Clear Sky Science · fr
AsynDBT : réglage bilinéaire distribué asynchrone pour un apprentissage en contexte efficace avec de grands modèles de langage
Pourquoi des invites plus intelligentes comptent pour l’IA au quotidien
Les grands modèles de langage alimentent désormais des chatbots, des moteurs de recherche et des assistants de rédaction que beaucoup de personnes utilisent quotidiennement. Pourtant, obtenir des réponses utiles dépend encore fortement de la façon dont nous formulons nos questions et des exemples que nous montrons au modèle. Cet article présente une nouvelle méthode pour affiner automatiquement ces invites et exemples à travers de nombreux dispositifs, tout en conservant la confidentialité des données de chaque utilisateur. Le résultat est un système d’IA qui apprend à répondre de manière plus précise et efficace, en particulier sur des tâches spécialisées comme la maintenance de réseaux télécom.
Enseigner à l’IA en montrant, sans la réentraîner
Plutôt que de réentraîner en permanence des modèles gigantesques, une tendance croissante consiste à les instruire « sur le moment » en fournissant quelques exemples soigneusement choisis dans l’invite — un processus appelé apprentissage en contexte. Par exemple, pour classer des critiques de films en positives ou négatives, on peut montrer au modèle un petit ensemble d’exemples étiquetés puis lui demander de catégoriser une nouvelle critique. Le problème est que le choix des exemples et la formulation exacte des consignes peuvent modifier considérablement les performances du modèle. Trouver de bonnes combinaisons manuellement est lent et coûteux, et le partage de données brutes entre organisations est souvent impossible pour des raisons de confidentialité.
Coopérer sans partager de données privées
Pour contourner les barrières au partage de données, les auteurs s’appuient sur l’apprentissage fédéré, une configuration où de nombreux dispositifs ou organisations conservent leurs données localement mais collaborent via un serveur central. Chaque participant — par exemple une station de base télécom ou un serveur d’entreprise — interagit avec le même modèle de langage cloud, sans jamais téléverser ses textes bruts. Il renvoie uniquement des signaux de rétroaction sur l’efficacité de différentes invites et sélections d’exemples. Un nouvel algorithme appelé AsynDBT (asynchronous distributed bilevel tuning) coordonne ces participants afin qu’ils améliorent collectivement une stratégie d’invite partagée tout en respectant la confidentialité et en s’accommodant des connexions lentes ou instables.
Optimiser à la fois la consigne et les exemples
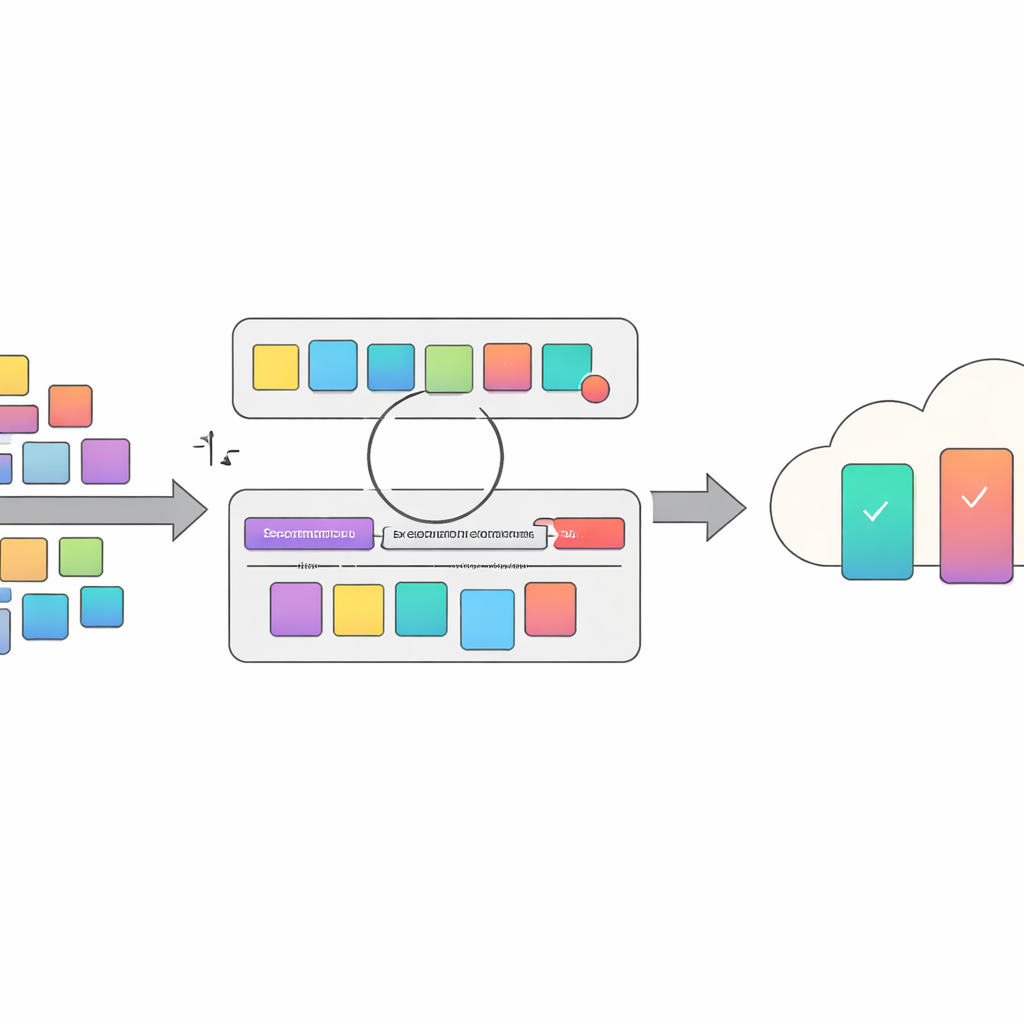
Une idée clé de l’article est de considérer la conception d’invites comme un problème d’optimisation à deux niveaux. Au niveau inférieur, le système ajuste de courts fragments qui s’ajoutent à la consigne de tâche — de petits changements de formulation qui peuvent orienter le raisonnement du modèle. Au niveau supérieur, il décide quels exemples étiquetés inclure comme démonstrations. Ces deux niveaux interagissent : différents ensembles d’exemples exigent différents ajustements de l’invite, et inversement. AsynDBT formalise cette relation mathématiquement et utilise une méthode d’approximation efficace pour que chaque participant puisse mettre à jour progressivement ses choix locaux pendant qu’un serveur central conserve une vue globale cohérente des décisions du niveau inférieur.
Gérer les dispositifs lents et les participants malveillants
Dans les réseaux réels, certains dispositifs répondent en retard ou se déconnectent, créant des « retardataires » qui peuvent bloquer un entraînement synchronisé classique. AsynDBT fonctionne donc de manière asynchrone : le serveur met à jour ses variables dès qu’un sous-ensemble de participants a répondu, sans attendre tout le monde. La méthode protège aussi contre des participants susceptibles d’envoyer des mises à jour trompeuses, intentionnellement ou par erreur. En combinant des techniques de régularisation avec des règles d’agrégation robustes, l’algorithme réduit l’impact de sélections d’exemples empoisonnées ou de faible qualité sur la stratégie globale, aidant le système à rester stable et fiable même en cas d’attaque.
Gains démontrés sur des tâches linguistiques et télécom
Les chercheurs ont testé AsynDBT sur six problèmes de classification de texte, y compris un jeu de données exigeant pour les réseaux 5G où le modèle devait juger si des termes techniques spécialisés étaient liés, en utilisant uniquement des fragments de normes télécom pour contexte. Comparée à plusieurs méthodes existantes d’invite et de sélection d’exemples, la nouvelle approche a obtenu la meilleure ou la deuxième meilleure précision sur presque toutes les tâches. Sur la tâche 5G en particulier, elle a amélioré la précision d’environ dix points de pourcentage par rapport au meilleur point de comparaison. Parallèlement, le design asynchrone a réduit le temps d’entraînement d’environ 40 % par rapport à une méthode centralisée similaire qui ne distribue pas le travail.
Ce que cela signifie pour les outils d’IA à venir
Pour les non-spécialistes, la conclusion est que de meilleures invites et des choix d’exemples plus intelligents peuvent améliorer sensiblement le comportement des systèmes d’IA — sans changer le modèle sous-jacent. AsynDBT offre un moyen automatisé et préservant la vie privée d’y parvenir à l’échelle de nombreux dispositifs collaboratifs, produisant des outils linguistiques plus précis et plus efficaces pour des domaines comme l’exploitation télécom, le support client et d’autres secteurs spécialisés. À l’avenir, les auteurs prévoient de combiner leur cadre avec une récupération de connaissances basée sur des graphes afin que les invites puissent également s’appuyer sur des informations factuelles à jour, réduisant encore les hallucinations et rendant les assistants IA plus dignes de confiance dans des contextes à enjeux élevés.
Citation: Ma, H., Dou, S., Liu, Y. et al. AsynDBT: asynchronous distributed bilevel tuning for efficient in-context learning with large language models. Sci Rep 16, 9381 (2026). https://doi.org/10.1038/s41598-026-39582-5
Mots-clés: apprentissage en contexte, optimisation de prompt, apprentissage fédéré, grands modèles de langage, IA préservant la vie privée