Clear Sky Science · fr
Intégrer la validation croisée dans le monde réel pour évaluer la transférabilité des modèles de végétation basés sur satellite
Pourquoi observer l'herbe depuis l'espace compte
Les prairies nourrissent le bétail, soutiennent la faune et stockent du carbone, et de nombreux éleveurs et défenseurs de la nature se fient aujourd'hui aux satellites pour suivre la quantité de matière végétale présente au sol. De nouvelles cartes promettent des vues quasi temps réel des conditions des pâturages, mais leur précision lors d'années atypiques — comme des sécheresses profondes ou des saisons très humides — est souvent acceptée sans preuve. Cette étude pose une question simple mais cruciale : dans quelle mesure les modèles informatiques à l'origine de ces cartes satellitaires tiennent-ils la distance quand le monde réel refuse de ressembler aux données sur lesquelles ils ont été entraînés ?
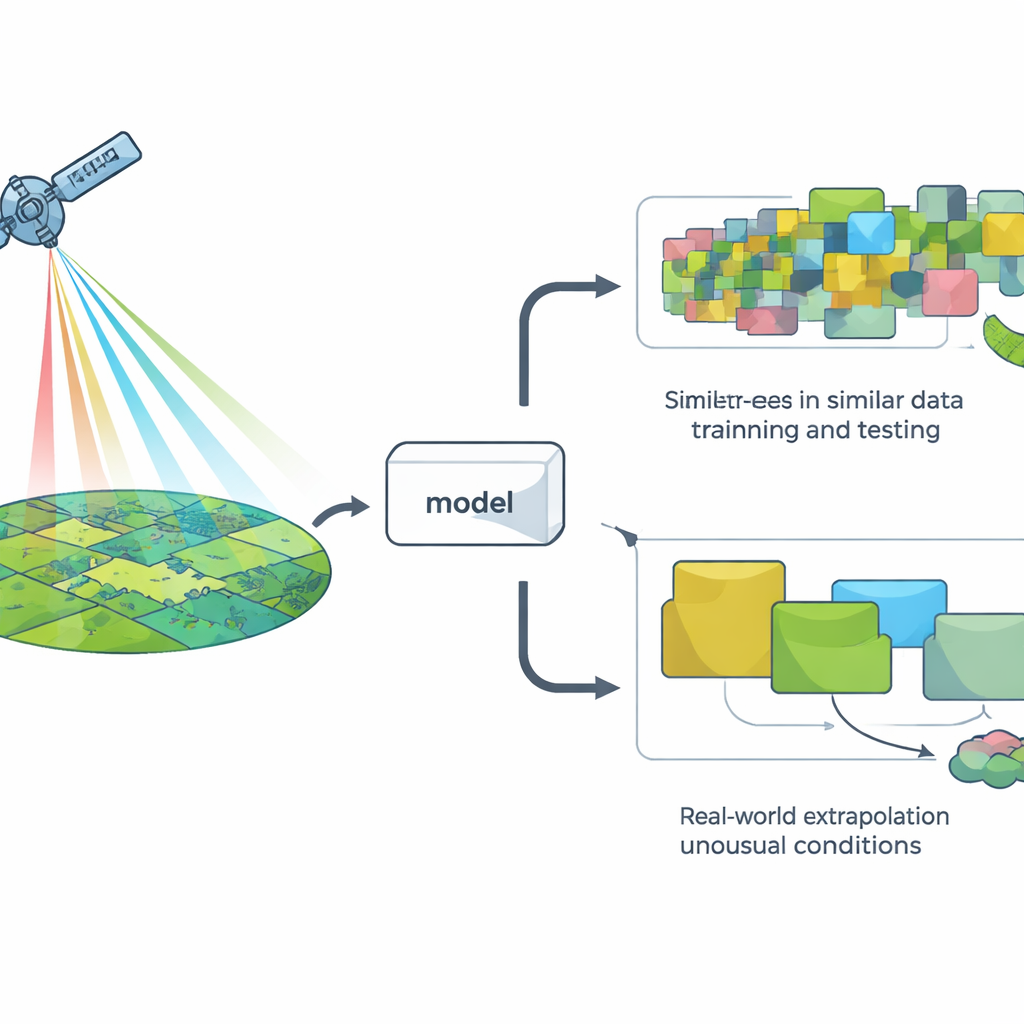
Évaluer les modèles à la manière facile versus à la manière difficile
Pour juger un modèle, les chercheurs utilisent généralement une méthode appelée validation croisée : ils cachent certaines données, entraînent le modèle sur le reste, puis vérifient la qualité des prédictions sur les points cachés. La version la plus courante sépare les données de façon aléatoire, ce qui convient à de nombreux problèmes mais suppose implicitement que toutes les observations sont indépendantes. Dans les paysages, cette hypothèse échoue souvent : les lieux proches et les années voisines se ressemblent depuis l'espace. Par conséquent, les séparations aléatoires peuvent donner l'illusion qu'un modèle affronte des situations « nouvelles » alors qu'en réalité il voit surtout plus de la même chose.
Soumettre les modèles satellites à des tests du monde réel
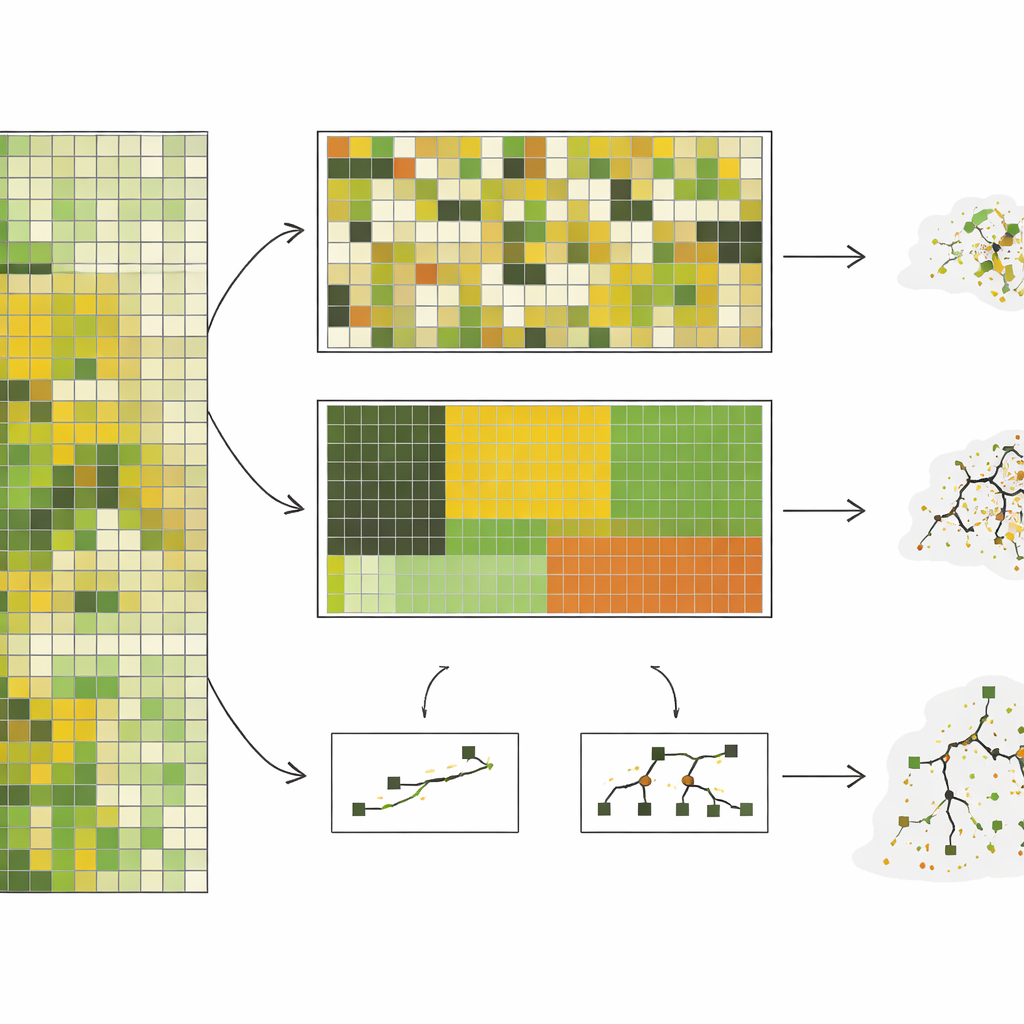
Les auteurs ont rassemblé près de 10 000 mesures de terrain de la biomasse herbacée debout — essentiellement la quantité de matière végétale pâturable — provenant d'une steppe à herbe courte du Colorado, collectées sur dix ans. Ils ont associé ces mesures à des images satellitaires détaillées puis entraîné sept types de modèles informatiques différents, allant d'approches linéaires simples à des systèmes complexes d'arbres de décision. Plutôt que de s'en tenir aux séparations aléatoires, ils ont testé cinq façons de mettre des données de côté : par parcelles choisies aléatoirement, par blocs de pâturage, par type de site écologique, par année et par groupes de pixels spectrales distincts. Ces deux dernières approches, en particulier le regroupement par année et par clusters spectraux, ont forcé les modèles à prédire des conditions réellement différentes de celles qu'ils avaient vues auparavant.
Quand le futur ne ressemble pas au passé
De manière générale, les performances des modèles ont chuté fortement à mesure que les tests devenaient plus exigeants. Avec la séparation aléatoire, des modèles complexes comme les forêts aléatoires paraissaient impressionnants, expliquant environ les trois quarts de la variance de la biomasse. Mais lorsqu'on leur a demandé de prédire pour une année entièrement inconnue — une tâche réaliste pour une surveillance quasi temps réel — leur précision a diminué, et des modèles relativement simples basés sur une poignée de variables satellitaires combinées ont fait aussi bien voire mieux. Dans le test le plus extrême, où les données étaient regroupées pour être aussi différentes que possible les unes des autres, la précision des modèles complexes s'est effondrée, tandis que les meilleurs modèles simples ont conservé des performances modérées et plus prévisibles. L'étude montre aussi que les modèles complexes sont très sensibles à la présence de conditions rares, comme des sécheresses sévères, dans les données d'entraînement, et peuvent parfois très mal performer dans ces scénarios à forts enjeux.
Des chevaux de trait stables valent mieux que des sprinters tape-à-l'œil
Au-delà de la précision brute, l'équipe a examiné la consistance de chaque modèle lorsqu'il était réentraîné avec des sous-ensembles d'années légèrement différents. Les méthodes plus simples, en particulier la régression par moindres carrés partiels (PLS), avaient tendance à identifier les mêmes signaux satellitaires clés à répétition, nécessitaient peu d'options d'ajustement et produisaient des résultats plus stables d'une année sur l'autre. Les approches plus complexes changeaient souvent les entrées sur lesquelles elles s'appuyaient, exigeaient de nombreux réglages et manifestaient de grandes variations de performance d'un entraînement à l'autre. Pour les gestionnaires de terres qui doivent mettre à jour les cartes chaque année au fur et à mesure de l'arrivée de nouvelles données, ce type de stabilité peut être tout aussi important que la précision maximale obtenue lors d'une année favorable.
Ce que cela signifie pour l'utilisation des cartes satellitaires sur le terrain
Pour les personnes qui dépendent des cartes de végétation basées sur satellite pour décider quand et où faire paître le bétail, réagir à la sécheresse ou suivre la santé des écosystèmes, cette étude délivre un message clair. Les habitudes courantes de test qui mélangent les données au hasard peuvent peindre un tableau trop optimiste de la performance d'un modèle lorsque la météo bascule vers des extrêmes ou lorsqu'il est appliqué dans de nouveaux lieux. Quand les modèles sont évalués de manières qui imitent leur usage réel — prédire pour de nouvelles années, de nouveaux contextes écologiques ou des conditions rarement observées — des méthodes simples et bien comportées peuvent surpasser des approches sophistiquées et fournir des indications plus fiables. En pratique, cela signifie que les développeurs devraient indiquer comment leurs modèles résistent à plusieurs tests plus stricts et plus réalistes, et que les utilisateurs devraient privilégier des produits dont la performance a été vérifiée dans les types de situations difficiles qu'ils sont le plus susceptibles de rencontrer.
Citation: Kearney, S.P., Augustine, D.J., Porensky, L.M. et al. Bringing cross-validation into the real world to evaluate transferability of satellite-based vegetation models. Sci Rep 16, 9383 (2026). https://doi.org/10.1038/s41598-026-39866-w
Mots-clés: cartographie de la végétation par satellite, validation croisée, biomasse des prairies, modèles d'apprentissage automatique, suivi de la sécheresse