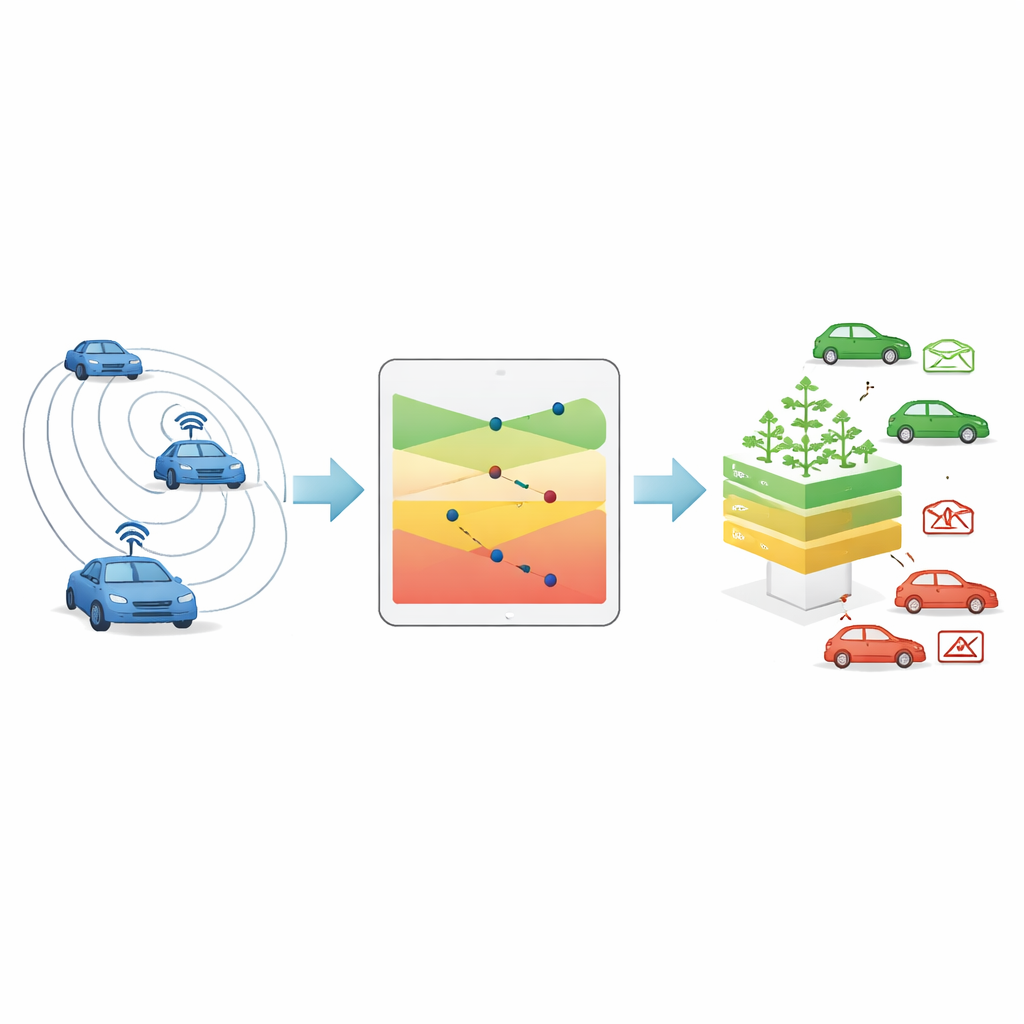
Tester la nouvelle caractéristique
Pour montrer que leur score de confiance basé sur le signal apporte réellement une valeur ajoutée, les chercheurs ont comparé le modèle complet avec une version utilisant exactement les mêmes informations sauf cette nouvelle caractéristique. Évalué sur une simulation distincte qu’il n’avait jamais vue auparavant, le modèle complet est resté nettement plus précis, en particulier pour les attaques où un véhicule continue de diffuser une position fixe fausse ou fait semblant de s’arrêter soudainement. Dans certains de ces cas, l’amélioration d’une mesure de performance clé a été spectaculaire, ce qui signifie que le système a manqué beaucoup moins de messages malveillants sans augmenter excessivement les fausses alertes. Des tests statistiques ont confirmé que la différence entre les deux modèles n’est pas due au hasard.
Ce que cela signifie pour des routes plus sûres
Du point de vue d’un non‑spécialiste, ce travail montre que les voitures peuvent utiliser le comportement naturel des signaux radio comme une vérification indépendante de la réalité des déclarations des véhicules voisins. En intégrant cette vérification dans un modèle d’apprentissage automatique léger exécuté sur chaque voiture, le système peut repérer les véhicules malhonnêtes bien plus fiablement que les méthodes antérieures testées sur la même base de référence. Bien que les résultats proviennent de simulations plutôt que d’essais en conditions réelles, ils suggèrent une voie claire vers des réseaux de trafic plus intelligents et autonomes où même de petits gains dans la détection des comportements malveillants pourraient se traduire par des vies sauvées.
Citation: Abdelkreem, E., Hussein, S. & Tammam, A. A machine learning based scheme for enhancing the detection of position falsification attacks in vehicular ad hoc networks. Sci Rep 16, 8950 (2026). https://doi.org/10.1038/s41598-026-39867-9
Mots-clés: véhicules connectés, sécurité routière sans fil, sécurité de l’apprentissage automatique, usurpation de localisation, réseaux véhiculaire