Clear Sky Science · fr
Reconnaissance de lieux robuste aux variations d’éclairage utilisant du pseudo-LiDAR issu d’images omnidirectionnelles
Des robots qui ne se perdent jamais dans le noir
Imaginez un robot capable de reconnaître sa position dans un bâtiment, que ce soit en plein jour avec le soleil qui traverse les fenêtres ou tard la nuit avec seulement quelques lampes allumées. Cet article présente une nouvelle méthode pour doter les robots d’un sens du lieu fiable en n’utilisant qu’une seule caméra relativement bon marché. En transformant des images plates en informations 3D, les chercheurs rendent la navigation robotique beaucoup moins sensible aux ombres, à l’éblouissement et aux autres variations d’éclairage qui perturbent habituellement les systèmes basés sur la vision.
Pourquoi reconnaître deux fois le même endroit est difficile
Pour un robot, la « reconnaissance de lieu » signifie se dire « je suis déjà venu ici », afin de se localiser sur une carte et naviguer en toute sécurité. Les systèmes traditionnels s’appuient soit sur des caméras classiques, soit sur des capteurs de distance à base de laser appelés LiDAR. Les caméras sont peu coûteuses et capturent des informations riches en couleur et texture, mais leur apparence varie fortement entre ciel couvert, plein soleil et nuit. Le LiDAR est beaucoup plus stable car il mesure directement les distances, mais il est encombrant et coûteux. Certains robots combinent plusieurs capteurs, ce qui augmente le prix et la complexité. Les auteurs de ce travail empruntent une voie différente : ils conservent un matériel simple, n’utilisant qu’une caméra omnidirectionnelle qui voit tout autour du robot, et améliorent le logiciel pour que le robot raisonne en termes de structure 3D plutôt qu’en apparence brute.
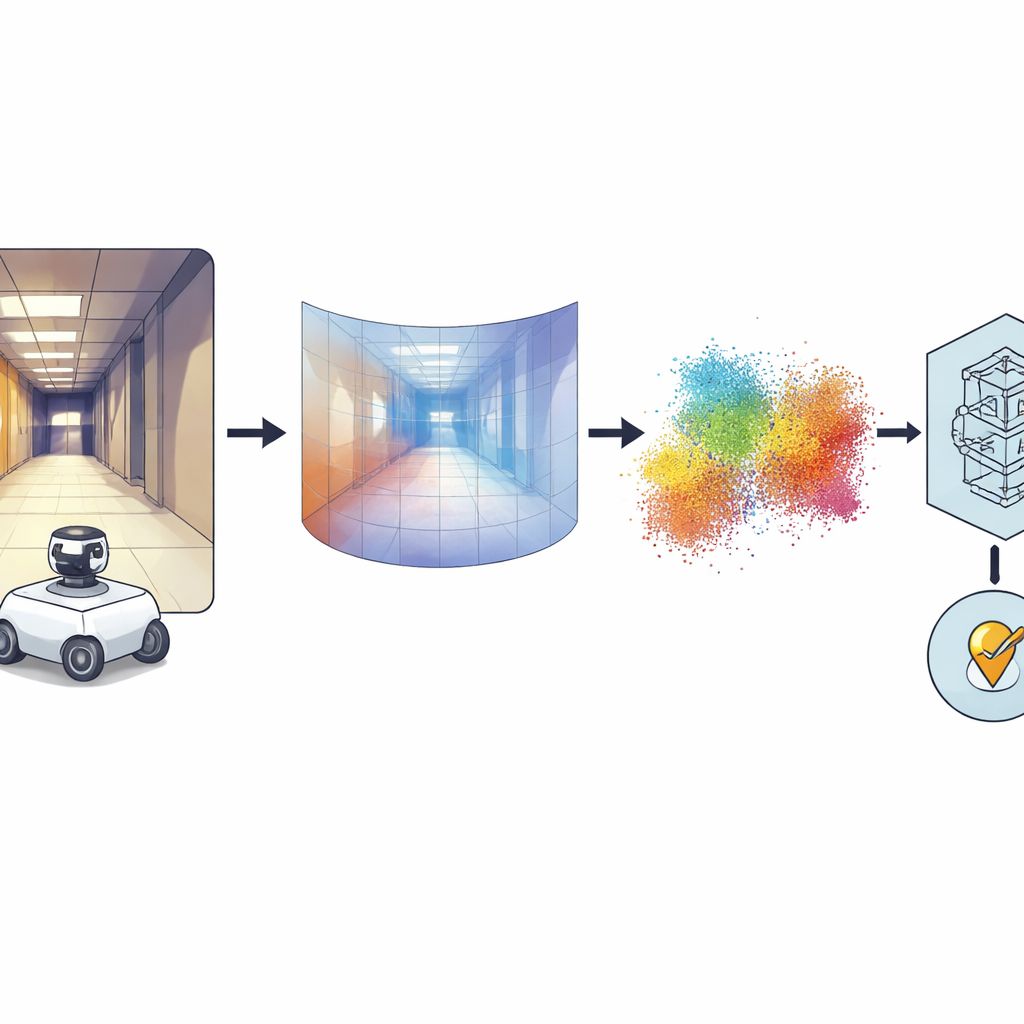
Des photos tout autour vers des formes 3D
L’idée clé est de convertir chaque image panoramique en une carte dense de profondeur, où chaque pixel encode la distance de cette partie de la scène par rapport à la caméra. Pour cela, les auteurs s’appuient sur un puissant modèle « fondation » nommé Distill Any Depth, entraîné à déduire la profondeur à partir d’énormes collections d’images. La carte de profondeur résultante est ensuite transformée en un nuage de points 3D — une sorte de LiDAR virtuel, ou pseudo-LiDAR — sans nécessité de scanner laser réel. Un traitement additionnel corrige les artefacts introduits par le miroir spécial utilisé pour la caméra à 360 degrés, de sorte que les régions manquantes ou occultées sont comblées. Enfin, un réseau de neurones appelé MinkUNeXt, conçu pour fonctionner directement sur des nuages de points 3D, compresse chaque nuage en une empreinte compacte qui capture l’agencement global du lieu.
Apprendre au système à ignorer les tours de passe-passe lumineux
Les estimations de profondeur ne sont pas parfaites, en particulier lorsque l’éclairage change fortement d’un instant à l’autre. Pour rendre le système robuste, les chercheurs introduisent une astuce d’entraînement qu’ils appellent Distilled Depth Variations. Plutôt que de se fier à un unique modèle de profondeur, ils mélangent délibérément des prédictions de profondeur provenant de plusieurs versions plus petites et moins précises de l’estimateur. Ce « bruit » contrôlé imite les types de distorsions qui apparaissent sous différentes conditions d’éclairage, forçant le réseau 3D à apprendre ce qui compte réellement dans la géométrie d’un lieu et ce qui peut être ignoré en toute sécurité. Ils enrichissent également chaque point 3D avec des informations sur les contours et la force de texture de l’image — des caractéristiques qui tendent à être plus stables face aux variations d’éclairage que la couleur brute.
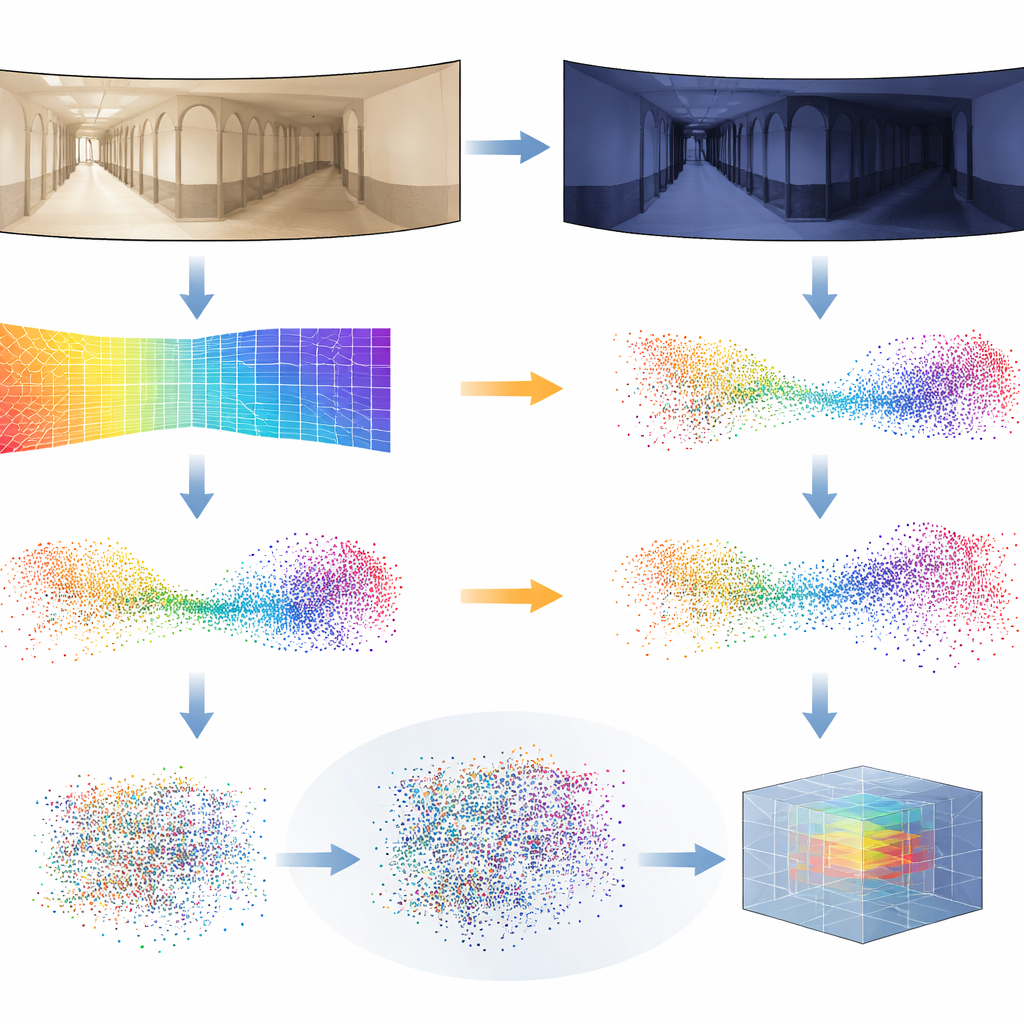
Une validation sur des scénarios réels
Pour tester leur approche, l’équipe s’est tournée vers des jeux de données publics exigeants d’itinéraires de robots en intérieur. Dans ces collections, un robot parcourt couloirs et pièces plusieurs fois sous ciel couvert, plein soleil et la nuit, tandis que meubles et personnes se déplacent. Les auteurs ont entraîné leur système en n’utilisant que des images prises par temps couvert dans un seul bâtiment, puis l’ont évalué sur l’ensemble des bâtiments et conditions d’éclairage, y compris des scènes inconnues. Leur méthode pseudo-LiDAR a systématiquement égalé ou surpassé des techniques 2D basées sur l’image et d’autres systèmes 3D, surtout dans les cas les plus difficiles comme les parcours nocturnes ou le transfert vers des environnements totalement nouveaux. Ils ont aussi montré que le même pipeline fonctionne avec des caméras frontales ordinaires, pas seulement panoramiques, en remplaçant la projection appropriée de la profondeur vers la 3D.
Ce que cela signifie pour les robots futurs
Concrètement, ce travail montre qu’un robot peut acquérir une conscience de son environnement proche d’un LiDAR en n’utilisant qu’une seule caméra et un logiciel astucieux. En se concentrant sur la structure 3D plutôt que sur les détails instables d’éclairage et de couleur, le système peut reconnaître des lieux de façon fiable de jour comme de nuit et par différents temps, tout en conservant un matériel simple et abordable. Cela pourrait rendre la navigation intérieure robuste plus accessible pour les robots de service, les véhicules d’entrepôt et les dispositifs d’assistance, et ouvre la voie à des systèmes futurs qui mêleraient profondeur et compréhension de scène de plus haut niveau pour une autonomie encore plus fiable.
Citation: Cabrera, J.J., Alfaro, M., Gil, A. et al. Robust place recognition under illumination changes using pseudo-LiDAR from omnidirectional images. Sci Rep 16, 8817 (2026). https://doi.org/10.1038/s41598-026-39848-y
Mots-clés: localisation de robot, vision 3D, reconnaissance de lieu, estimation de profondeur, caméras omnidirectionnelles