Clear Sky Science · fr
Architecture à microservices fédérée avec blockchain pour des analyses de santé évolutives et respectueuses de la vie privée
Pourquoi vos données de santé ont besoin d’une protection plus intelligente
Chaque visite à la clinique, chaque prise de sang et chaque relevé d’une montre connectée alimentent une montagne croissante de données de santé. Ces informations pourraient aider les médecins à détecter des maladies plus tôt et à personnaliser les traitements, mais elles sont dispersées entre hôpitaux et appareils et protégées par des règles strictes de confidentialité. Cet article explore une nouvelle manière d’exploiter la puissance de ces données sans en provoquer de fuite, en combinant trois idées modernes de l’informatique dans une feuille de route pratique pour les hôpitaux.
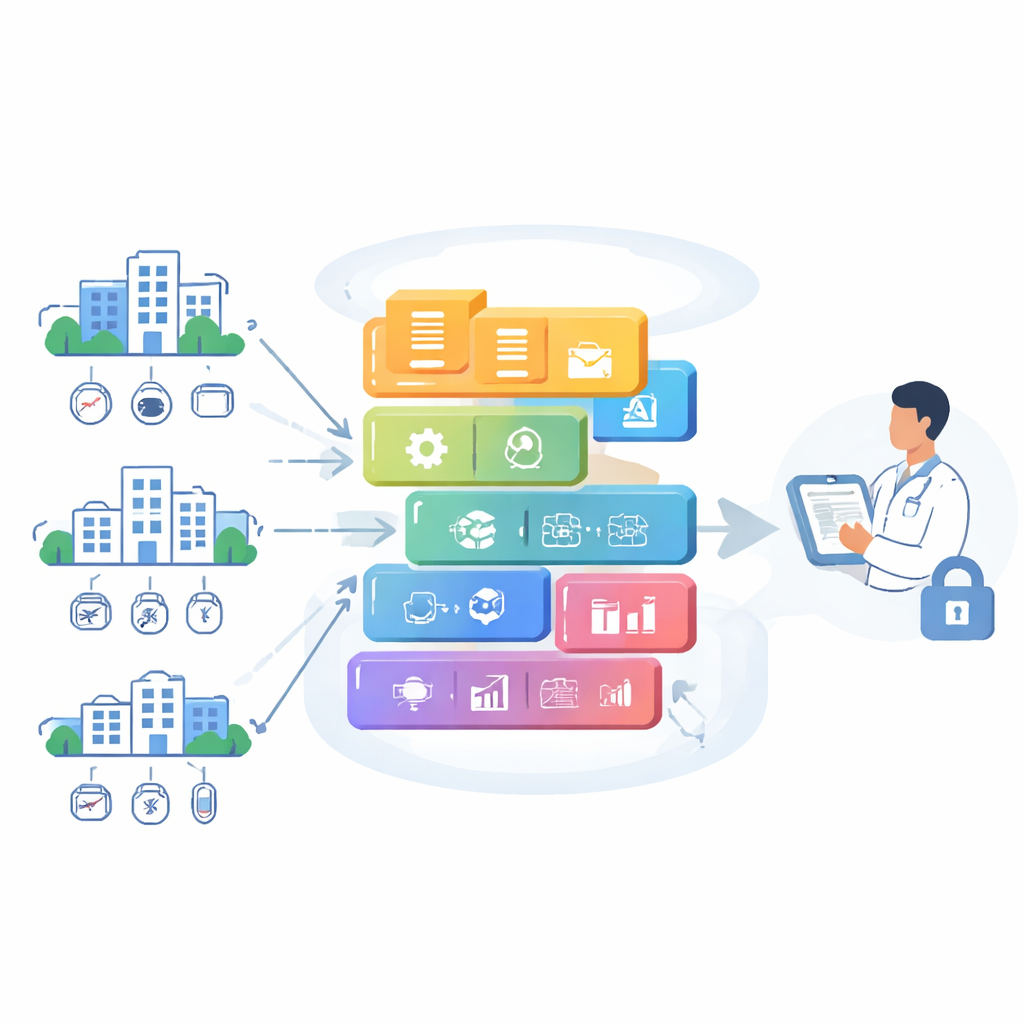
Découper l’ordinateur de l’hôpital en blocs plus petits
La plupart des hôpitaux s’appuient encore sur de gros systèmes tout-en-un qui gèrent tout, du stockage des dossiers aux outils de prédiction. Ces architectures « boîte unique » sont difficiles à faire évoluer, lentes à mettre à jour et risquées en cas de panne ou de piratage. Les auteurs proposent plutôt de fragmenter le système en nombreux services petits et ciblés, chacun accomplissant une tâche unique, comme nettoyer les données entrantes, exécuter un modèle prédictif ou fournir un tableau de bord web. Ces services s’exécutent dans des conteneurs et sont pilotés par une plateforme d’orchestration capable de les démarrer, arrêter ou dupliquer à la demande. Cela permet au système de croître harmonieusement à mesure que s’ajoutent patients et cliniques, et isole les problèmes afin qu’une défaillance dans une partie n’entraîne pas l’effondrement de tout le réseau.
Former des modèles prédictifs partagés sans partager les données brutes
Un défi majeur en médecine est que chaque hôpital ne détient qu’une vue partielle de la population, et simplement regrouper tous les dossiers dans une base de données unique enfreint de nombreuses règles de confidentialité. L’article utilise l’apprentissage fédéré pour contourner ce problème. Dans ce dispositif, le modèle prédictif se déplace vers chaque hôpital, apprend à partir des dossiers locaux et renvoie uniquement des mises à jour mathématiques plutôt que des noms, résultats de laboratoire ou notes cliniques. Un coordinateur central agrège ces mises à jour en un modèle global renforcé et le renvoie pour la prochaine itération. Des protections supplémentaires, comme l’ajout de bruit soigneusement calibré et le chiffrement des mises à jour, rendent très difficile pour un attaquant de reconstituer des informations individuelles sur des patients à partir de ces messages.
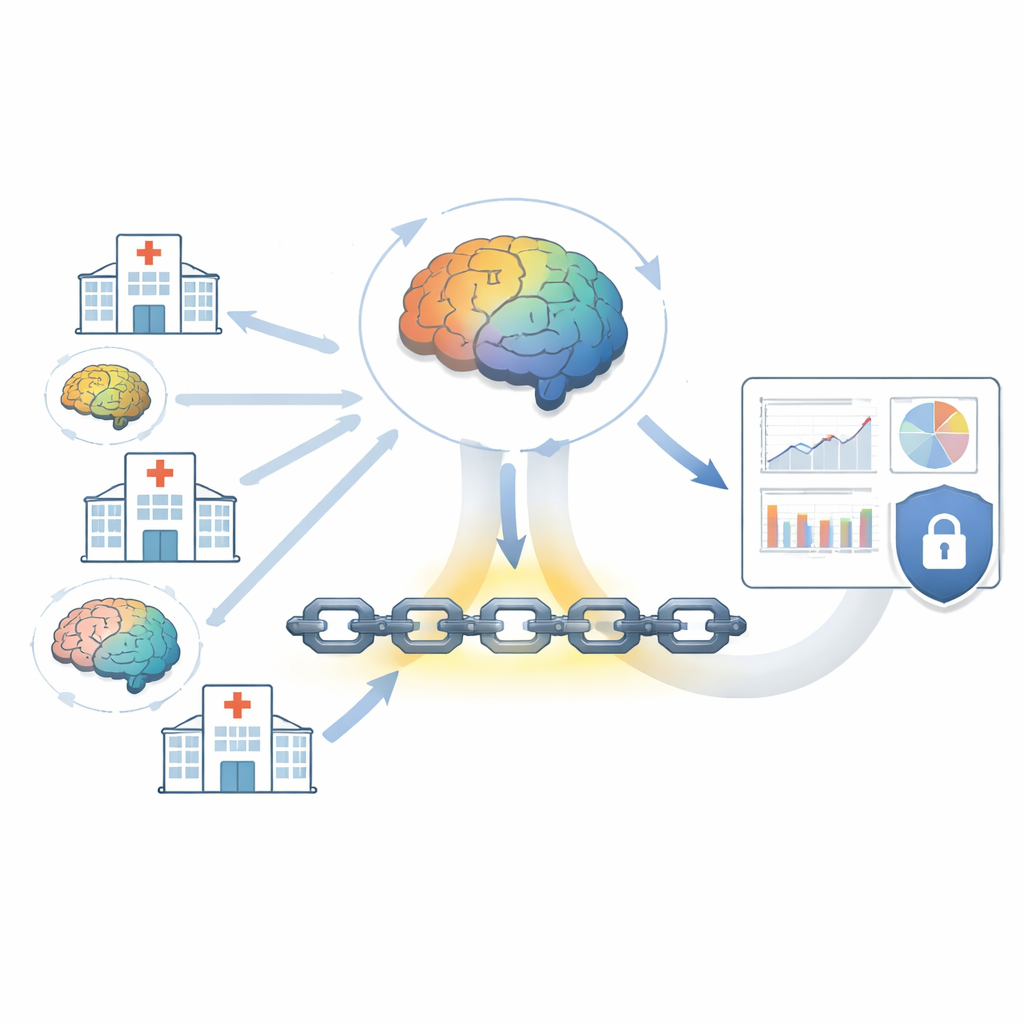
Verrouiller la trace des actions sur un registre infalsifiable
Les lois modernes sur la confidentialité s’intéressent non seulement à qui accède aux données, mais aussi à la preuve de ce qui s’est passé et quand. Pour répondre à cette exigence, le cadre enregistre les événements importants — comme la mise à jour d’un modèle ou la réalisation d’une prédiction — sur une blockchain permissionnée. Il s’agit d’un registre numérique partagé où seules des parties approuvées peuvent écrire, et une fois qu’une entrée est ajoutée, elle ne peut pas être modifiée en catimini. Des règles de contrôle « intelligentes » sur ce registre vérifient que les mises à jour de modèles entrantes sont valides et que les règles d’accès sont respectées. Si quelqu’un tente d’insérer une mise à jour falsifiée ou de rejouer une ancienne, le désaccord est détecté et bloqué, fournissant une piste d’audit solide pour les régulateurs et les équipes de conformité des hôpitaux.
Mettre le système à l’épreuve avec des patients réels et simulés
Pour vérifier si ce design dépasse la théorie, les auteurs ont construit un système complet et l’ont testé sur deux types de données. L’un était un grand ensemble d’enregistrements patients générés par ordinateur destiné à imiter le trafic réel des hôpitaux ; l’autre était une collection réelle de dossiers de patients traités pour le diabète dans plus d’une centaine d’hôpitaux américains. Leur objectif était de prédire qui développerait un diabète de type 2 dans les six mois. L’architecture combinée a atteint environ 95 % de précision, surpassant à la fois un modèle centralisé traditionnel entraîné sur des données regroupées et des modèles séparés entraînés isolément dans chaque hôpital. Parallèlement, la structure en microservices a réduit les temps de réponse de près de moitié et a permis au système de se rétablir des pannes environ dix fois plus rapidement qu’un ancien design monolithique.
Ce que cela pourrait signifier pour les soins futurs
Pris ensemble, ces résultats suggèrent que les hôpitaux n’ont pas à choisir entre analyses puissantes et forte confidentialité. En divisant le logiciel en modules, en laissant les modèles apprendre là où résident les données et en enregistrant chaque étape importante sur un registre résistant à la falsification, l’approche proposée offre des prédictions plus rapides, une meilleure précision, moins d’interruptions système et aucune brèche de données réussie lors d’attaques simulées. Pour les patients, cela pourrait se traduire par des alertes plus précoces pour des affections comme le diabète sans que leurs dossiers personnels ne quittent jamais leurs institutions d’origine. Pour les systèmes de santé, cela fournit une feuille de route vers des outils numériques plus intelligents et dignes de confiance, capables de s’étendre aux régions et aux pays tout en respectant des règles strictes de confidentialité et de sécurité.
Citation: Harshith, M., Ansari, Z.A., Fatima, S. et al. Federated microservices architecture with blockchain for privacy-preserving and scalable healthcare analytics. Sci Rep 16, 9023 (2026). https://doi.org/10.1038/s41598-026-39837-1
Mots-clés: analyse de la santé, apprentissage fédéré, microservices, blockchain, confidentialité des patients